
Las predicciones a largo plazo de (arriba) Transformador de trayectoria en comparación con los de (abajo) a un solo paso modelo de dinámica.
Las historias de éxito del aprendizaje automático moderno a menudo tienen una cosa en común: utilizan métodos que se escalan elegantemente con cantidades de datos cada vez mayores. Esto es particularmente claro en los avances recientes en el modelado de secuencias, donde simplemente aumentar el tamaño de una arquitectura estable y su conjunto de entrenamiento conduce a capacidades cualitativamente diferentes.
Mientras tanto, la situación del aprendizaje por refuerzo se ha vuelto más complicada. Si bien ha sido posible aplicar algoritmos de aprendizaje por refuerzo a problemas a gran escala, en general ha habido mucha más fricción al hacerlo. En esta publicación, exploramos si podemos aliviar estas dificultades abordando el problema del aprendizaje por refuerzo con la caja de herramientas del modelado de secuencias. El resultado final es un modelo generativo de trayectorias que parece un modelo de lenguaje grande y un algoritmo de planificación que parece una búsqueda de haz. El código para el enfoque se puede encontrar aquí.
El transformador de trayectoria
El marco estándar del aprendizaje por refuerzo se centra en descomponer un problema complicado de horizonte largo en subproblemas más pequeños y manejables, lo que lleva a métodos de programación dinámica como el aprendizaje $ Q $ y un énfasis en los modelos dinámicos de Markov. Sin embargo, también podemos ver el aprendizaje por refuerzo como análogo a un problema de generación de secuencias, con el objetivo de producir una secuencia de acciones que, cuando se ejecutan en un entorno, producirán una secuencia de grandes recompensas.
Llevando este punto de vista a su conclusión lógica, comenzamos modelando los datos de trayectoria proporcionados a los algoritmos de aprendizaje por refuerzo con una arquitectura Transformer, la herramienta de elección actual para el modelado de lenguaje natural. Tratamos estas trayectorias como secuencias no estructuradas de estados, acciones y recompensas discretizados, y entrenamos la arquitectura del transformador utilizando la pérdida de entropía cruzada estándar. Modelar todos los datos de trayectoria con un único modelo de alta capacidad y un objetivo de entrenamiento escalable, en lugar de procedimientos separados para modelos dinámicos, políticas y funciones de $ Q $, permite un enfoque más simplificado que elimina gran parte de la complejidad habitual.
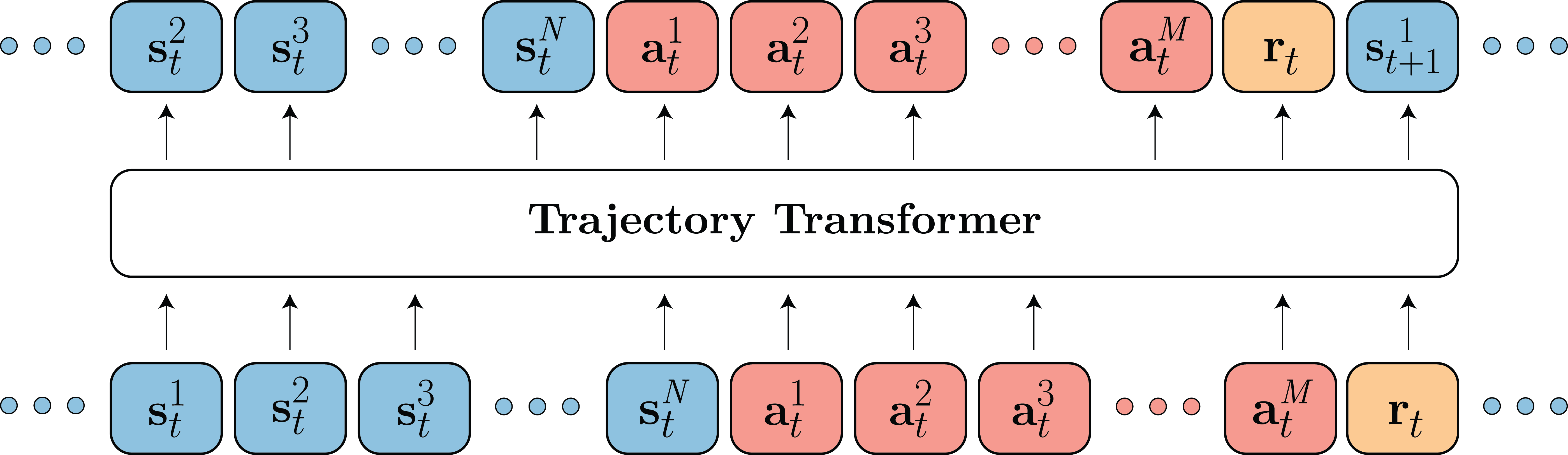
Modelamos la distribución sobre $ N $ estados dimensionales $ mathbf {s} _t $, $ M $ acciones dimensionales $ mathbf {a} _t $, y recompensas escalares $ r_t $ usando una arquitectura Transformer.
