

Imagen de rawpixel.com en Freepik
El modelo de aprendizaje automático solo es útil si se usa en producción para resolver problemas comerciales. Sin embargo, el problema comercial y el modelo de aprendizaje automático están en constante evolución. Es por eso que necesitamos mantener el aprendizaje automático para que el rendimiento se mantenga al día con el KPI comercial. De ahí surgió el concepto de MLOps.
MLOps, u operaciones de aprendizaje automático, es una colección de técnicas y herramientas para el aprendizaje automático en producción. Desde la automatización del aprendizaje automático, el control de versiones, la entrega y el monitoreo es algo que manejan los MLOps. Este artículo se centrará en la supervisión y en cómo usamos los paquetes de Python para configurar el rendimiento del modelo de supervisión en producción. Entremos en ello.
Cuando hablamos de monitoreo en el MLOps, podría referirse a muchas cosas, ya que uno de los principios del MLOps es el monitoreo. Por ejemplo:
– Supervisar el cambio de distribución de datos a lo largo del tiempo
– Supervisar las funciones utilizadas en el desarrollo frente a la producción.
– Supervisar el deterioro del modelo
– Supervisar el rendimiento del modelo
– Supervisar la obsolescencia del sistema
Todavía hay muchos elementos para monitorear en MLOps, pero en este artículo, nos centraremos en monitorear el rendimiento del modelo. El rendimiento del modelo, en nuestro caso, se refiere a la capacidad del modelo para hacer predicciones confiables a partir de datos no vistos, medidos con métricas específicas como exactitud, precisión, recuperación, etc.
¿Por qué necesitamos monitorear el desempeño del modelo? Es para mantener la confiabilidad de la predicción del modelo para resolver el problema comercial. Antes de la producción, a menudo calculamos el rendimiento del modelo y su efecto en el KPI; por ejemplo, la línea de base es 70% de precisión si queremos que nuestro modelo siga las necesidades del negocio, pero por debajo de eso es inaceptable. Es por eso que monitorear el desempeño permitiría que el modelo siempre cumpla con los requisitos comerciales.
Usando Python, aprenderíamos cómo se realiza el monitoreo del modelo. Comencemos instalando el paquete. Hay muchas opciones para el monitoreo de modelos, pero para este ejemplo, usaríamos el paquete de código abierto para el monitoreo llamado evidentemente.
Primero, necesitamos instalar el paquete evidentemente con el siguiente código.
Después de instalar el paquete, descargaríamos el ejemplo de datos, los datos de reclamaciones de seguros de Kaggle. Además, limpiaríamos los datos antes de seguir usándolos.
import pandas as pd
df = pd.read_csv("insurance_claims.csv")
# Sort the data based on the Incident Data
df = df.sort_values(by="incident_date").reset_index(drop=True)
# Variable Selection
df = df[
[
"incident_date",
"months_as_customer",
"age",
"policy_deductable",
"policy_annual_premium",
"umbrella_limit",
"insured_sex",
"insured_relationship",
"capital-gains",
"capital-loss",
"incident_type",
"collision_type",
"total_claim_amount",
"injury_claim",
"property_claim",
"vehicle_claim",
"incident_severity",
"fraud_reported",
]
]
# Data Cleaning and One-Hot Encoding
df = pd.get_dummies(
df,
columns=[
"insured_sex",
"insured_relationship",
"incident_type",
"collision_type",
"incident_severity",
],
drop_first=True,
)
df["fraud_reported"] = df["fraud_reported"].apply(lambda x: 1 if x == "Y" else 0)
df = df.rename(columns={"incident_date": "timestamp", "fraud_reported": "target"})
for i in df.select_dtypes("number").columns:
df[i] = df[i].apply(float)
data = df[df["timestamp"] = "2015-02-20"].copy()
En el código anterior, seleccionamos algunas columnas con fines de entrenamiento del modelo, las transformamos en una representación numérica y dividimos los datos de referencia (data) y los datos actuales (val).
Necesitamos datos de referencia o de referencia en la canalización de MLOps para monitorear el rendimiento del modelo. Por lo general, son los datos separados de los datos de entrenamiento (por ejemplo, datos de prueba). Además, necesitamos los datos actuales o los datos no vistos por el modelo (datos entrantes).
