
Hay un gran número de diferentes tipos de técnicas de preparación de datos que podría utilizarse en un proyecto de modelado predictivo.
En algunos casos, la distribución de los datos o los requisitos de un modelo de aprendizaje automático pueden sugerir la preparación de los datos necesarios, aunque rara vez es así dada la complejidad y la gran dimensión de los datos, el desfile cada vez mayor de nuevos algoritmos de aprendizaje automático y las limitaciones, aunque humanas, del profesional.
En cambio, la preparación de los datos puede ser tratada como otro hiperparámetro a afinar como parte de la tubería de modelización. Esto plantea la cuestión de cómo saber qué métodos de preparación de datos hay que considerar en la búsqueda, lo que puede resultar abrumador tanto para los expertos como para los principiantes.
La solución es pensar en el vasto campo de la preparación de datos de manera estructurada y evaluar sistemáticamente las técnicas de preparación de datos en función de su efecto en los datos en bruto.
En este tutorial, descubrirá un marco que proporciona un enfoque estructurado tanto para pensar como para agrupar las técnicas de preparación de datos para la elaboración de modelos predictivos con datos estructurados.
Después de completar este tutorial, lo sabrás:
- El desafío y la agobiante preparación de los datos de encuadre es un hiperparámetro adicional para sintonizar en la tubería de modelización del aprendizaje de la máquina.
- Un marco que define cinco grupos de técnicas de preparación de datos a considerar.
- Ejemplos de técnicas de preparación de datos pertenecientes a cada grupo que pueden ser evaluadas en su proyecto de modelización predictiva.
Descubre la limpieza de datos, la selección de características, la transformación de datos, la reducción de la dimensionalidad y mucho más en mi nuevo libro, con 30 tutoriales paso a paso y el código fuente completo en Python.
Empecemos.

Marco para las técnicas de preparación de datos en el aprendizaje automático
Foto de Phil Dolby, algunos derechos reservados.
Resumen del Tutorial
Este tutorial está dividido en tres partes; son:
- Desafío de la preparación de datos
- Marco para la preparación de datos
- Técnicas de preparación de datos
Desafío de la preparación de datos
La preparación de datos se refiere a la transformación de los datos en bruto en una forma que se adapte mejor a la modelización predictiva.
Esto puede ser necesario porque los propios datos contienen errores o fallos. También puede deberse a que los algoritmos elegidos tienen expectativas en cuanto al tipo y la distribución de los datos.
Para que la tarea de preparación de datos sea aún más difícil, también es común que la preparación de datos necesaria para obtener el mejor rendimiento de un modelo predictivo no sea obvia y pueda doblar o violar las expectativas del modelo que se está utilizando.
Como tal, es común tratar la elección y la configuración de la preparación de los datos aplicados a los datos en bruto como otro hiperparámetro más de la tubería de modelización que se debe ajustar.
Este encuadre de la preparación de datos es muy eficaz en la práctica, ya que permite utilizar técnicas de búsqueda automática como la búsqueda en cuadrículas y la búsqueda aleatoria para descubrir pasos de preparación de datos poco intuitivos que dan lugar a modelos de predicción hábiles.
Este encuadre de la preparación de datos también puede resultar abrumador para los principiantes, dado el gran número y variedad de técnicas de preparación de datos.
La solución a este problema es pensar en técnicas de preparación de datos de manera sistemática.
Marco para la preparación de datos
Para que la preparación de datos sea eficaz es necesario que las técnicas de preparación de datos disponibles se organicen y examinen de manera estructurada y sistemática.
Esto le permite asegurarse de que se exploren las técnicas de aproximación para su conjunto de datos y que no se salten o ignoren las técnicas potencialmente efectivas.
Esto puede lograrse utilizando un marco para organizar las técnicas de preparación de datos que considere su efecto en el conjunto de datos en bruto.
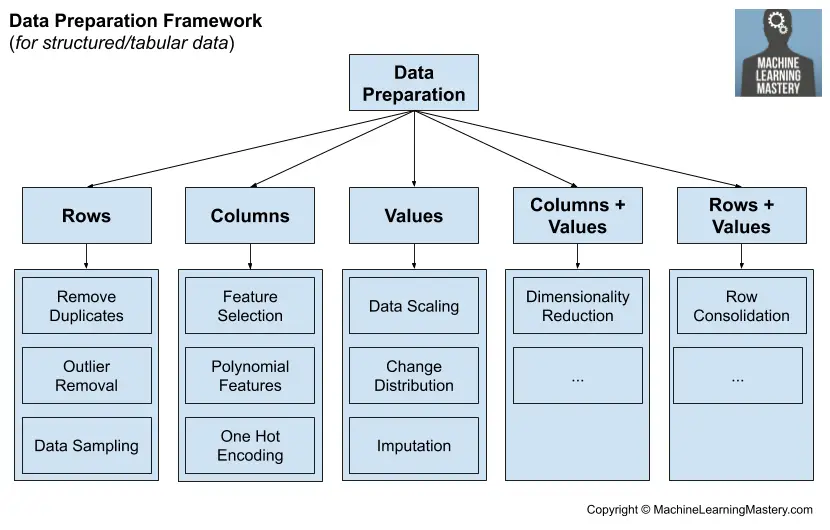
Por ejemplo, los datos estructurados de aprendizaje de la máquina, como los que podríamos almacenar en un archivo CSV para su clasificación y regresión, consisten en filas, columnas y valores. Podríamos considerar técnicas de preparación de datos que operan en cada uno de estos niveles.
