

En la era actual de la inteligencia artificial, los modelos de lenguaje se han convertido en un tema candente. Estos representan una innovación de gran alcance en el campo de la IA y se utilizan ampliamente en diversas aplicaciones y tecnologías.
Se han vuelto fundamentales en el desarrollo de sistemas de procesamiento de voz y texto, así como en la interacción hombre-máquina. Su capacidad para comprender y generar un lenguaje similar al humano ha transformado la forma en que las personas se comunican y usan la tecnología en su vida diaria.
estos modelos han experimentado un crecimiento impresionante en términos de rendimiento y aplicabilidad. Su uso se ha expandido a campos como la traducción automática, el reconocimiento de voz o la generación de texto e imágenes.
Sin embargo, junto con su crecimiento y aplicaciones, También surgen desafíos y consideraciones éticas en torno a los modelos lingüísticos. La necesidad de abordar el sesgo en el idioma, la privacidad de los datos y las implicaciones sociales de estas tecnologías es cada vez más importante.
¿Qué es un modelo de lenguaje?
Un modelo de lenguaje es un tipo de modelo estadístico o computacional que Se utiliza para comprender y generar texto en lenguaje natural. Esto utiliza el aprendizaje automático o Aprendizaje automático para realizar una distribución de probabilidad de las palabras utilizadas para predecir la siguiente palabra más probable en una oración basada en la entrada anterior.
Para entenderlo mejor, un modelo de lenguaje es como una “máquina” inteligente que aprende a comprender y generar texto como lo hacemos los humanos. Puede considerarlo como un asistente virtual o una aplicación en su teléfono móvil que puede hablar y escribir de forma natural.
Este modelo está entrenado usando grandes cantidades de texto para aprender cómo funcionan las palabras en conversaciones, creación de historias y muchos otros casos.
Por ejemplo, imagina que estás escribiendo un mensaje de texto en tu móvil y empiezas a escribir “Hola, ¿cómo estás…?”. Tu móvil, gracias al modelo de lenguaje, puede predecir que probablemente quieras escribir “Hola, ¿cómo estás?”. Esto se debe a que el modelo ha analizado millones de conversaciones y ha aprendido qué palabras tienden a seguir a otras.
El modelo de lenguaje también puede generar texto de forma autónoma. Por ejemplo, si le asigna un eslogan como «Había una vez en una tierra muy, muy lejana», el modelo podría generar una historia completa basada en ese eslogan. Esto es posible porque ha aprendido las estructuras y patrones del lenguaje de los textos con los que fue entrenado.
Dos enfoques principales en lo que respecta al modelado del lenguaje
Hay varios tipos de modelos de lenguaje, pero en términos generales, Se pueden clasificar en 2 categorías principales: modelos de lenguaje basados en reglas y modelos de lenguaje estadísticos o de aprendizaje automático.
Modelos de lenguaje basados en reglas
Estos modelos utilizan reglas y estructuras gramaticales predefinidas para comprender y generar texto. Se basan en un conjunto de reglas gramaticales y semánticas diseñadas manualmente por lingüistas y expertos en idiomas.
Estas reglas definen la sintaxis y la semántica del lenguaje en cuestión. Los modelos de lenguaje basados en reglas son más comunes en los sistemas de procesamiento de lenguaje natural más antiguos y están limitados por la complejidad de definir todas las reglas necesarias para un lenguaje completo.

El problema de este tipo de modelos es que puede ser un proceso muy laborioso y complejo. Además, pueden tener dificultades para manejar la ambigüedad y las variaciones en el lenguaje, ya que no pueden adaptarse automáticamente a nuevas situaciones o aprender de datos no incluidos en las reglas predefinidas.
Modelos de lenguaje probabilístico o de aprendizaje automático (‘Machine Learning’)
Estos modelos se basan en la análisis estadístico de grandes cantidades de texto para aprender las propiedades y patrones del lenguaje. Pueden usar diferentes enfoques, como modelos de n-gramas, redes neuronales recurrentes (RNN) y modelos transformadorentre otros.
Los modelos de n-gramas para una mejor comprensión son un tipo de modelo de lenguaje que ayuda a predecir qué palabras tienen más probabilidades de aparecer después de otras en un texto. Imagina que estás leyendo una oración y quieres adivinar la siguiente palabra. Un modelo de n-grama te ayuda a hacer esa predicción.

La idea principal detrás de esto es que la probabilidad de que una palabra aparezca en un contexto dado depende de las palabras que la preceden. Por ejemplo, si las dos últimas palabras de una oración son «Estoy feliz», es más probable que la siguiente palabra sea «ahora» o «porque» en lugar de «perro» o «sol».
Las redes neuronales recurrentes (RNN) son una mejora en este tema. Dado que los RNN pueden ser una red basada en celdas de memoria a corto plazo (LSTM) o una unidad recursiva cerrada (GRU), tienen en cuenta todas las palabras anteriores al elegir la siguiente palabra.
El principal inconveniente de las arquitecturas basadas en RNN se deriva de su naturaleza secuencial y memoria a corto plazo. En consecuencia, los tiempos de entrenamiento se disparan para secuencias largas porque no hay posibilidad de paralelización. La solución a este problema es la arquitectura del transformador.
Gracias a ellos, se han mejorado los modelos de lenguaje al permitirles comprender mejor las relaciones entre las palabras de un texto, por muy separadas que estén. También pueden aprender de forma automática y adaptarse a diferentes tareas y situaciones, lo que ha supuesto una mejora en la precisión y calidad del texto generado.

