
Figura 1: comportamiento paso a paso en el aprendizaje autosupervisado. Al entrenar algoritmos SSL comunes, encontramos que la pérdida desciende de forma escalonada (arriba a la izquierda) y las incrustaciones aprendidas aumentan iterativamente en dimensionalidad (abajo a la izquierda). La visualización directa de incrustaciones (a la derecha; se muestran las tres direcciones PCA superiores) confirma que las incrustaciones se colapsan inicialmente en un punto, que luego se expande a una variedad 1D, una variedad 2D y más allá simultáneamente con pasos en la pérdida.
Se cree ampliamente que el sorprendente éxito del aprendizaje profundo se debe en parte a su capacidad para descubrir y extraer representaciones útiles de datos complejos. El aprendizaje autosupervisado (SSL) se ha convertido en un marco líder para aprender estas representaciones de imágenes directamente a partir de datos no etiquetados, de forma similar a cómo los LLM aprenden representaciones de lenguaje directamente a partir de texto extraído de la web. Sin embargo, a pesar del papel clave de SSL en modelos de última generación como CLIP y MidJourney, preguntas fundamentales como «¿qué están aprendiendo realmente los sistemas de imágenes autosupervisados?» y “¿cómo ocurre realmente ese aprendizaje?” carecen de respuestas básicas.
Nuestro documento reciente (que aparecerá en ICML 2023) presenta lo que sugerimos es la primera imagen matemática convincente del proceso de entrenamiento de los métodos SSL a gran escala. Nuestro modelo teórico simplificado, que resolvemos exactamente, aprende aspectos de los datos en una serie de pasos discretos y bien separados. Luego demostramos que este comportamiento se puede observar en la naturaleza en muchos sistemas actuales de última generación. Este descubrimiento abre nuevas vías para mejorar los métodos SSL y permite una amplia gama de nuevas preguntas científicas que, cuando se respondan, proporcionarán una lente poderosa para comprender algunos de los sistemas de aprendizaje profundo más importantes de la actualidad.
Fondo
Nos enfocamos aquí en métodos SSL de incrustación conjunta, un superconjunto de métodos contrastivos, que aprenden representaciones que obedecen a criterios de invariancia de vista. La función de pérdida de estos modelos incluye un término que impone incrustaciones coincidentes para «vistas» semánticamente equivalentes de una imagen. Sorprendentemente, este enfoque simple produce representaciones poderosas en tareas de imagen, incluso cuando las vistas son tan simples como recortes aleatorios y perturbaciones de color.
Teoría: aprendizaje paso a paso en SSL con modelos linealizados
Primero describimos un modelo lineal exactamente solucionable de SSL en el que tanto las trayectorias de entrenamiento como las incrustaciones finales se pueden escribir en forma cerrada. En particular, encontramos que el aprendizaje de representación se separa en una serie de pasos discretos: el rango de las incrustaciones comienza pequeño y aumenta iterativamente en un proceso de aprendizaje por pasos.
La principal contribución teórica de nuestro artículo es resolver exactamente la dinámica de entrenamiento de la función de pérdida de los Gemelos de Barlow bajo flujo gradiente para el caso especial de un modelo lineal \(\mathbf{f}(\mathbf{x}) = \mathbf{W } \mathbf{x}\). Para esbozar nuestros hallazgos aquí, encontramos que, cuando la inicialización es pequeña, el modelo aprende representaciones compuestas precisamente de las direcciones propias superior-\(d\) del característicamente matriz de correlación cruzada \(\boldsymbol{\Gamma} \equiv \mathbb{E}_{\mathbf{x},\mathbf{x}’} [ \mathbf{x} \mathbf{x}’^T ]\). Además, encontramos que estas direcciones propias se aprenden uno a la vez en una secuencia de pasos de aprendizaje discretos en momentos determinados por sus valores propios correspondientes. La Figura 2 ilustra este proceso de aprendizaje, mostrando tanto el crecimiento de una nueva dirección en la función representada como la caída resultante en la pérdida en cada paso de aprendizaje. Como bono adicional, encontramos una ecuación de forma cerrada para las incrustaciones finales aprendidas por el modelo en la convergencia.
