

repetición
Los modelos de difusión han surgido recientemente como el estándar de facto para generar resultados complejos y de gran dimensión. Es posible que los conozca por su capacidad para producir impresionantes imágenes sintéticas hiperrealistas y arte de IA, pero también han tenido éxito en otras aplicaciones, como el diseño de fármacos y el control continuo. La idea clave detrás de los modelos de difusión es transformar iterativamente el ruido aleatorio en una muestra, como una imagen o una estructura de proteína. Esto suele estar motivado como un problema de estimación de máxima verosimilitud, en el que el modelo se entrena para generar muestras que coincidan lo más posible con los datos de entrenamiento.
Sin embargo, la mayoría de los casos de uso de los modelos de difusión no se relacionan directamente con la coincidencia de los datos de entrenamiento, sino con un objetivo posterior. No solo queremos una imagen que se parezca a las imágenes existentes, sino que tenga un tipo específico de apariencia; no solo queremos una molécula de fármaco que sea físicamente plausible, sino que sea lo más eficaz posible. En esta publicación, mostramos cómo los modelos de difusión se pueden entrenar en estos objetivos posteriores directamente utilizando el aprendizaje por refuerzo (RL). Para hacer esto, ajustamos la Difusión estable en una variedad de objetivos, incluida la compresibilidad de la imagen, la calidad estética percibida por el ser humano y la alineación de imágenes rápidas. El último de estos objetivos utiliza la retroalimentación de un gran modelo de visión y lenguaje para mejorar el rendimiento del modelo en indicaciones inusuales, lo que demuestra cómo se pueden usar modelos poderosos de IA para mejorarse mutuamente sin que haya humanos en el proceso.
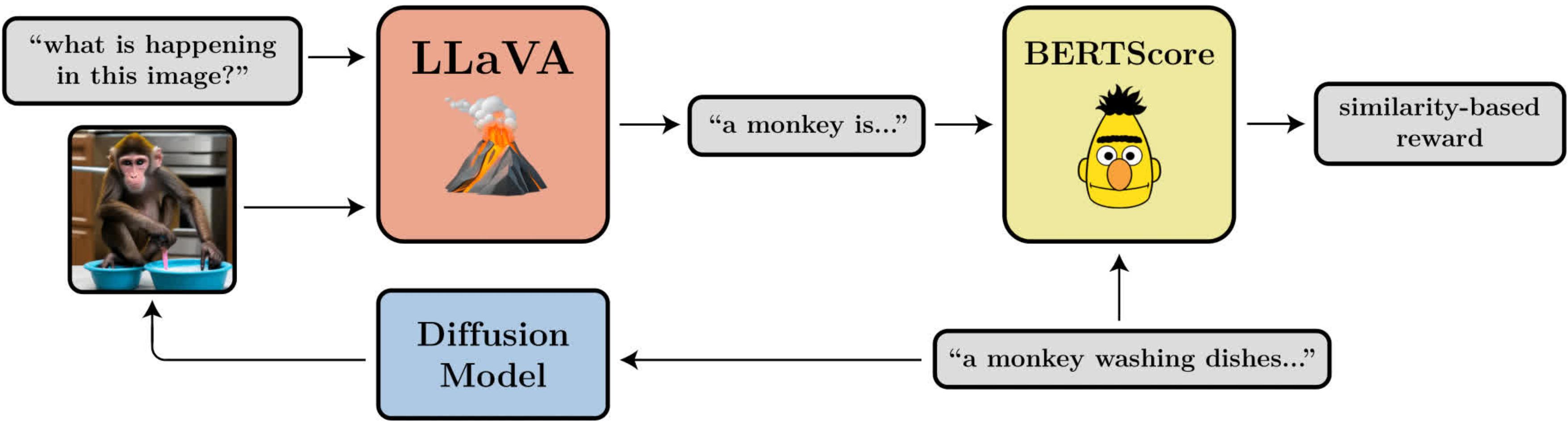
Un diagrama que ilustra el objetivo de alineación de la imagen del indicador. Utiliza LLaVA, un gran modelo de visión y lenguaje, para evaluar las imágenes generadas.
Optimización de la política de difusión de eliminación de ruido
Al convertir la difusión en un problema de RL, hacemos solo la suposición más básica: dada una muestra (por ejemplo, una imagen), tenemos acceso a una función de recompensa que podemos evaluar para decirnos qué tan «buena» es esa muestra. Nuestro objetivo es que el modelo de difusión genere muestras que maximicen esta función de recompensa.
Los modelos de difusión generalmente se entrenan utilizando una función de pérdida derivada de la estimación de máxima verosimilitud (MLE), lo que significa que se les recomienda generar muestras que hagan que los datos de entrenamiento parezcan más probables. En la configuración de RL, ya no tenemos datos de entrenamiento, solo muestras del modelo de difusión y sus recompensas asociadas. Una forma en que aún podemos usar la misma función de pérdida motivada por MLE es tratar las muestras como datos de entrenamiento e incorporar las recompensas al ponderar la pérdida de cada muestra por su recompensa. Esto nos da un algoritmo que llamamos regresión ponderada por recompensa (RWR), después de los algoritmos existentes de la literatura RL.
Sin embargo, hay algunos problemas con este enfoque. Una es que RWR no es un algoritmo particularmente exacto: maximiza la recompensa solo aproximadamente (ver Nair et. al., Apéndice A). La pérdida por difusión inspirada en MLE tampoco es exacta y, en cambio, se deriva utilizando un límite variacional en la probabilidad real de cada muestra. Esto significa que RWR maximiza la recompensa a través de dos niveles de aproximación, lo que, según encontramos, perjudica significativamente su rendimiento.
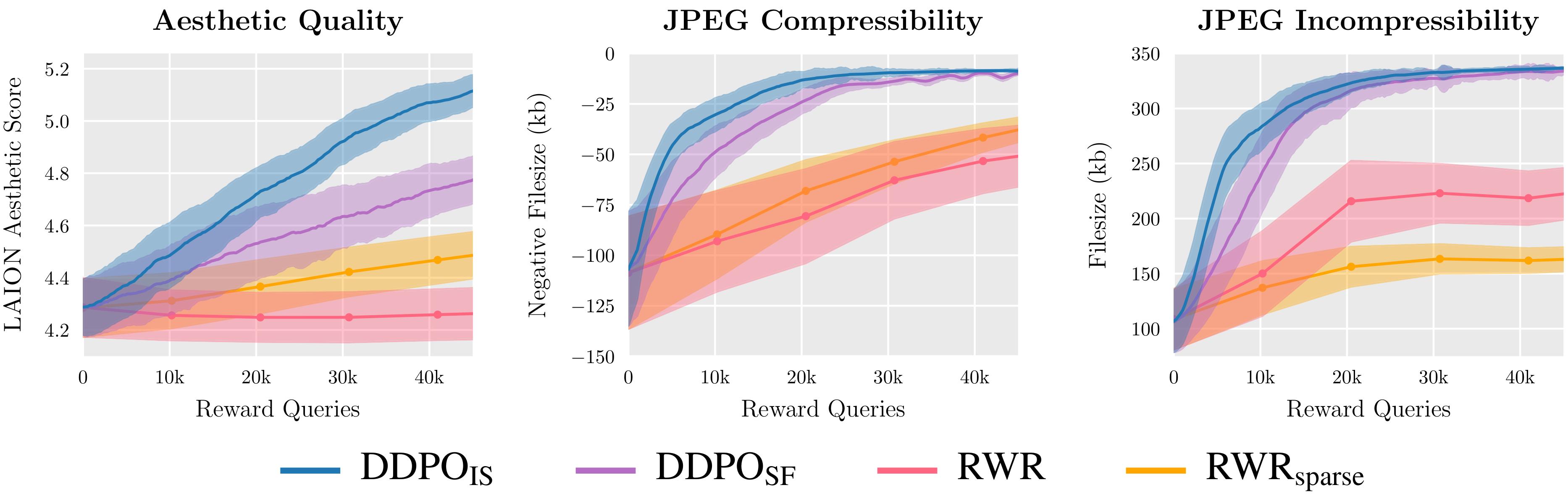
Evaluamos dos variantes de DDPO y dos variantes de RWR en tres funciones de recompensa y descubrimos que DDPO logra constantemente el mejor rendimiento.