Están involucrados en una amplia variedad de aplicaciones y tecnologías.
1. Asistentes virtuales: son fundamentales en asistentes virtuales como Siri, Google Assistant o Amazon Alexa. Utilizan modelos de lenguaje para comprender y responder a comandos de voz, realizar búsquedas, proporcionar información y realizar tareas como enviar mensajes o realizar llamadas.
2. Traducción automática: son fundamentales para los sistemas de traducción automática. Ayudan a traducir texto de un idioma a otro con mayor precisión y naturalidad. Un ejemplo más que conocido es Google Translate o DeepL.

3. Corrección: se utiliza en herramientas de revisión, como correctores ortográficos y gramaticales. Estas herramientas utilizan el modelo para identificar y corregir errores comunes de escritura, mejorando la calidad y precisión del texto.
4. Generación de texto: pueden generar texto coherente y relevante en diferentes contextos como el claro ejemplo de ChatGPT, Bard o Bing Chat. Estos también se utilizan en aplicaciones para la generación de subtítulos automáticos de videos o la creación de contenido para redes sociales.
5. Autocompletado de texto: se utilizan en funciones como sugerencias de palabras en teclados de teléfonos inteligentes o recomendaciones de búsqueda de Google, por ejemplo. Ayudan a predecir y sugerir palabras y frases a medida que escribe.
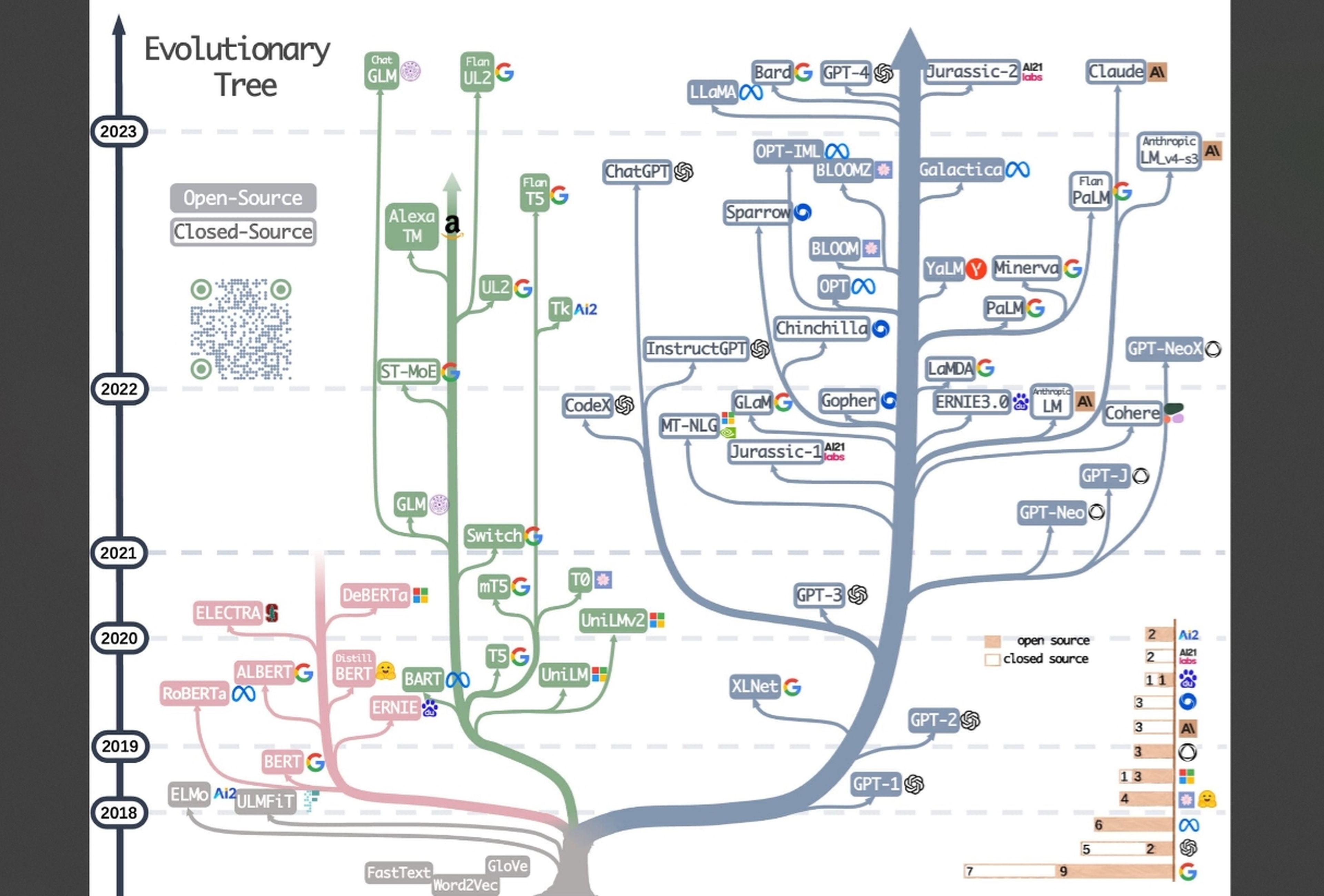
4 modelos lingüísticos que debes conocer
GPT-4
El último lanzamiento de OpenAI, GPT-4, es el modelo de IA más poderoso e impresionante hasta el momento de la compañía detrás de ChatGPT y DALL-E.
Ya disponible para algunos usuarios de ChatGPT, GPT-4 se entrenó en una red masiva de supercomputación en la nube que vincula miles de GPU, diseñadas a medida y construidas en conjunto con Microsoft Azure.
La compañía ha revelado los poderes del modelo de lenguaje en su blog diciendo que es más creativo y colaborativo que nunca. Si bien ChatGPT con tecnología GPT-3.5 solo aceptaba la entrada de texto, GPT-4 también puede usar imágenes para generar subtítulos y análisis.
El cambio más notable es que es multimodal, lo que le permite comprender más de una modalidad de información. GPT-3 y GPT-3.5 de ChatGPT estaban limitados a la entrada y salida de texto, lo que significa que solo podían leer y escribir. Sin embargo, GPT-4 puede recibir imágenes y pedirle que comprenda esta información.
En cuanto a las diferencias con los modelos anteriores, una que hay que destacar desde el principio se basa en el concepto de “Más potencia a menor escala”. OpenAI, como es habitual, es muy cauteloso a la hora de ofrecer toda la información y parámetros utilizados para entrenar GPT-4 en este caso.