Transformadores como modelos dinámicos
En muchos métodos de aprendizaje por refuerzo basados en modelos, los errores de predicción compuestos hacen que los despliegues de horizonte largo sean demasiado poco fiables para usarlos para el control, lo que requiere una planificación de horizonte corto o combinaciones de estilo Dyna de predicciones de modelos truncadas y funciones de valor. En comparación, encontramos que el Transformador de trayectoria es un predictor de horizonte largo sustancialmente más preciso que los modelos dinámicos convencionales de un solo paso.
Mientras que el modelo de un solo paso adolece de errores compuestos que hacen que sus predicciones a largo plazo sean físicamente inverosímiles, las predicciones del Transformador de trayectoria siguen siendo visualmente indistinguibles de los despliegues en el entorno de referencia.
Este resultado es emocionante porque la planificación con modelos aprendidos es notoriamente meticulosa, y los modelos de dinámica de redes neuronales a menudo son demasiado inexactos para beneficiarse de rutinas de planificación más sofisticadas. Un modelo predictivo de mayor calidad como el Transformador de trayectoria abre la puerta a la importación de optimizadores de trayectoria efectivos que anteriormente solo habrían servido para explotar el modelo aprendido.
También podemos inspeccionar el Transformador de trayectoria como si fuera un modelo de lenguaje estándar. Una estrategia común en la traducción automática, por ejemplo, es visualizar los pesos de los tokens intermedios como un proxy para las dependencias de los tokens. La misma visualización aplicada aquí revela dos patrones destacados:
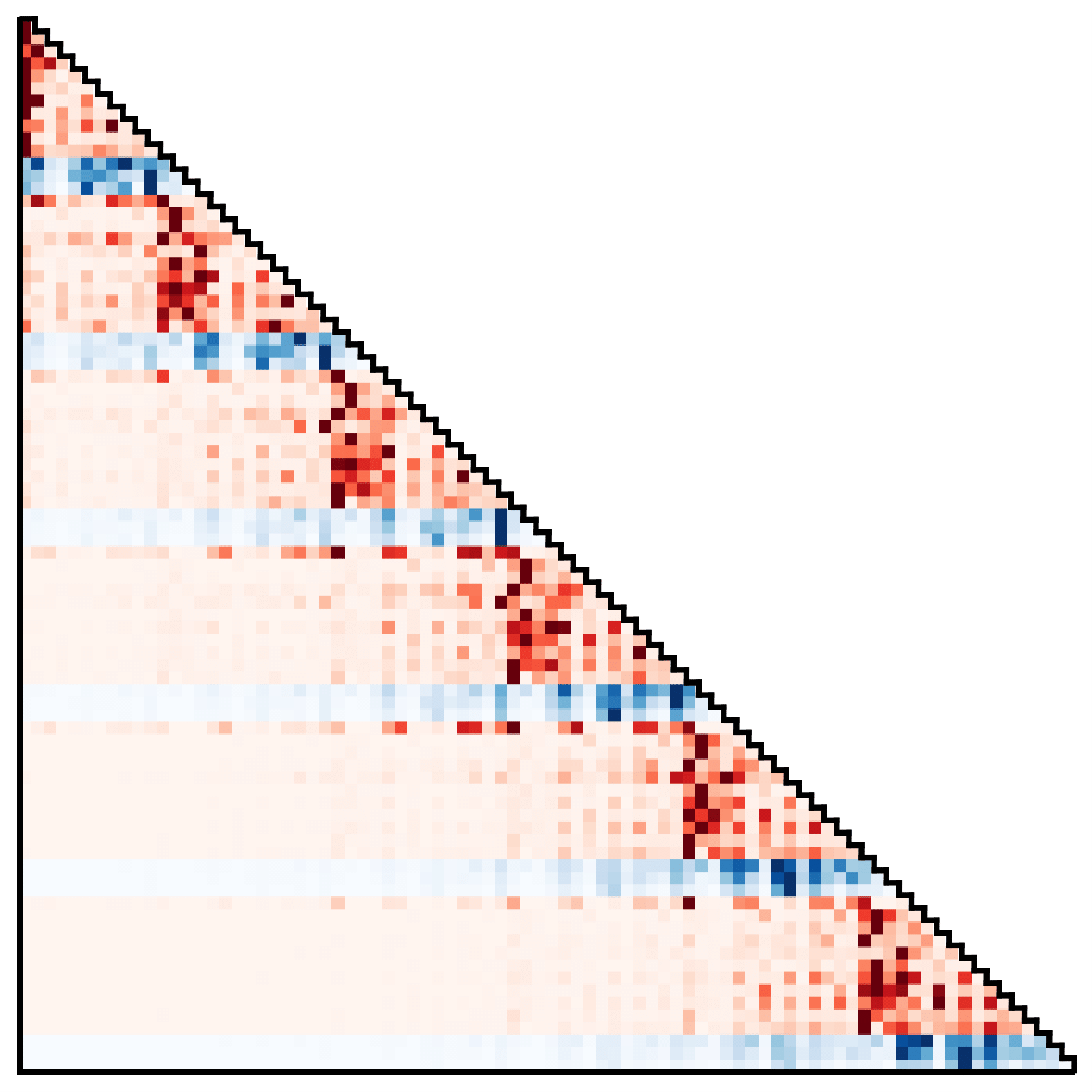
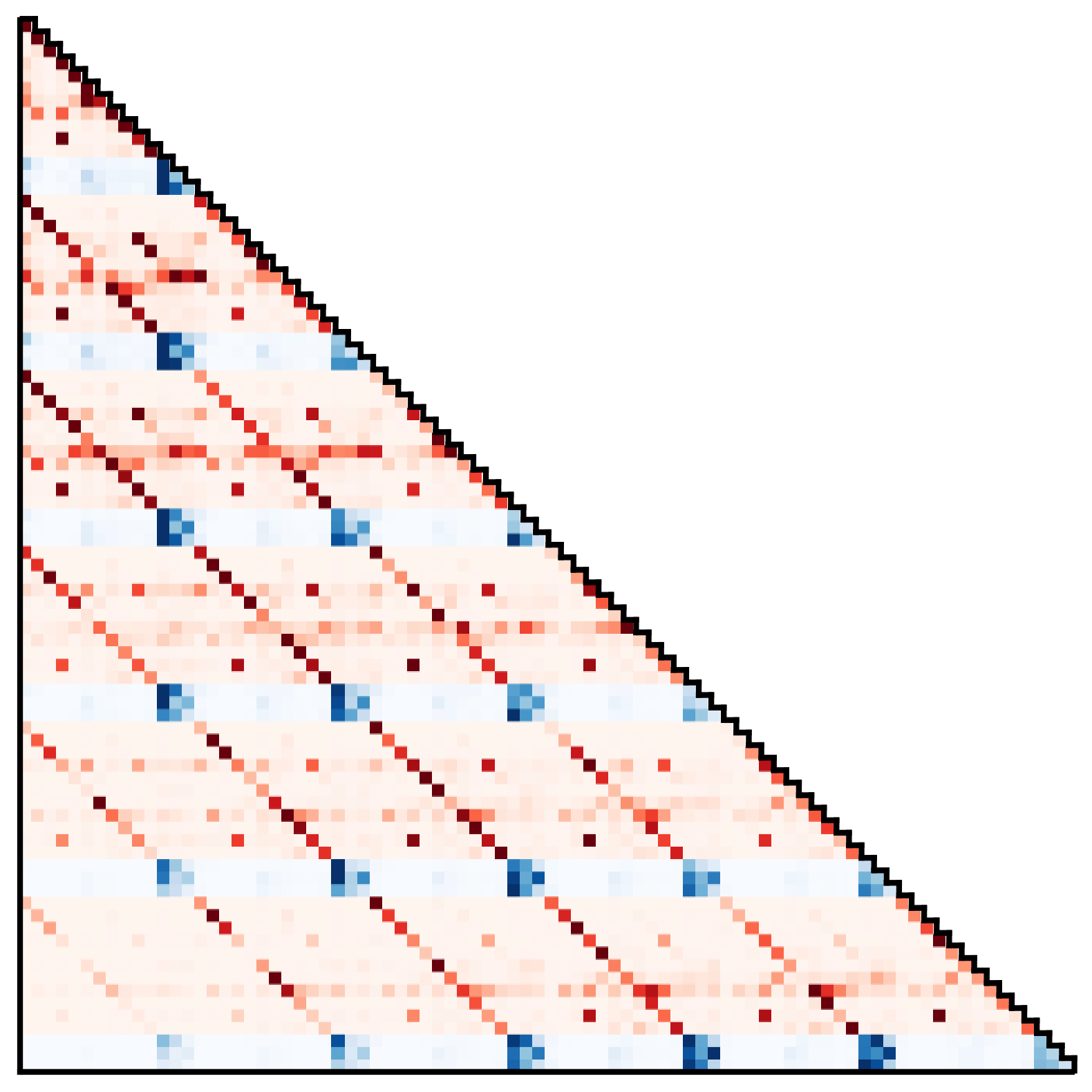
Patrones de atención del Transformador de trayectoria, que muestran (izquierda) un descubrimiento Estrategia de Markov y (derecha) un acercamiento con acción suavizante.
En el primero, las predicciones de estado y acción dependen principalmente de la transición inmediatamente anterior, que se asemeja a una propiedad de Markov aprendida. En el segundo, las predicciones de la dimensión de estado dependen más fuertemente de las dimensiones correspondientes de todos los estados anteriores, y las dimensiones de acción dependen principalmente de todas las acciones anteriores. Si bien la segunda dependencia viola la intuición habitual de que las acciones son una función del estado anterior en las políticas de clonación de comportamiento, esto recuerda al suavizado de acciones utilizado en algunos algoritmos de optimización de trayectorias para imponer secuencias de control que varían lentamente.
Beam search como optimizador de trayectoria
La rutina de control predictivo de modelos más simple se compone de tres pasos: (1) usar un modelo para buscar una secuencia de acciones que conduzcan a un resultado deseado; (2) promulgando el primero de estas acciones en el entorno real; y (3) estimar el nuevo estado del medio ambiente para comenzar el paso (1) nuevamente. Una vez que se ha elegido (o entrenado) un modelo, la mayoría de las decisiones de diseño importantes se encuentran en el primer paso de ese ciclo, con diferencias en las estrategias de búsqueda de acciones que conducen a una amplia gama de algoritmos de optimización de trayectorias.