- Preparación de datos para las filas
- Preparación de datos para las columnas
- Preparación de los datos para los valores
La preparación de los datos para las filas puede ser una técnica que añade o elimina filas de datos del conjunto de datos. Del mismo modo, la preparación de datos para las columnas puede ser una técnica que añada o elimine filas (características o variables) del conjunto de datos. En cambio, la preparación de datos para valores puede ser una técnica que cambie los valores del conjunto de datos, a menudo para una columna determinada.
Hay un tipo más de preparación de datos que no encaja perfectamente en esta estructura, y es el de las técnicas de reducción de la dimensionalidad. Estas técnicas cambian las columnas y los valores al mismo tiempo, por ejemplo, proyectando los datos en un espacio de menor dimensión.
- Preparación de datos para las columnas + valores
Esto plantea la cuestión de las técnicas que podrían aplicarse a las filas y a los valores al mismo tiempo. Esto podría incluir la preparación de datos que consolide las filas de datos de alguna manera.
- Preparación de datos para filas + valores
Podemos resumir este marco y algunos grupos de alto nivel de métodos de preparación de datos en la siguiente imagen.
Marco de preparación de datos para el aprendizaje automático
Ahora que tenemos un marco para pensar en la preparación de datos basado en su efecto sobre los datos, veamos ejemplos de técnicas que encajan en cada grupo.
Técnicas de preparación de datos
En la presente sección se examinan los cinco grupos de alto nivel de técnicas de preparación de datos definidos en la sección anterior y se sugieren técnicas específicas que pueden corresponder a cada grupo.
¿Me perdí una de sus técnicas de preparación de datos preferidas o favoritas?
Hágamelo saber en los comentarios de abajo.
Preparación de datos para las filas
Este grupo es para las técnicas de preparación de datos que añaden o eliminan filas de datos.
En el aprendizaje por máquina, las filas suelen denominarse muestras, ejemplos o instancias.
Estas técnicas se utilizan a menudo para aumentar un conjunto de datos de capacitación limitado o para eliminar errores o ambigüedades del conjunto de datos.
La principal clase de técnicas que me vienen a la mente son las técnicas de preparación de datos que se utilizan a menudo para la clasificación desequilibrada.
Esto incluye técnicas como SMOTE que crean filas sintéticas de datos de entrenamiento para clases subrepresentadas y submuestreo aleatorio que elimina ejemplos para clases sobre-representadas.
Para más información sobre el muestreo de datos SMOTE, ver el tutorial:
También incluye técnicas combinadas más avanzadas de sobremuestreo y submuestreo que tratan de identificar y eliminar ejemplos ambiguos a lo largo de los límites de decisión de un problema de clasificación y eliminarlos o cambiar su etiqueta de clase.
Para obtener más información sobre estos tipos de preparación de datos, consulte el tutorial:
Esta clase de técnicas de preparación de datos también incluye algoritmos para identificar y eliminar los valores atípicos de los datos. Se trata de filas de datos que pueden estar lejos del centro de la masa de probabilidad del conjunto de datos y, a su vez, pueden no ser representativos de los datos del dominio.
Para más información sobre los métodos de detección y eliminación de valores atípicos, vea el tutorial:
Preparación de datos para las columnas
Este grupo es para las técnicas de preparación de datos que añaden o eliminan columnas de datos.
En el aprendizaje por máquina, las columnas suelen denominarse variables o características.
Estas técnicas suelen ser necesarias para reducir la complejidad (dimensionalidad) de un problema de predicción o para descomponer las variables de entrada compuestas o las interacciones complejas entre las características.
La principal clase de técnicas que me vienen a la mente son las técnicas de selección de características.
Esto incluye técnicas que utilizan estadísticas para puntuar la relevancia de las variables de entrada para la variable objetivo en función del tipo de datos de cada una.
Para más información sobre estos tipos de técnicas de preparación de datos, véase el tutorial:
Esto también incluye técnicas de selección de características que prueban sistemáticamente el impacto de diferentes combinaciones de variables de entrada en la capacidad de predicción de un modelo de aprendizaje de una máquina.
Para obtener más información sobre estos tipos de métodos, consulte el tutorial:
Las técnicas relacionadas son las que utilizan un modelo para puntuar la importancia de las características de entrada en función de su uso por un modelo predictivo, denominadas métodos de importancia de las características. Estos métodos se utilizan a menudo para la interpretación de los datos, aunque también pueden utilizarse para la selección de características.