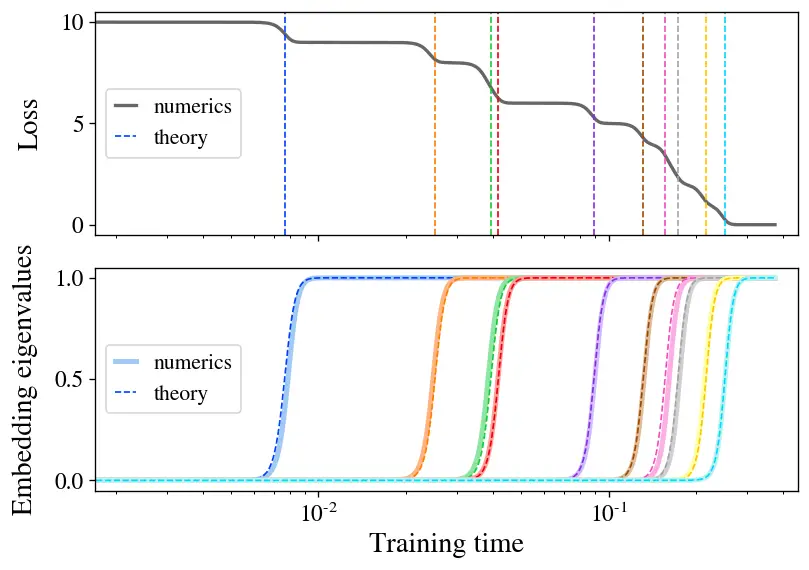
Figura 2: el aprendizaje paso a paso aparece en un modelo lineal de SSL. Entrenamos un modelo lineal con la pérdida de Barlow Twins en una pequeña muestra de CIFAR-10. La pérdida (arriba) desciende en forma de escalera, con tiempos de paso bien predichos por nuestra teoría (líneas discontinuas). Los valores propios incorporados (abajo) surgen uno a la vez, coincidiendo estrechamente con la teoría (curvas discontinuas).
Nuestro hallazgo del aprendizaje paso a paso es una manifestación del concepto más amplio de sesgo espectral, que es la observación de que muchos sistemas de aprendizaje con dinámica aproximadamente lineal aprenden preferentemente direcciones propias con valores propios más altos. Esto ha sido bien estudiado recientemente en el caso del aprendizaje supervisado estándar, donde se ha encontrado que los modos propios con valores propios más altos se aprenden más rápido durante el entrenamiento. Nuestro trabajo encuentra los resultados análogos para SSL.
La razón por la que un modelo lineal amerita un estudio cuidadoso es que, como se muestra a través de la línea de trabajo del «núcleo tangente neuronal» (NTK), las redes neuronales suficientemente amplias también tienen dinámicas de parámetros lineales. Este hecho es suficiente para extender nuestra solución para un modelo lineal a redes neuronales amplias (o, de hecho, a máquinas kernel arbitrarias), en cuyo caso el modelo preferentemente aprende las direcciones propias superiores \(d\) de un operador particular relacionado con el NTK. El estudio de la NTK ha arrojado muchas ideas sobre el entrenamiento y la generalización de redes neuronales incluso no lineales, lo cual es una pista de que tal vez algunas de las ideas que hemos recopilado podrían transferirse a casos realistas.
Experimento: aprendizaje paso a paso en SSL con ResNets
Como nuestros principales experimentos, entrenamos varios métodos SSL líderes con codificadores ResNet-50 a gran escala y descubrimos que, sorprendentemente, vemos claramente este patrón de aprendizaje por pasos incluso en entornos realistas, lo que sugiere que este comportamiento es fundamental para el comportamiento de aprendizaje de SSL.