Usemos evidentemente para monitorear los datos y el rendimiento del modelo. Debido a que la deriva de datos afectaría el rendimiento del modelo, también es algo que se considera monitorear.
from evidently.report import Report
from evidently.metric_preset import DataDriftPreset
data_drift_report = Report(metrics=[
DataDriftPreset(),
])
data_drift_report.run(current_data=val, reference_data=data, column_mapping=None)
data_drift_report.show(mode="inline")
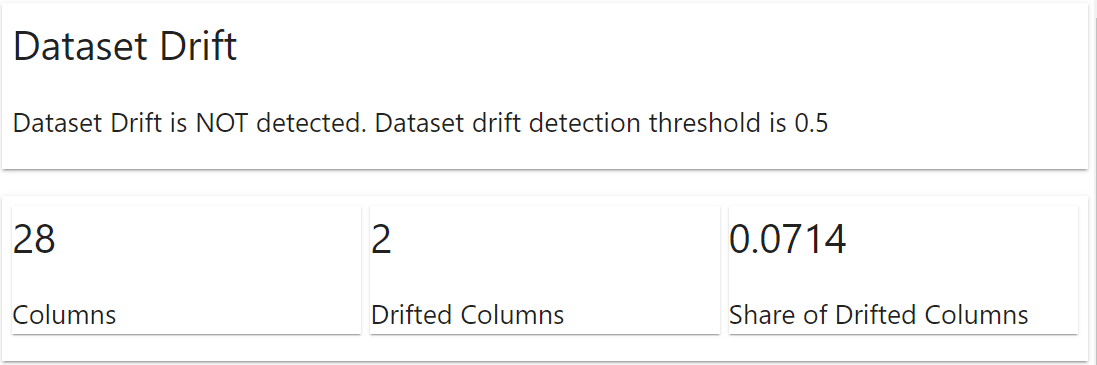
El paquete evidentemente mostraría automáticamente un informe sobre lo que sucedió con el conjunto de datos. La información incluye la deriva del conjunto de datos y la deriva de la columna. Para el ejemplo anterior, no tenemos ninguna desviación del conjunto de datos, pero dos columnas se desviaron.
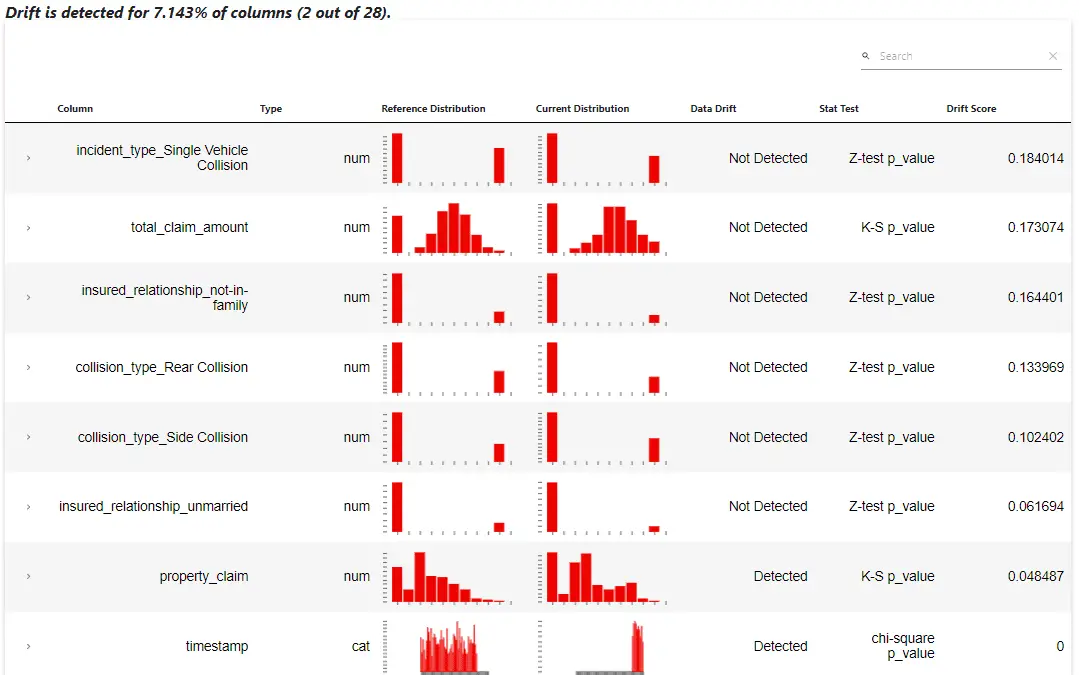
El informe muestra que la columna ‘property_claim’ y ‘timestamp’ tienen desviaciones detectadas. Esta información se puede usar en la canalización de MLOps para volver a entrenar el modelo, o aún necesitamos una exploración de datos adicional.