La idea clave de nuestro algoritmo, que llamamos optimización de la política de difusión de eliminación de ruido (DDPO), es que podemos maximizar mejor la recompensa de la muestra final si prestamos atención a toda la secuencia de pasos de eliminación de ruido que nos llevaron allí. Para hacer esto, reformulamos el proceso de difusión como un proceso de decisión de Markov (MDP) de varios pasos. En la terminología de MDP: cada paso de eliminación de ruido es una acción, y el agente solo obtiene una recompensa en el paso final de cada trayectoria de eliminación de ruido cuando se produce la muestra final. Este marco nos permite aplicar muchos algoritmos potentes de la literatura de RL que están diseñados específicamente para MDP de varios pasos. En lugar de usar la probabilidad aproximada de la muestra final, estos algoritmos usan la probabilidad exacta de cada paso de eliminación de ruido, que es extremadamente fácil de calcular.
Elegimos aplicar algoritmos de gradiente de políticas debido a su facilidad de implementación y al éxito anterior en el ajuste fino del modelo de lenguaje. Esto llevó a dos variantes de DDPO: DDPOSF, que utiliza el estimador de función de puntuación simple del gradiente de política, también conocido como REFORZAR; y DDPOES, que utiliza un estimador muestreado por importancia más potente. DDPOES es nuestro algoritmo de mejor rendimiento y su implementación sigue de cerca la de la optimización de políticas proximales (PPO).
Ajuste fino de la difusión estable mediante DDPO
Para nuestros resultados principales, ajustamos Stable Diffusion v1-4 usando DDPOES. Tenemos cuatro tareas, cada una definida por una función de recompensa diferente:
- Compresibilidad: ¿Qué tan fácil es comprimir la imagen usando el algoritmo JPEG? La recompensa es el tamaño de archivo negativo de la imagen (en kB) cuando se guarda como JPEG.
- Incompresibilidad: ¿Qué tan difícil es comprimir la imagen usando el algoritmo JPEG? La recompensa es el tamaño de archivo positivo de la imagen (en kB) cuando se guarda como JPEG.
- Calidad estética: ¿Cuán estéticamente atractiva es la imagen para el ojo humano? La recompensa es el resultado del predictor estético LAION, que es una red neuronal entrenada en las preferencias humanas.
- Alineación de la imagen del mensaje: ¿qué tan bien representa la imagen lo que se solicitó en el mensaje? Este es un poco más complicado: ingresamos la imagen en LLaVA, le pedimos que describa la imagen y luego calculamos la similitud entre esa descripción y el mensaje original usando BERTScore.
Dado que Stable Diffusion es un modelo de texto a imagen, también debemos elegir un conjunto de indicaciones para proporcionarlo durante el ajuste fino. Para las primeras tres tareas, usamos instrucciones simples de la forma «un) [animal]”. Para la alineación de la imagen del mensaje, usamos mensajes del formulario «un) [animal] [activity]”donde se realizan las actividades «lavando platos», «jugando ajedrez»y «montando una bici». Descubrimos que Stable Diffusion a menudo tenía problemas para producir imágenes que coincidieran con el aviso para estos escenarios inusuales, lo que dejaba mucho margen de mejora con el ajuste fino de RL.
Primero, ilustramos el desempeño de DDPO en las recompensas simples (compresibilidad, incompresibilidad y calidad estética). Todas las imágenes se generan con la misma semilla aleatoria. En el cuadrante superior izquierdo, ilustramos lo que genera Stable Diffusion «vainilla» para nueve animales diferentes; todos los modelos con ajuste fino de RL muestran una clara diferencia cualitativa. Curiosamente, el modelo de calidad estética (arriba a la derecha) tiende hacia dibujos lineales minimalistas en blanco y negro, que revelan los tipos de imágenes que el predictor estético LAION considera «más estéticas».

A continuación, demostramos DDPO en la tarea más compleja de alineación de imagen de solicitud. Aquí, mostramos varias instantáneas del proceso de capacitación: cada serie de tres imágenes muestra muestras para la misma semilla rápida y aleatoria a lo largo del tiempo, y la primera muestra proviene de Vanilla Stable Diffusion. Curiosamente, el modelo cambia hacia un estilo más parecido al de una caricatura, lo cual no fue intencional. Nuestra hipótesis es que esto se debe a que es más probable que los animales que realizan actividades similares a las humanas aparezcan en un estilo de dibujos animados en los datos previos al entrenamiento, por lo que el modelo cambia hacia este estilo para alinearse más fácilmente con el mensaje aprovechando lo que ya sabe.

Generalización inesperada
Se ha encontrado que surge una generalización sorprendente cuando se ajustan modelos de lenguaje grandes con RL: por ejemplo, modelos ajustados en el seguimiento de instrucciones solo en inglés a menudo mejoran en otros idiomas. Encontramos que el mismo fenómeno ocurre con los modelos de difusión de texto a imagen. Por ejemplo, nuestro modelo de calidad estética se ajustó utilizando indicaciones que se seleccionaron de una lista de 45 animales comunes. Encontramos que se generaliza no solo a animales invisibles sino también a objetos cotidianos.

