
El aprendizaje por refuerzo basado en modelos (MBRL) es una variante del método iterativo
marco de aprendizaje, aprendizaje por refuerzo, que incluye una estructura
componente del sistema que está optimizado únicamente para modelar el entorno
dinámica. El aprendizaje de un modelo está ampliamente motivado por la biología, el control óptimo,
y más: se basa en la intuición humana natural de planificar antes de actuar. Este intuitivo
la puesta a tierra, sin embargo, resulta en un proceso de aprendizaje más complicado. En esto
post, discutimos cómo el aprendizaje por refuerzo basado en modelos es más susceptible a
ajuste de parámetros y cómo AutoML puede ayudar a encontrar un rendimiento muy bueno
ajustes de parámetros y horarios. Abajo, a la izquierda, se muestra el comportamiento esperado de un
agente maximizando la velocidad en una tarea robótica «Half Cheetah», y a la derecha está
lo que encuentra nuestro artículo con el ajuste de hiperparámetros.


MBRL
El aprendizaje por refuerzo basado en modelos (MBRL) es un marco iterativo para resolver
tareas en un entorno parcialmente comprendido. Hay un agente que repetidamente
intenta resolver un problema, acumulando datos de estado y acción. Con esos datos,
el agente crea una herramienta de aprendizaje estructurada, un modelo dinámico, para razonar
Acerca del mundo. Con el modelo de dinámica, el agente decide cómo actuar
prediciendo el futuro. Con esas acciones, el agente recopila más datos,
mejora dicho modelo, y es de esperar que mejore las acciones futuras.
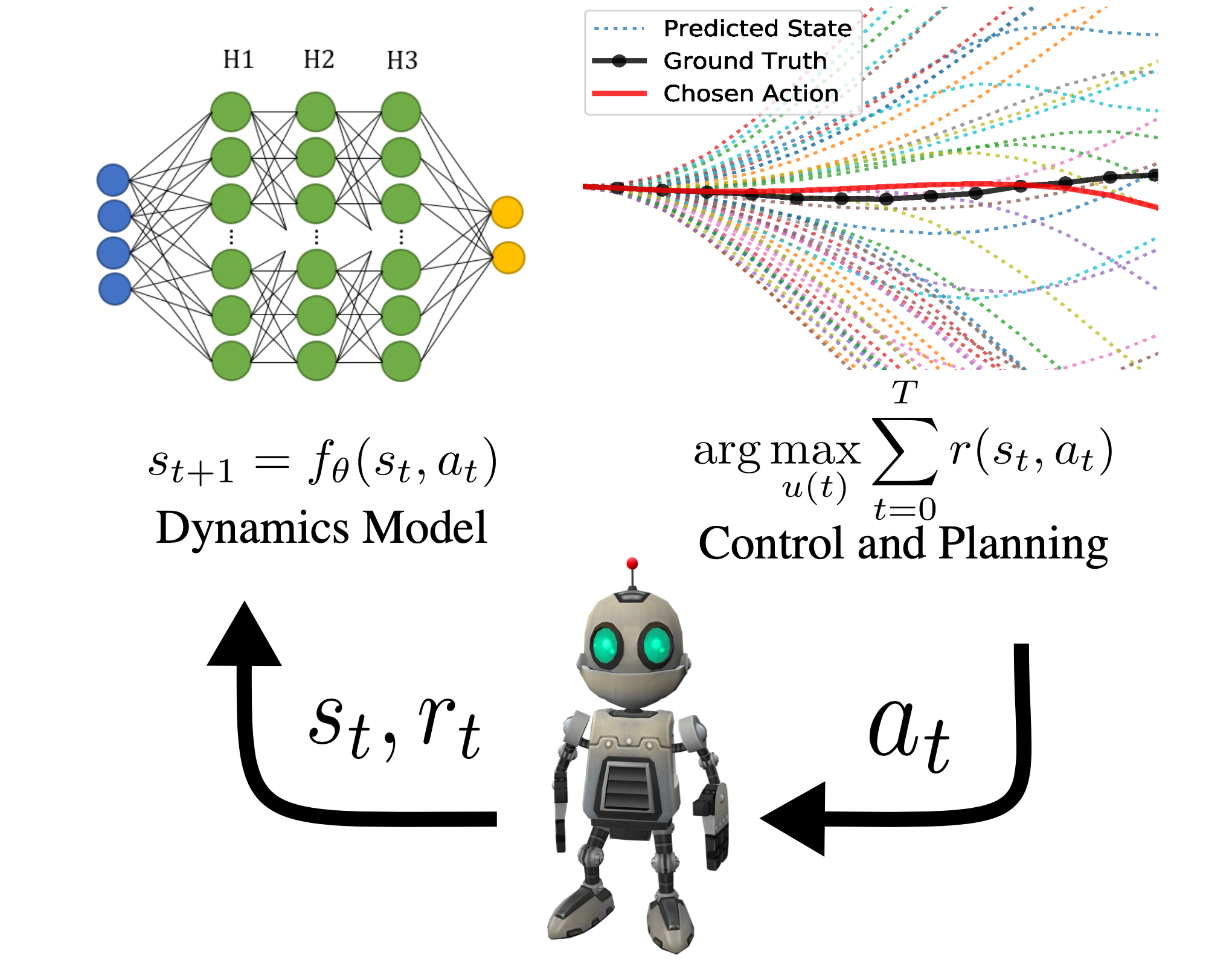
AutoML
Los humanos son bastante pobres para internalizar relaciones de dimensiones superiores.
Desafortunadamente, todos los sistemas ML vienen con hiperparámetros que tienen complejos
Relaciones de dimensiones superiores. Búsqueda manual de configuraciones o
horarios que funcionan bien es una tarea tediosa y poco gratificante, así que dejemos un
computadora hazlo por nosotros. El aprendizaje automático automatizado (AutoML) es un campo