Si es necesario, también podemos adquirir el informe de datos anterior en el objeto de diccionario de registro.
data_drift_report.as_dict()
A continuación, intentemos entrenar un modelo clasificador a partir de los datos e intentemos usarlo evidentemente para monitorear el rendimiento del modelo.
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier()
rf.fit(data.drop(['target', 'timestamp'], axis = 1), data['target'])
Evidentemente, necesitaría las columnas objetivo y de predicción en la referencia y el conjunto de datos actual. Agreguemos la predicción del modelo al conjunto de datos y usemos evidentemente para monitorear el rendimiento.
data['prediction'] = rf.predict(data.drop(['target', 'timestamp'], axis = 1))
val['prediction'] = rf.predict(val.drop(['target', 'timestamp'], axis = 1))
Como nota, es mejor tener los datos de referencia que no son los datos de entrenamiento para los casos reales para monitorear el rendimiento del modelo. Configuremos la supervisión del rendimiento del modelo con el siguiente código.
from evidently.metric_preset import ClassificationPreset
classification_performance_report = Report(metrics=[
ClassificationPreset(),
])
classification_performance_report.run(reference_data=data, current_data=val)
classification_performance_report.show(mode="inline")
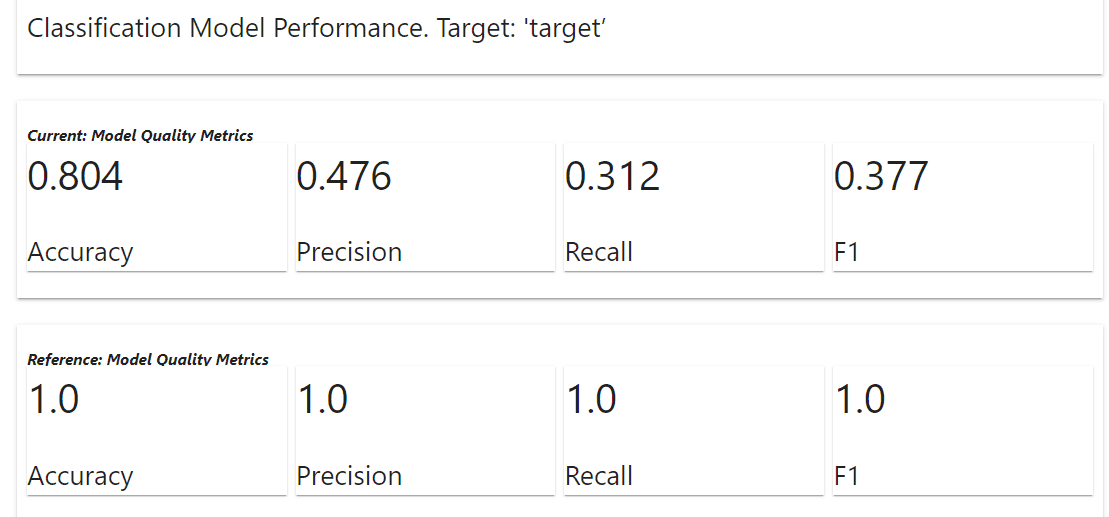
Como resultado, obtenemos que las métricas de calidad del modelo actual son más bajas que la referencia (lo esperado ya que usamos datos de entrenamiento para la referencia). Dependiendo de los requisitos comerciales, las métricas anteriores podrían convertirse en indicadores del próximo paso que debemos dar. Veamos la otra información que obtenemos del informe evidentemente.