Continuando con el tema de extraer del kit de herramientas de modelado de secuencias para abordar los problemas de aprendizaje por refuerzo, nos preguntamos si la técnica de referencia para decodificar modelos de lenguaje neuronal también puede servir como un optimizador de trayectoria eficaz. Esta técnica, conocida como búsqueda de haz, es un algoritmo de búsqueda podado en amplitud que ha encontrado un uso notablemente consistente desde los primeros días de la lingüística computacional. Exploramos variaciones de la búsqueda de vigas y creamos su uso en un planificador basado en modelos en tres configuraciones diferentes:
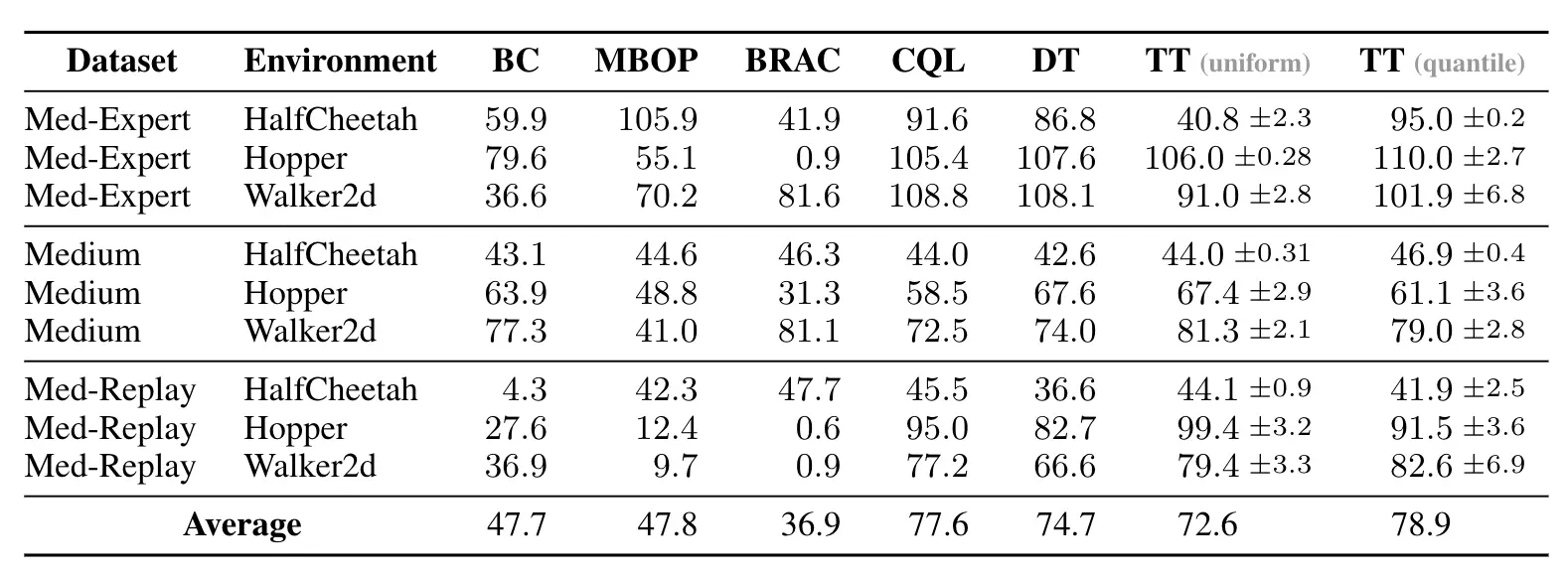
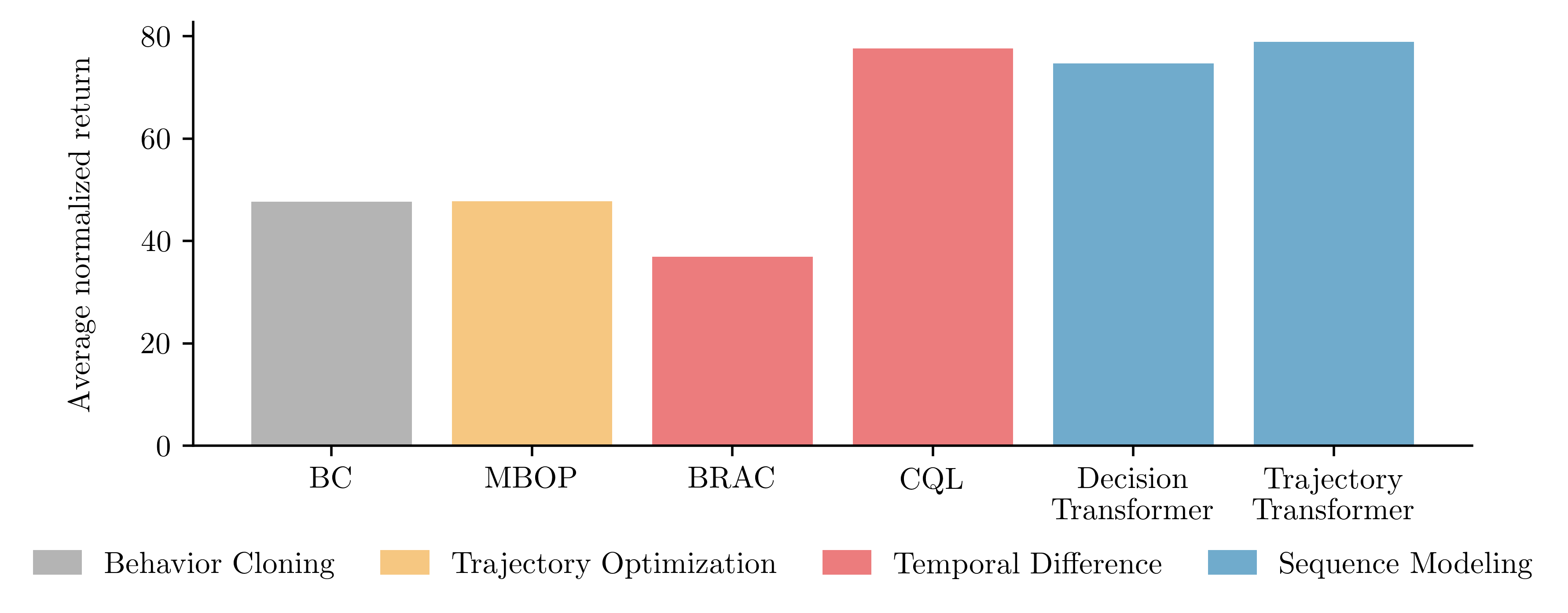
Rendimiento en los entornos de locomoción en la suite de referencia fuera de línea D4RL. Comparamos dos variantes del Transformador de trayectoria (TT), que se diferencian en cómo discretizan las entradas continuas, con algoritmos de modelado de secuencia propuestos recientemente y basados en modelos, basados en valores.
¿Qué significa esto para el aprendizaje por refuerzo?
Trajectory Transformer es una especie de ejercicio de minimalismo. A pesar de carecer de la mayoría de los ingredientes comunes de un algoritmo de aprendizaje por refuerzo, funciona a la par con los enfoques que han sido el resultado de mucho esfuerzo y ajuste colectivos. Tomado junto con el Transformador de decisiones concurrente, este resultado destaca que las arquitecturas escalables y los objetivos de entrenamiento estables pueden eludir algunas de las dificultades del aprendizaje por refuerzo en la práctica.
Sin embargo, la simplicidad del enfoque propuesto le da debilidades predecibles. Debido a que el Transformer se entrena con un objetivo de máxima verosimilitud, depende más de la distribución de entrenamiento que un algoritmo de programación dinámica convencional. Aunque es valioso estudiar los enfoques más simplificados que pueden abordar los problemas de aprendizaje por refuerzo, es posible que la instanciación más eficaz de este marco provenga de combinaciones de las cajas de herramientas de modelado de secuencias y aprendizaje por refuerzo.