Para ver el aprendizaje paso a paso con ResNets en configuraciones realistas, todo lo que tenemos que hacer es ejecutar el algoritmo y rastrear los valores propios de la matriz de covarianza incrustada a lo largo del tiempo. En la práctica, ayuda a resaltar el comportamiento paso a paso entrenar también a partir de una inicialización de parámetros más pequeña de lo normal y entrenar con una tasa de aprendizaje pequeña, por lo que usaremos estas modificaciones en los experimentos de los que hablamos aquí y discutiremos el caso estándar en nuestro papel.
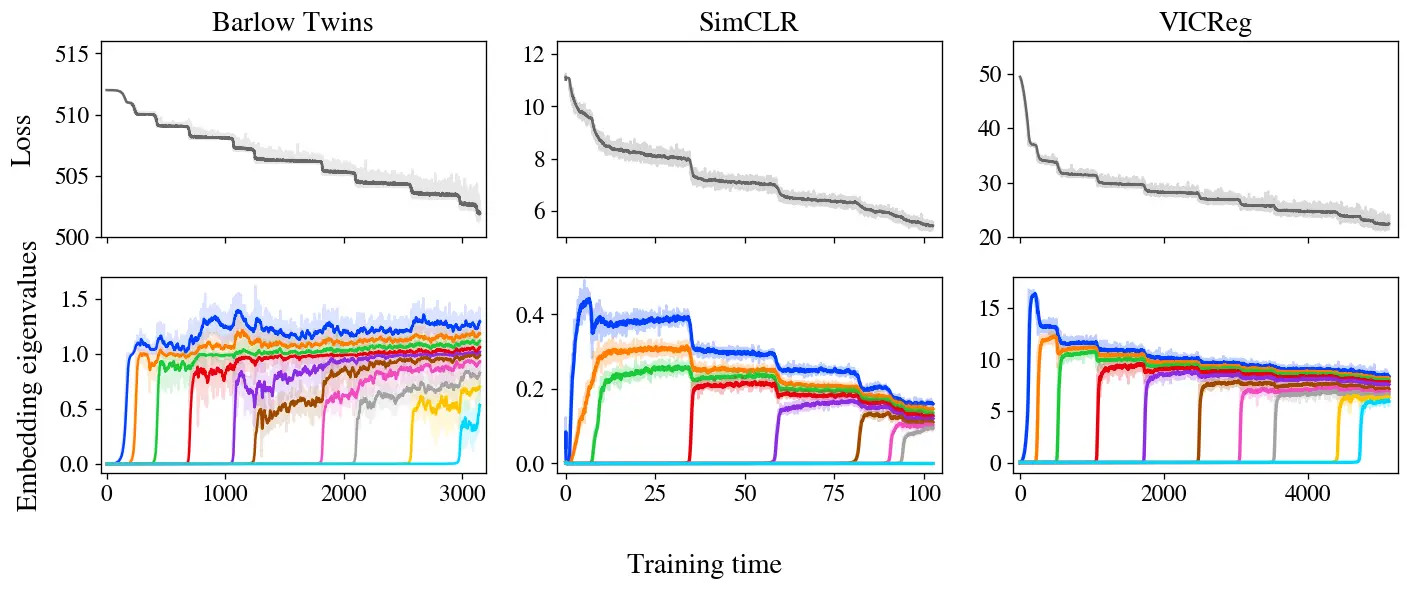
Figura 3: el aprendizaje paso a paso es evidente en Barlow Twins, SimCLR y VICReg. La pérdida y las incrustaciones de los tres métodos muestran un aprendizaje gradual, con incrustaciones que aumentan de rango iterativamente según lo predicho por nuestro modelo.
La Figura 3 muestra las pérdidas y los valores propios de covarianza incorporados para tres métodos SSL (Barlow Twins, SimCLR y VICReg) entrenados en el conjunto de datos STL-10 con aumentos estándar. Notablemente, los tres muestran un aprendizaje paso a paso muy claro, con pérdida decreciente en una curva de escalera y un nuevo valor propio brotando de cero en cada paso subsiguiente. También mostramos un acercamiento animado a los primeros pasos de Barlow Twins en la Figura 1.