Para obtener más información sobre estos tipos de métodos, consulte el tutorial:
Este grupo de métodos también trae a la mente técnicas para crear o derivar nuevas columnas de datos, nuevas características. A menudo se hace referencia a ellas como ingeniería de características, aunque a veces todo el campo de la preparación de datos se denomina ingeniería de características.
Por ejemplo, pueden crearse nuevos rasgos que representen valores elevados a exponentes o combinaciones multiplicadoras de rasgos y añadirse al conjunto de datos como nuevas columnas.
Para más información sobre estos tipos de técnicas de preparación de datos, véase el tutorial:
Esto también podría incluir transformaciones de datos que cambien un tipo de variable, como la creación de variables ficticias para una variable categórica, lo que a menudo se denomina codificación de una sola vez.
Para más información sobre estos tipos de técnicas de preparación de datos, véase el tutorial:
Preparación de los datos para los valores
Este grupo es para las técnicas de preparación de datos que cambian los valores brutos de los datos.
Estas técnicas suelen ser necesarias para cumplir las expectativas o requisitos de los algoritmos específicos de aprendizaje de máquinas.
La principal clase de técnicas que me vienen a la mente son las transformaciones de datos que cambian la escala o la distribución de las variables de entrada.
Por ejemplo, las transformaciones de datos como la normalización y la normalización cambian la escala de las variables de entrada numérica. Las transformaciones de datos como la codificación ordinal cambian el tipo de variables de entrada categóricas.
También hay muchas transformaciones de datos para cambiar la distribución de las variables de entrada.
Por ejemplo, la discretización o el binning cambian la distribución de las variables de entrada numérica en variables categóricas con una clasificación ordinal.
Para obtener más información sobre este tipo de transformación de datos, consulte el tutorial:
La transformación de la energía puede utilizarse para cambiar la distribución de los datos para eliminar un sesgo y hacer la distribución más normal (Gaussiano).
Para más información sobre este método, vea el tutorial:
La transformación de cuantiles es un tipo flexible de técnica de preparación de datos que puede mapear una variable de entrada numérica o a diferentes tipos de distribuciones como la normal o la gaussiana.
Puede aprender más sobre esta técnica de preparación de datos aquí:
Otro tipo de técnica de preparación de datos que pertenece a este grupo son los métodos que cambian sistemáticamente los valores del conjunto de datos.
Esto incluye técnicas que identifican y reemplazan los valores perdidos, a menudo denominados imputación de valores perdidos. Esto puede lograrse utilizando métodos estadísticos o métodos más avanzados basados en modelos.
Para más información sobre estos métodos, vea el tutorial:
Todos los métodos examinados podrían considerarse también métodos de ingeniería de características (por ejemplo, encajando en el grupo de métodos de preparación de datos examinados anteriormente) si los resultados de las transformaciones se añaden a los datos brutos como nuevas columnas.
Preparación de datos para las columnas + valores
Este grupo es para las técnicas de preparación de datos que cambian tanto el número de columnas como los valores de los datos.
La principal clase de técnicas que esto trae a la mente son las técnicas de reducción de la dimensionalidad que reducen específicamente el número de columnas y la escala y distribución de las variables de entrada numéricas.
Esto incluye los métodos de factorización de matrices utilizados en el álgebra lineal, así como los múltiples algoritmos de aprendizaje utilizados en la estadística de altas dimensiones.
Para obtener más información sobre estas técnicas, consulte el tutorial:
Aunque estas técnicas están diseñadas para crear proyecciones de filas en un espacio de dimensiones inferiores, quizás esto también deja la puerta abierta a técnicas que hacen lo contrario. Es decir, utilizar todas o un subconjunto de las variables de entrada para crear una proyección en un espacio de dimensiones superiores, quizás descomponiendo complejas relaciones no lineales.
Tal vez la transformación de polinomios donde los resultados sustituyen al conjunto de datos en bruto encajaría en esta clase de métodos de preparación de datos.
¿Conoce otros métodos que encajen en este grupo?
Hágamelo saber en los comentarios de abajo.
Preparación de datos para filas + valores
Este grupo es para las técnicas de preparación de datos que cambian tanto el número de filas como los valores de los datos.
No he considerado explícitamente las transformaciones de datos de este tipo antes, pero se sale del marco definido.
Un grupo de métodos que me vienen a la mente son los algoritmos de agrupación, en los que todos o subconjuntos de filas de datos del conjunto de datos se sustituyen por muestras de datos en los centros de agrupación, denominados centros de agrupación.
Relacionado con ello podría ser la sustitución de filas por ejemplares (agregados de filas) tomados de algoritmos específicos de aprendizaje de máquinas, como los vectores de apoyo de una máquina de vector de apoyo, o los vectores de libro de códigos tomados de una cuantificación de vector de aprendizaje.
Naturalmente, estas filas agregadas se añaden simplemente al conjunto de datos en lugar de reemplazar las filas, entonces encajarían naturalmente en el «Preparación de datos para las filas«…el grupo descrito anteriormente.