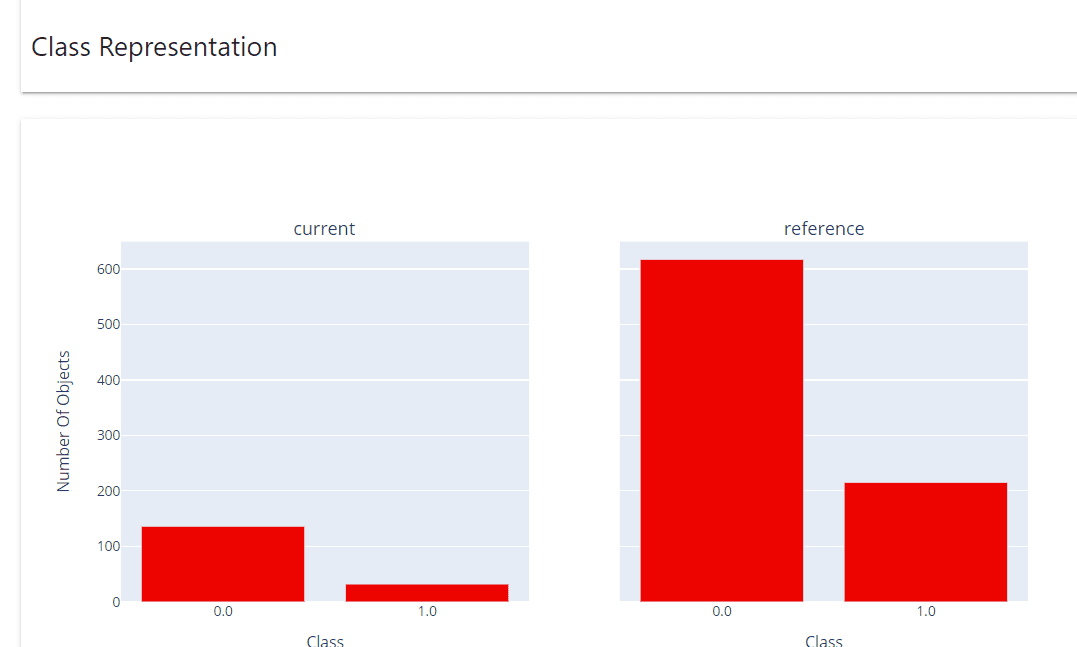
El informe Representación de clases muestra la distribución real de clases.
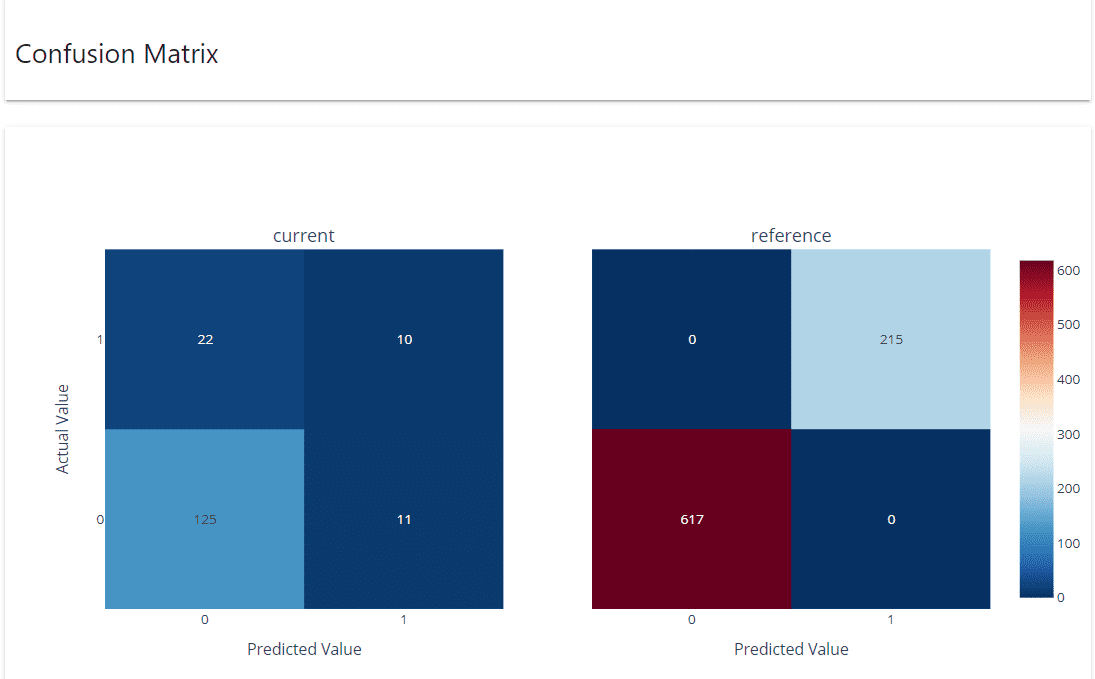
La matriz de confusión muestra cómo los valores de predicción se compararon con los datos reales tanto en los conjuntos de datos de referencia como en los actuales.