Podemos obtener una vista previa de cómo funcionaría esto con una combinación bastante sencilla: planifique usando el Transformador de trayectoria como antes, pero use una función $ Q $ entrenada mediante programación dinámica como una heurística de búsqueda para guiar el procedimiento de planificación de búsqueda de haz. Es de esperar que esto sea importante en tareas de horizonte largo y de recompensa escasa, ya que plantean problemas de búsqueda particularmente difíciles. Para ejemplificar esta idea, usamos la función $ Q $ del algoritmo implícito de aprendizaje $ Q $ (IQL) y dejamos el Transformador de trayectoria sin modificar. Denotamos la combinación TT$ _ { color {# 999999} {(+ Q)}} $:
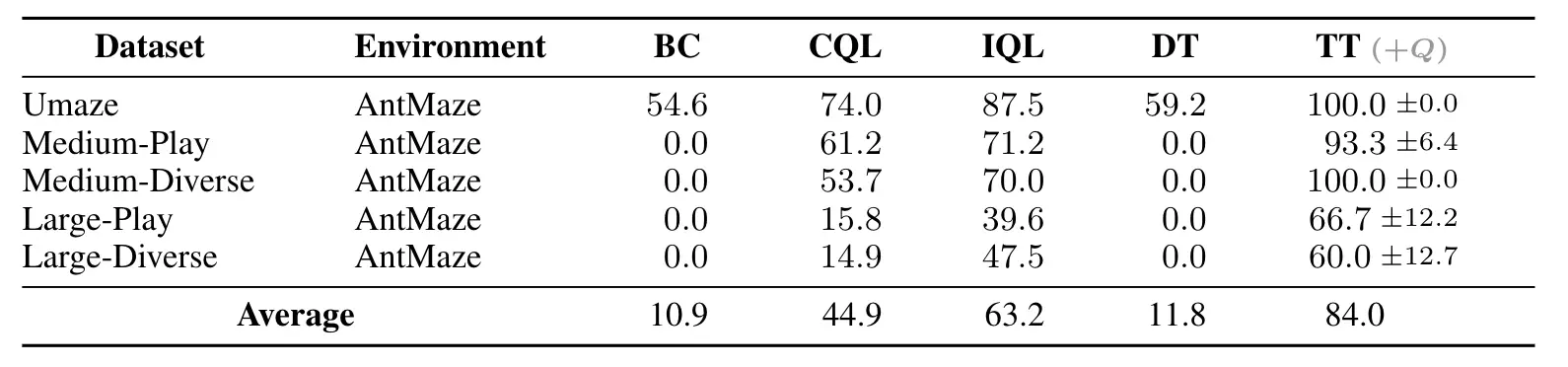
Guiar los planes del Transformador de trayectoria con una función $ Q $ entrenada mediante programación dinámica (TT $ _ { color {# 999999} {(+ Q)}} $) es una forma sencilla de mejorar el rendimiento empírico en comparación con el modelo sin modelo ( Enfoques CQL, IQL) y condicionamiento de retorno (DT). Evaluamos este efecto en las tareas de logro de objetivos de AntMaze de horizonte largo y recompensa escasa.
Debido a que el procedimiento de planificación solo usa la función $ Q $ como una forma de filtrar secuencias prometedoras, no es tan propenso a imprecisiones locales en las predicciones de valor como los métodos basados en extracción de políticas como CQL e IQL. Sin embargo, todavía se beneficia de la composicionalidad temporal de la programación y la planificación dinámicas, por lo que supera a los enfoques de condicionamiento del retorno que se basan más en demostraciones completas.
La planificación con una función de valor terminal es una estrategia probada en el tiempo, por lo que la búsqueda de haces guiada por $ Q $ es posiblemente la forma más sencilla de combinar el modelado de secuencias con el aprendizaje por refuerzo convencional. Este resultado es alentador no porque sea nuevo algorítmicamente, sino porque demuestra los beneficios empíricos que pueden aportar incluso las combinaciones sencillas. Es posible que diseñar un modelo de secuencia desde cero para este propósito, a fin de retener la escalabilidad de Transformers mientras se incorporan los principios de programación dinámica, sea una forma aún más efectiva de aprovechar las fortalezas de cada juego de herramientas.
Esta publicación se basa en el siguiente documento: