
En un proyecto de desarrollo de software tras otro, se ha demostrado que las pruebas ahorran tiempo. ¿Es esto cierto para los proyectos de aprendizaje automático? ¿Deberían los científicos de datos escribir pruebas? ¿Hará que su trabajo sea mejor y / o más rápido? ¡Creemos que la respuesta es sí!
En esta publicación, describimos un flujo de implementación y desarrollo completo que acelera el trabajo de la ciencia de datos, aumenta los niveles de confianza de los científicos de datos y asegura la calidad de la entrega, al igual que en el desarrollo de software.
Lea más para conocer nuestra metodología de prueba en proyectos de ciencia de datos, incluidos ejemplos de pruebas en los diferentes pasos del proceso.
Metodología de prueba: flujo
Como en muchos proyectos de ML, asumimos lo siguiente:
- Un flujo constante de datos
- El modelo ML se crea y se entrega de forma periódica, para dar cuenta de la capacitación sobre nuevos datos.
- Los aspectos del modelo en sí pueden cambiar: características, hiperparámetros o incluso el algoritmo
Dividimos las pruebas en dos tipos principales:
| Descripción | Medio ambiente | |
| Pruebas de canalización | Proceso de creación del modelo de prueba | Entorno de prueba, con datos de prueba |
| Pruebas de AA | Validar el rendimiento / precisión del modelo creado | Entorno de producción, datos actualizados |
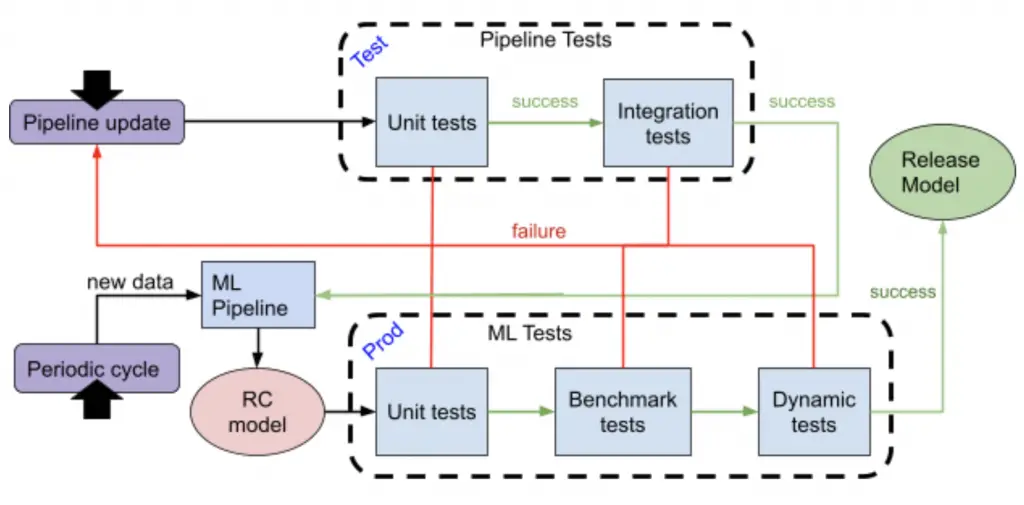
A continuación se muestra un diagrama del flujo completo de nuestra metodología sugerida. El flujo puede desencadenarse por uno de dos eventos:
- Una creación periódica de modelos: si lo único que cambia son los datos, ejecute solo pruebas de AA.
- Actualización de canalización: cualquier cambio en los datos, modelar hiperparámetros, etc. Ejecutar pruebas de canalización y pruebas de aprendizaje automático.
Si tiene éxito, los Release Candidates (RC) del modelo se pueden implementar en producción. En caso de falla, el código debe corregirse y toda la tubería de prueba debe ejecutarse nuevamente.
Lea más para conocer el flujo y los diferentes tipos de pruebas que ejecutamos.
Metodología de prueba: pasos
Pruebas de canalización de ML
Pruebas unitarias de ML Pipeline
Las pruebas unitarias son tan relevantes para las canalizaciones de aprendizaje automático como para cualquier otro código.
Cada paso de la tubería puede y debe probarse mediante una prueba unitaria.
La canalización del aprendizaje automático se basa en código. La funcionalidad incluye muchos pasos como:
- Consulta de datos
- Procesamiento de datos y extracción de características
- Entrenando y probando el modelo
- Realizar inferencia
- Calcular métricas
- Formatear y guardar resultados
Las canalizaciones cambian de una a otra en los pasos, pero todas se basan en código, y el código debe probarse, incluso si está escrito por científicos de datos.
Ejemplo:
Una prueba unitaria para probar el cálculo de la función que cuenta la cantidad de palabras clave SQL en la URL de solicitud HTTP:
def test_keywords_count():
# there is a global list of keywords: [‘text’, ‘word’, ‘sentence’]
assert extract_keywords(“text with a keywords”) == 1
Pruebas de integración de ML Pipeline
El flujo de datos se guarda (con suerte) en una fuente de datos externa como una base de datos o un almacén de objetos y no en su disco local.