dedicada al estudio del uso de algoritmos de aprendizaje automático para ajustar nuestra máquina
Herramientas de aprendizaje. Sin embargo, no ha habido muchos intentos de utilizar AutoML.
métodos para RL hasta ahora, (para obtener más información sobre AutoRL, consulte esta publicación de blog) incluso
sin embargo, dado el éxito de AutoML en el aprendizaje supervisado, uno podría esperar
mayor impacto en de mayor dimensión RL. Esto se debe en parte a la dificultad
problema de ajuste dinámico de hiperparámetros (donde los hiperparámetros pueden cambiar
dentro de una carrera), pero más sobre eso más adelante.
¿Por qué podemos ver un impacto aún mayor de AutoML en MBRL en comparación con model-freel RL?
En primer lugar, más partes de aprendizaje automático equivalen a un problema más complicado,
por lo que existe un mayor potencial para hacer que el ajuste de hiperparámetros sea mucho más
impactante para MBRL. Normalmente, un estudiante de posgrado afina un problema a la vez
tiempo con un puñado de variables, pero en MBRL hay dos extrañamente entrelazados
sistemas: el modelo y el planificador (los objetivos no coinciden). Por lo tanto, es probable que ningún humano pueda
para encontrar los parámetros perfectos. Gran parte del progreso de la investigación, todavía, está cediendo a
suerte a la hora de encontrar los hiperparámetros correctos. Aunque es un
Abra el problema para ver si las computadoras pueden encontrar el verdadero óptimo, como se mencionó.
antes, las computadoras son mucho mejores para optimizar en espacios de alta dimensión como
como RL.
En segundo lugar, el punto de referencia donde se prueban la mayoría de los algoritmos RL en trabajos recientes:
un simulador llamado Mujoco – se ha utilizado durante años y el rendimiento de
los mejores algoritmos están cerca de maximizar los comportamientos realistas en el
simulador. Una solución tan realista para Half Cheetah se puede ver en el video.
a la izquierda al principio del post.