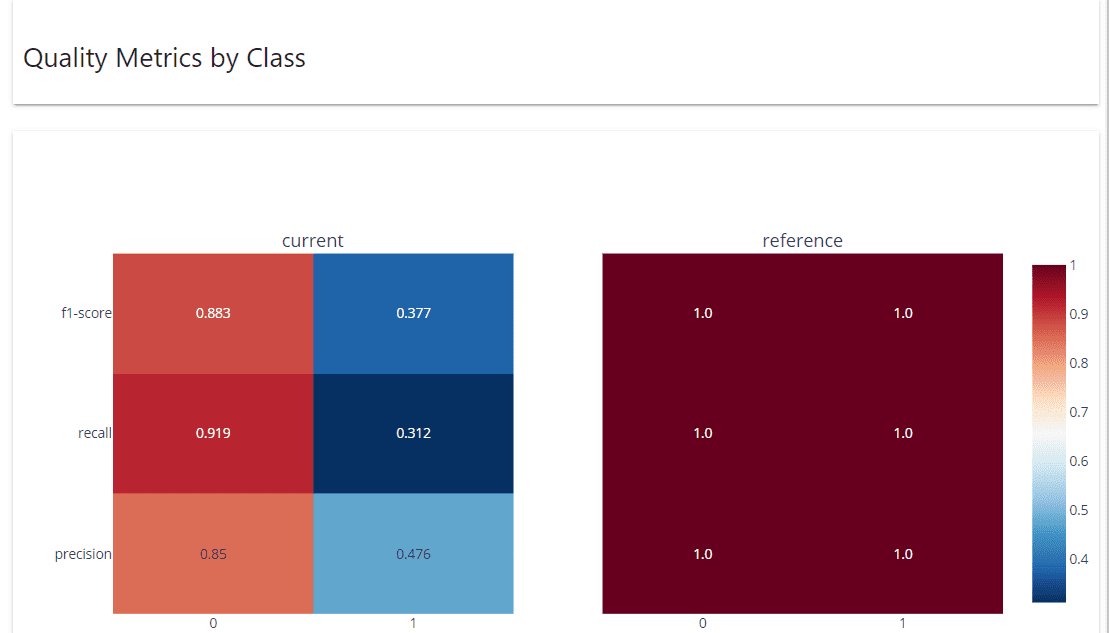
Las métricas de calidad por clase muestran el rendimiento de cada clase.
Como antes, podemos transformar el informe de rendimiento de clasificación en un registro de diccionario con el siguiente código.
classification_performance_report.as_dict()
Eso es todo por ahora. Puede configurar el monitor de rendimiento del modelo evidentemente en cualquier canalización de MLOps que tenga actualmente, y aún funcionaría maravillosamente.
El monitoreo del rendimiento del modelo es una tarea esencial en la canalización de MLOps, ya que es la que ayudaría a mantener cómo nuestro modelo se mantiene al día con los requisitos comerciales. Con un paquete de Python llamado evidentemente, podemos configurar fácilmente el monitor de rendimiento del modelo, que se puede integrar en cualquier canalización de MLOps existente.
Cornelio Yudha Wijaya es subgerente de ciencia de datos y escritor de datos. Mientras trabaja a tiempo completo en Allianz Indonesia, le encanta compartir consejos sobre Python y datos a través de las redes sociales y los medios de escritura.