Vale la pena señalar que, si bien estos tres métodos son bastante diferentes a primera vista, durante algún tiempo se sospecha en el folclore que están haciendo algo similar debajo del capó. En particular, estos y otros métodos SSL de incrustación conjunta logran un rendimiento similar en las tareas de referencia. El desafío, entonces, es identificar el comportamiento compartido que subyace a estos métodos variados. Gran parte del trabajo teórico anterior se ha centrado en las similitudes analíticas en sus funciones de pérdida, pero nuestros experimentos sugieren un principio unificador diferente: Todos los métodos SSL aprenden incorporaciones una dimensión a la vez, agregando iterativamente nuevas dimensiones en orden de prominencia.
En un último experimento incipiente pero prometedor, comparamos las incrustaciones reales aprendidas por estos métodos con las predicciones teóricas calculadas a partir del NTK después del entrenamiento. No solo encontramos un buen acuerdo entre la teoría y el experimento dentro de cada método, sino que también comparamos entre métodos y descubrimos que diferentes métodos aprenden incrustaciones similares, lo que agrega apoyo adicional a la noción de que estos métodos, en última instancia, están haciendo cosas similares y pueden unificarse.
por qué importa
Nuestro trabajo pinta una imagen teórica básica del proceso mediante el cual los métodos SSL ensamblan representaciones aprendidas en el transcurso del entrenamiento. Ahora que tenemos una teoría, ¿qué podemos hacer con ella? Vemos que esta imagen es prometedora tanto para ayudar a la práctica de SSL desde el punto de vista de la ingeniería como para permitir una mejor comprensión de SSL y potencialmente el aprendizaje de representación de manera más amplia.
En el aspecto práctico, se sabe que los modelos SSL son lentos para entrenar en comparación con el entrenamiento supervisado, y se desconoce el motivo de esta diferencia. Nuestra imagen del entrenamiento sugiere que el entrenamiento SSL tarda mucho en converger porque los modos propios posteriores tienen constantes de tiempo largas y tardan mucho tiempo en crecer significativamente. Si esa imagen es correcta, acelerar el entrenamiento sería tan simple como enfocar selectivamente el gradiente en pequeñas direcciones propias incrustadas en un intento de llevarlas al nivel de las demás, lo que se puede hacer en principio con solo una simple modificación de la función de pérdida o el optimizador Discutimos estas posibilidades con más detalle en nuestro artículo.
Desde el punto de vista científico, el marco de SSL como un proceso iterativo permite hacer muchas preguntas sobre los modos propios individuales. ¿Son más útiles las que se aprenden primero que las que se aprenden después? ¿Cómo cambian los diferentes aumentos los modos aprendidos? ¿Depende esto del método SSL específico utilizado? ¿Podemos asignar contenido semántico a cualquier (subconjunto de) modos propios? (Por ejemplo, hemos notado que los primeros modos aprendidos a veces representan funciones altamente interpretables como el tono y la saturación promedio de una imagen). Si otras formas de aprendizaje de representación convergen en representaciones similares, un hecho que es fácilmente comprobable, entonces las respuestas a estas las preguntas pueden tener implicaciones que se extienden al aprendizaje profundo de manera más amplia.
Considerándolo todo, somos optimistas acerca de las perspectivas de trabajo futuro en el área. El aprendizaje profundo sigue siendo un gran misterio teórico, pero creemos que nuestros hallazgos aquí brindan un punto de apoyo útil para futuros estudios sobre el comportamiento de aprendizaje de las redes profundas.
Esta publicación se basa en el documento «Sobre la naturaleza gradual del aprendizaje autosupervisado», que es un trabajo conjunto con Maksis Knutins, Liu Ziyin, Daniel Geisz y Joshua Albrecht. Este trabajo se llevó a cabo con Generalmente Inteligente, donde Jamie Simon es investigador. Esta publicación de blog se publica aquí. Estaremos encantados de responder a sus preguntas o comentarios.