Mujoco apareció como favorito de Deep RL porque estaba disponible cuando un
Se acercaba una fase de crecimiento masivo. Es un simulador decente, relativamente
liviano y lo suficientemente fácil de usar (aunque Mujoco es caro, tiene bastante
licencias estrictas y no una descripción completamente precisa del mundo real).
Mujoco ha trabajado para investigadores individuales y equipos que crecen en una nueva área,
pero no necesariamente excelente para la salud a largo plazo del campo. Investigadores
han rastreado el rendimiento de los algoritmos llamado estado de la técnica (SOTA)
en todo el grupo de tareas disponibles en el punto de referencia. Esto ha llevado a confiar
en este punto de referencia como un objetivo sustituto de lo que los humanos realmente quieren
optimizar – rendimiento en el mundo real – y dejar progreso en la investigación
campo vulnerable a los juegos. Y en tales problemas, donde es óptimo
Las soluciones pueden no ser intuitivas, es incluso más probable que las computadoras
superan a los humanos.
El aprendizaje por refuerzo, o cualquier marco iterativo para el caso, plantea una
desafío interesante para AutoML y la investigación de ajuste de parámetros: el mejor
los parámetros pueden cambiar con el tiempo. Los parámetros ideales cambian porque el
datos utilizados para entrenar cualquier cambio de modelo a lo largo del tiempo. Esto es diferente de un más
enfoque clásico de AutoML: en una tarea de aprendizaje supervisado, estática
Es mucho más probable que las configuraciones de parámetros funcionen bien (como la
pesos y sesgos de un modelo de visión implementado).
Cuando la distribución de los datos que usamos cambia con el tiempo, buscamos
ajuste dinámico de hiperparámetros donde los hiperparámetros del modelo o
optimizer se adaptan con el tiempo. En el caso de MBRL, esto puede tener un elegante
interpretación: a medida que el agente obtiene más datos, puede entrenar una
modelo, y luego puede querer usar ese modelo para planificar más en el futuro.
Esto se traduciría en un ajuste dinámico del horizonte predictivo del modelo.
variable de hiperparámetro utilizada en la optimización de la acción. Hiperparámetros estáticos –
que la mayoría de los algoritmos de RL informan en tablas en el apéndice de sus artículos –
es probable que no puedan lidiar con distribuciones cambiantes. La
El algoritmo utilizado para demostrar esto es Hyperband (más adelante en la publicación). Es
un método de ajuste estático y los parámetros elegidos muestran una baja correlación con
recompensa en una carrera más larga o en otra tarea. Para obtener más detalles sobre
detalles de la sintonía estática, consulte el artículo, pero la pregunta crucial es: ¿cómo
mucho puede ganar un agente RL con el ajuste dinámico. Normalmente, esta ganancia se mide
sobre el desempeño de un algoritmo en una tarea.
Sin embargo, este hallazgo no significa que el ajuste estático no tenga sus usos.
En este artículo, estudiamos más a fondo qué aspectos de estática y dinámica son más
importante para un practicante dependiendo de lo que quiera lograr –
transferibilidad (entre ejecuciones en la misma tarea o entre tareas) o final
actuación. Demostramos que las configuraciones de parámetros estáticos aprenden
configuraciones de hiperparámetros que son más robustas para la transferencia. Por diseño,
Las configuraciones dinámicas hacen muchas más elecciones sobre la configuración de los parámetros que
configuraciones estáticas, por lo que es muy difícil sintonizar dinámicas
configuraciones a mano y sin métodos HPO automáticos. Con un aumento
número de puntos de decisión, es cada vez más probable que cada elección que tomemos
hacer se adapta específicamente al medio ambiente e incluso a la ejecución actual en
mano.