Nuestro modelo de alineación de imágenes rápidas utilizó la misma lista de 45 animales comunes durante el entrenamiento y solo tres actividades. Encontramos que se generaliza no solo a animales invisibles sino también a actividades invisibles, e incluso nuevas combinaciones de los dos.

sobreoptimización
Es bien sabido que el ajuste fino de una función de recompensa, especialmente una aprendida, puede conducir a una sobreoptimización de la recompensa donde el modelo explota la función de recompensa para lograr una recompensa alta de una manera no útil. Nuestro entorno no es una excepción: en todas las tareas, el modelo finalmente destruye cualquier contenido de imagen significativo para maximizar la recompensa.

También descubrimos que LLaVA es susceptible a ataques tipográficos: al optimizar la alineación con respecto a las indicaciones del formulario “[n] animales”DDPO pudo engañar con éxito a LLaVA al generar un texto que se parecía vagamente al número correcto.

Actualmente no existe un método de propósito general para prevenir la optimización excesiva, y destacamos este problema como un área importante para el trabajo futuro.
Conclusión
Los modelos de difusión son difíciles de superar cuando se trata de producir resultados complejos y de gran dimensión. Sin embargo, hasta ahora han tenido éxito principalmente en aplicaciones donde el objetivo es aprender patrones a partir de montones y montones de datos (por ejemplo, pares de imágenes y leyendas). Lo que hemos encontrado es una manera de entrenar modelos de difusión de manera efectiva que va más allá de la coincidencia de patrones, y sin requerir necesariamente ningún dato de entrenamiento. Las posibilidades están limitadas únicamente por la calidad y la creatividad de su función de recompensa.
La forma en que usamos DDPO en este trabajo está inspirada en los éxitos recientes del ajuste fino del modelo de lenguaje. Los modelos GPT de OpenAI, como Stable Diffusion, se entrenan primero con grandes cantidades de datos de Internet; luego se ajustan con RL para producir herramientas útiles como ChatGPT. Por lo general, su función de recompensa se aprende de las preferencias humanas, pero otros tienen más recientemente descubrió cómo producir poderosos chatbots utilizando funciones de recompensa basadas en comentarios de IA. En comparación con el régimen de chatbot, nuestros experimentos son a pequeña escala y de alcance limitado. Pero considerando el enorme éxito de este paradigma de «preentrenamiento + ajuste fino» en el modelado del lenguaje, ciertamente parece que vale la pena seguir adelante en el mundo de los modelos de difusión. Esperamos que otros puedan aprovechar nuestro trabajo para mejorar los modelos de gran difusión, no solo para la generación de texto a imagen, sino también para muchas aplicaciones interesantes, como la generación de video, la generación de música, la edición de imágenes, la síntesis de proteínas, la robótica y más.
Además, el paradigma de «preentrenamiento + ajuste fino» no es la única forma de usar DDPO. Siempre que tenga una buena función de recompensa, no hay nada que le impida entrenar con RL desde el principio. Si bien esta configuración aún no se ha explorado, este es un lugar donde las fortalezas de DDPO realmente podrían brillar. Pure RL se ha aplicado durante mucho tiempo a una amplia variedad de dominios que van desde juegos hasta manipulación robótica, fusión nuclear y diseño de chips. Agregar la poderosa expresividad de los modelos de difusión a la mezcla tiene el potencial de llevar las aplicaciones existentes de RL al siguiente nivel, o incluso descubrir otras nuevas.
Esta publicación se basa en el siguiente artículo:
Si desea obtener más información sobre DDPO, puede consultar el documento, el sitio web, el código original u obtener los pesos del modelo en Hugging Face. Si desea utilizar DDPO en su propio proyecto, consulte mi implementación PyTorch + LoRA donde puede ajustar la difusión estable con menos de 10 GB de memoria GPU.
Si DDPO inspira su trabajo, cítelo con:
@misc{black2023ddpo,
title={Training Diffusion Models with Reinforcement Learning},
author={Kevin Black and Michael Janner and Yilun Du and Ilya Kostrikov and Sergey Levine},
year={2023},
eprint={2305.13301},
archivePrefix={arXiv},
primaryClass={cs.LG}
}