LaMDA
El modelo LaMDA (Language Model for Dialogue Applications) de Google es tan preciso que supuestamente convenció a un ingeniero de inteligencia artificial de que tenía sentimientos.
Cuando no asusta a los trabajadores, el modelo puede generar un diálogo conversacional de forma libre, en comparación con las respuestas basadas en tareas que suelen generar los modelos tradicionales.
Esto es porque LaMDA se formó en diálogo. Según Google, su enfoque permitió que el modelo capturara los matices que distinguen una conversación abierta de otras formas de lenguaje.
Presentado por primera vez en el evento I/O de la compañía en mayo de 2021, Google planea usar el modelo en todos sus productos, incluido su motor de búsqueda, el Asistente de Google y la plataforma Workspace.
Y en su evento I/O de 2022, la compañía anunció expansiones a las capacidades del modelo a través de LaMDA 2. Según se informa, la última versión está más afinada que la original y ahora puede generar recomendaciones basadas en las consultas de los usuarios. . LaMDA2 se entrenó en el modelo de lenguaje Pathways (PaLM) de Google, que tiene 540 mil millones de parámetros.
BERT
BERT (Representaciones de codificador bidireccional de transformadores) es un modelo de lenguaje basado en la arquitectura transformador que ha revolucionado el procesamiento del lenguaje natural. Fue presentado por Google en 2018 y destaca por su capacidad para captar el contexto y el significado de las palabras de forma profunda.
A diferencia de los modelos de lenguaje tradicionales que se entrenan de forma unidireccional, BERT utiliza un enfoque bidireccional. Esto significa que tiene la capacidad de ver tanto las palabras antes como después de la palabra en cuestión durante el entrenamiento.

Esta bidireccionalidad ayuda a BERT a comprender el contexto de una palabra y capturar mejor las complejas relaciones entre las palabras en una oración.
BERT se entrena en grandes cantidades de texto sin etiquetar en un proceso llamado «preentrenamiento». Durante esto, el modelo aprende a predecir palabras ocultas en una oración usando el contexto dado por las palabras circundantes. Esta tarea de predicción de palabras ocultas se conoce como Modelado de lenguaje enmascarado (LMM).
Llamadas
LLaMA (Large Language Model Meta AI) es un modelo de la empresa Meta presentado el 25 de febrero de 2023 que se basa en la arquitectura del transformador. Al igual que otros modelos de lenguaje destacados, LLaMA funciona tomando una secuencia de palabras como entrada y prediciendo la siguiente palabra, generando texto de forma recursiva.
Lo que distingue a LLaMA es su capacitación en una amplia gama de datos de texto disponibles públicamente que abarcan numerosos idiomas y sus modelos están disponibles en varios tamaños: parámetros 7B, 13B, 33B y 65B, y puede acceder a ellos en Hugging Face.
Como has visto, Los modelos de lenguaje son herramientas clave en el procesamiento del lenguaje natural, que permiten comprender y generar texto de manera efectiva. y su relevancia radica en su capacidad para transformar la forma en que interactuamos con el lenguaje, facilitando la comunicación humana y abriendo nuevas posibilidades en el campo digital.