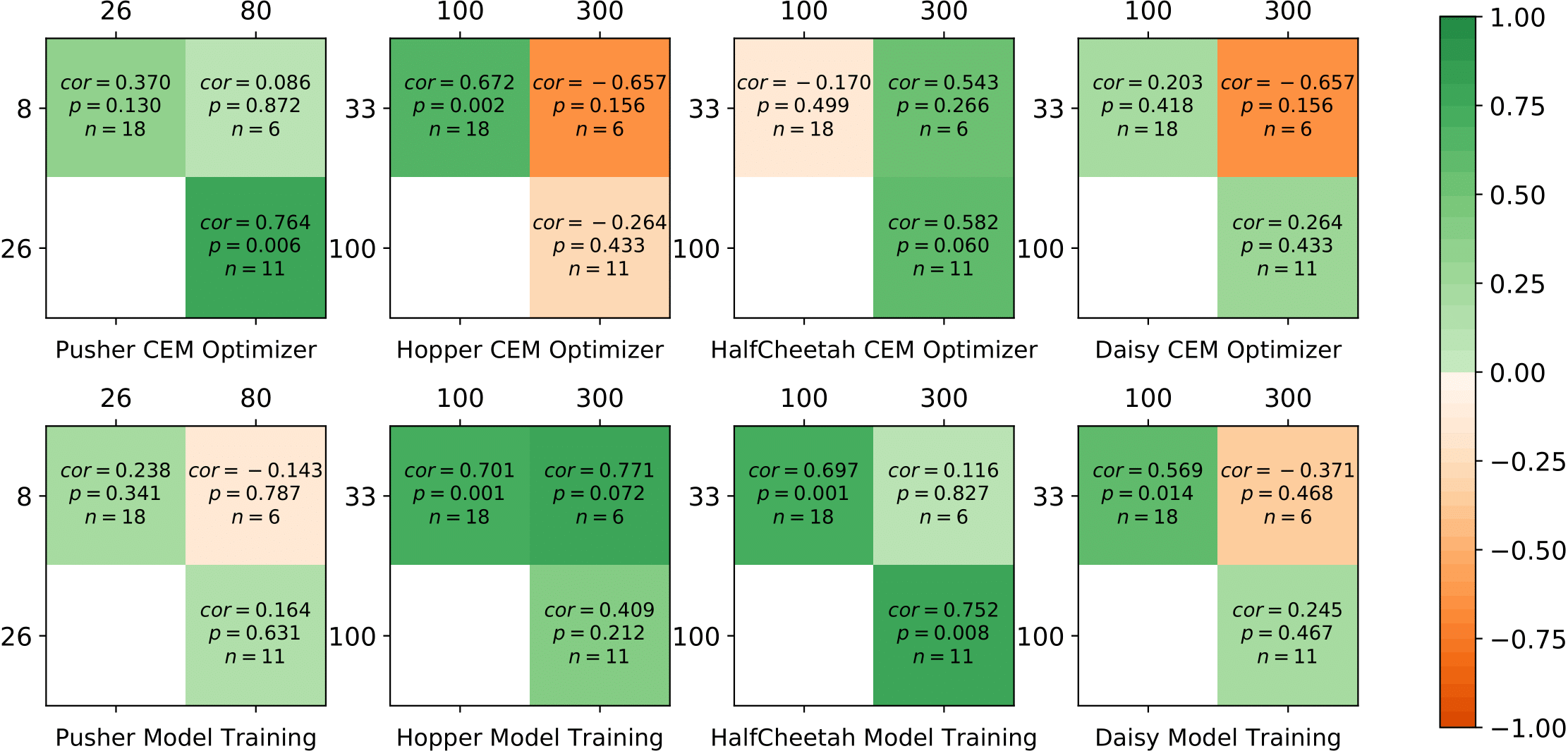
La correlación débil o incluso negativa entre diferentes presupuestos se encuentra en la mayoría de
los entornos con afinaciones estáticas y transferidas, que muestra diferentes
configuraciones funcionan mejor para diferentes duraciones de entrenamiento y esa dinámica
puede ser necesario realizar un ajuste. Arriba muestra la correlación de rango de Spearman de
hiperparámetros muestreados por Hyperband en todas las pruebas durante el entrenamiento. $ cor $ es el
coeficiente de correlación, $ p $ es el valor p para la prueba de hipótesis y $ n $ da
el número de configuraciones entrenadas en ambas fidelidades.