Para probar completamente la funcionalidad de su canalización, deberá acceder a fuentes externas y es posible que deba proporcionar credenciales para ejecutar dichas pruebas.
Hay dos enfoques para probar las funcionalidades de acceso externo:
- Prueba DB con un conjunto de datos de prueba
- Mock DB (u otra fuente externa)
Recomendamos utilizar pruebas de integración y simulaciones. Algunas fuentes de datos son realmente difíciles de simular y será más fácil usar un entorno de prueba; realmente depende de la fuente de datos y del proceso que está intentando probar.
Recomendamos ejecutar un flujo de canalización de un extremo a otro en un entorno de prueba con algunos datos de prueba, para asegurarse de que el flujo funcione con una fuente de datos real.
Aquí hay un ejemplo de nuestra infraestructura de canalización de ML: cargamos datos de muestra de una base de datos de prueba, los procesamos y los dividimos para entrenar y probar conjuntos de datos. Posteriormente corremos, entrenamos y probamos:
pipeline.load_data(records_limit=1_000)
pipeline.process_data(train_test_split=0.2)
pipeline.train()
pipeline.test()
Pruebas de aprendizaje automático
A diferencia de las pruebas de canalización, donde queremos verificar que la creación del modelo no falle, en las Pruebas de ML obtenemos un modelo entrenado como entrada cuyos resultados queremos evaluar.
Cada sección puede probar diferentes casos de uso. La depuración de modelos de AA es difícil, pero si elige las pruebas con prudencia, podrá progresar más rápido y, en caso de degradación, podrá analizar rápidamente qué salió mal.
Ejemplo de canalización y pruebas
Para nuestros ejemplos usaremos un clasificador de 'Inyección SQL'. El clasificador obtiene una solicitud HTTP como entrada y genera la probabilidad de un ataque de inyección SQL:

La solicitud HTTP se transforma primero en un vector de características y luego se envía al modelo.
A continuación, se muestran algunos ejemplos de funciones que son comunes en los ataques de inyección SQL:
- Palabras clave SQL como SELECT, UNION y más
- Caracteres SQL como comillas simples, guiones, barra invertida y más
- Expresiones de tautología como '1 = 1' y más
Los vectores de características de solicitud HTTP pueden tener este aspecto:
Palabras clave SQL
Caracteres SQL
SELECCIONE
UNIÓN
UNIÓN TODOS
Una frase
es igual a
...
cierto
falso
falso
2
0
falso
falso
falso
0
0
falso
falso
falso
0
1
Usaremos este ejemplo para explicar los siguientes tipos de pruebas de AA.
ML "Pruebas unitarias"
Los programadores escriben pruebas unitarias para entradas muy específicas, como entradas excepcionales o entradas agregadas como prueba después de encontrar un error. Creemos que los científicos de datos deberían hacer lo mismo.
Queremos asegurarnos de que la entrada obvia se clasifique correctamente y, si no es así, fallará el proceso de prueba rápidamente. También podemos requerir ciertos confianza en la predicción, por ejemplo, la predicción es superior a 0,7. Estas son pruebas cualitativas precisas que pueden probar un solo registro o un pequeño conjunto de datos.
Ejemplo:
Una URL con O 1 = 1 El valor de un parámetro debe clasificarse como un ataque.
Usamos pytest para ejecutar las pruebas de ML, así es como se ve una prueba simple:
def test_1_equals_1():
result = inference_record(url="/my-site?name=OR 1=1")
assert result.is_attack == True
assert result.attack_probability >= 0.7
Tenga en cuenta que en el inference_record () función enviamos datos parciales. La función acepta solo la URL y el resto de los datos se generan automáticamente como se describe a continuación. En las pruebas unitarias, el caso de uso que describimos (por ejemplo, la URL contiene “1 = 1”) debería ser tan obvio que el resto de los datos no deberían cambiar la predicción.
El resto de los datos se genera automáticamente. Hay tres enfoques posibles:
- Cree un registro de entrada 'predeterminado', o un conjunto de ellos. Los valores predeterminados deben ser neutrales en el sentido de que no deben influir mucho en la predicción.
- Una pequeña muestra bien mezclada de sus datos y cambie solo los valores que pruebe.
- Genere un registro de entrada 'promedio' establecido. Utilice estadísticas sobre los datos existentes para encontrar los valores más comunes y neutrales para cada columna.