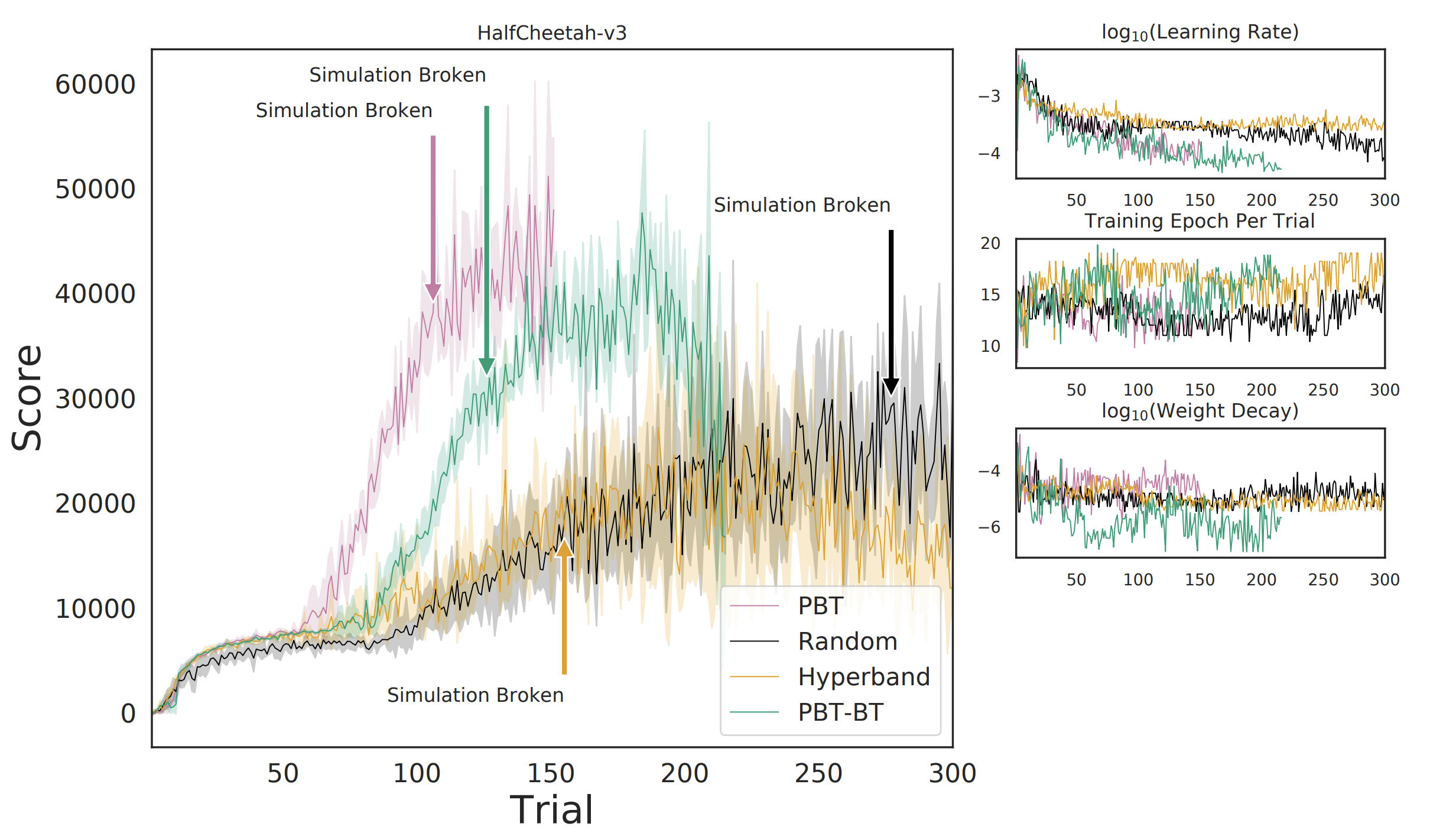
La combinación de AutoML con MBRL supera drásticamente los resultados de SOTA en un par de
Tareas de Mujoco mediante el uso de algoritmos MBRL existentes con dinámica y estática
ajuste de parámetros. Con suficiente ajuste de hiperparámetros, el algoritmo MBRL
(MASCOTAS) literalmente rompe Mujoco. El registro de Mujoco dice algo parecido a:
ADVERTENCIA: Nan, Inf o un valor enorme en QACC a DOF 0. La simulación es inestable. Tiempo = 40,4200.