Aquí hay otro ejemplo en el que usamos la contribución de la función de predicción. Hay varias formas de obtener la contribución de las funciones de una predicción. Una forma muy popular es SHAP, que es independiente del modelo. En esta prueba, verificamos que la función UNION ALL contribuyó a la probabilidad de ataque:
def test_union_all_keyword():
result = inference_record(url="/my-site?name=UNION ALL")
assert ”union_all” in result.contributions
assert result.contributions[”union_all”] >= 0.1
Pruebas comparativas
La evaluación comparativa es nuestra forma de saber que el rendimiento del modelo es al menos tan bueno como solía ser. Las pruebas de referencia se basan en un grupo de conjuntos de datos estáticos. Para aprobar las pruebas comparativas, el modelo debe funcionar al menos tan bien como algunas métricas predefinidas (por ejemplo, precisión superior a 0,95 y precisión superior a 0,97).
Las pruebas de referencia deben crearse lo antes posible en el proyecto y no cambiarán (aunque, por supuesto, puede agregar nuevos conjuntos de datos a la referencia). Pueden incluir:
- Conjuntos de datos que representan datos de la vida real de la mejor manera posible; y
- Escenarios realistas y comunes.
Las pruebas de referencia se ejecutarán en cada cambio de código que se haya enviado, por lo que cualquier degradación se notará tan pronto como se cree.
Ejemplos:
- Tráfico HTTP legítimo: ninguna de las solicitudes debe clasificarse como ataque
- Conjuntos de datos de herramientas de ataque: los datos de herramientas maliciosas se pueden capturar y guardar en un conjunto de datos
- Vectores de ataque comunes
def test_attack_samples():
result = inference_benchmark(”sqli_keywords.csv”)
assert (result[”prediction”] == 1).all()
Pruebas dinámicas
Una prueba dinámica está destinada a probar un escenario específico sobre datos cambiantes y es algo aleatoria. La opción más obvia es un marco de tiempo de ejecución, por ejemplo, ejecutar la prueba de hoy en la semana anterior a la fecha de la prueba. Al ejecutar pruebas en diferentes días, podrá notar cambios en el rendimiento de su modelo.
Los casos de uso pueden ser similares a las pruebas comparativas. Las pruebas en diferentes fechas a lo largo del tiempo pueden ayudarlo a monitorear qué tan bien funciona el modelo con datos de la vida real y cómo cambia su rendimiento. Una degradación en las pruebas dinámicas puede significar dos cosas:
- Su modelo no es tan bueno como solía ser; o
- La realidad cambió.
Ambas opciones requieren la atención de un científico de datos.
A diferencia de las pruebas comparativas, los datos de las pruebas dinámicas cambian en cada ejecución de prueba. En algunos casos, no podrá obtener etiquetas de alta calidad. Puede que tenga que conformarse con algunas heurísticas.
Los casos de uso de pruebas dinámicas pueden ser una combinación de los casos de uso de las pruebas comparativas y las pruebas unitarias.
Ejemplo:
El tráfico legítimo cambia todo el tiempo y queremos asegurarnos de que todas las solicitudes no se identifiquen como ataques SQLi.
def test_30d_back_clean_traffic():
result = inference_by_filter(days_back=30, is_attack= False)
assert (result[”prediction”] == 1).all()
Un escáner de vulnerabilidades es una herramienta creada para identificar debilidades en un sistema. Envía muchos ataques, probando para ver si tienen éxito. La siguiente prueba dinámica se ejecuta en solicitudes HTTP, hace 90 días, que son creadas por un escáner de vulnerabilidades.
Hay muchos escáneres y constantemente se lanzan nuevas versiones, y es por eso que necesitamos un conjunto de datos dinámicos. Nos gustaría asegurarnos de que el número máximo de solicitudes originadas por los escáneres se identifique como ataques. En este ejemplo asumimos que la aplicación cliente es conocida:
def test_90d_back_by_vulnerability_scanners():
result = inference_by_filter(days_back=90,
client_app=VulnerabilityScanner)
assert result.accuracy >= 0.99
Dado que los datos de entrada se cambian dinámicamente, usamos umbrales para decidir sobre una falla. Los datos que no se clasifican correctamente se utilizan más adelante para mejorar la canalización; es posible que se actualice el modelo o la canalización.
Lección para llevar
Las pruebas ahorran tiempo, incluso para los científicos de datos. Incluya pruebas en su proyecto y en su planificación. Le ayudará de muchas maneras: sabrá dónde se encuentra su modelo, podrá realizar cambios con confianza y entregará un modelo más estable con mejor calidad.
Las pruebas más básicas con las que recomendamos comenzar son:
- Pruebas de integración de canalizaciones - prueba de cordura de la tubería, incluida la integración con una fuente de datos
- Pruebas comparativas de ML - conjuntos de datos estáticos, de acuerdo con los temas de su dominio

Elija las pruebas que sean más importantes para su trabajo: ¡cuantas más, mejor!
La publicación Pruebas de aprendizaje automático para científicos de datos apareció primero en Blog.
*** Este es un blog sindicado de Security Bloggers Network de Blog escrito por Ori Nakar. Lea la publicación original en: https://www.imperva.com/blog/machine-learning-testing-for-data-scientists/