Esto se correlaciona con la tarea que se resuelve de una manera no intuitiva y explotadora.
manera: las volteretas de Half Cheetah.
Normalmente, se supone que el Half Cheetah corre. Sin embargo, a través del hiperparámetro
tuning, el agente puede experimentar que tropezar y volcarse puede ser
convertido en una voltereta exitosa. Encadenando tales volteretas espalda con espalda
le permite acumular mucha más velocidad de lo que sería posible de otra manera. Tanto, en
De hecho, el simulador no puede seguir el ritmo y se rompe. Esto demuestra que no tenemos
aún exploró todo el potencial de las implementaciones de agentes existentes y que
AutoML puede ser un componente clave para hacerlo. El papel tiene un tamaño mucho, mucho más amplio.
rango de resultados en múltiples entornos, pero eso se lo dejo al lector. La
papel tiene interesantes compensaciones entre optimizar el modelo (aprender el
dinámica) y el controlador (resolviendo el problema de maximización de recompensas).
Además, muestra cómo cambiar dinámicamente los parámetros a lo largo de un
La prueba puede ser útil, como aumentar el horizonte de su modelo a medida que el algoritmo
recopila datos y el modelo se vuelve más preciso. Analizamos en profundidad la
impacto de las decisiones de diseño en los siguientes métodos de ajuste:
- Entrenamiento basado en la población (PBT): un enfoque evolutivo para el ajuste de hiperparámetros, donde los miembros con mejor rendimiento se modifican y reemplazan las configuraciones de peor rendimiento (enlace).
- Entrenamiento basado en la población con retroceso (PBT-BT): Entrenamiento basado en la población donde los agentes pueden regresar a configuraciones pasadas durante el proceso de aprendizaje.
- Hiperbanda: un enfoque basado en bandidos para la optimización de hiperparámetros (enlace).
- Búsqueda aleatoria: un método en el que las configuraciones se generan dentro del espacio de búsqueda de hiperparámetros (ejemplo).
En última instancia, este es un documento que realmente puede hacer avanzar el campo al mostrar
el techo es mucho más alto de lo esperado para los algoritmos actuales de RL profundo y
que se necesitan nuevas tareas de evaluación comparativa para facilitar el desarrollo continuo de
el área de investigación. Sabiendo que la última generación de algoritmos MBRL todavía
tiene un rendimiento sustancial para ser cultivado motiva más interesante
investigación numérica que revisa métodos pasados a medida que se diseña el futuro.
Como el simulador de Mujoco parece estar llegando a su máximo en términos de registro
rendimiento, es hora de que una nueva generación de simuladores y tareas
desarrollos de referencia en el aprendizaje por refuerzo profundo. Al crear nuevas tareas,
Existe una gran oportunidad para acercar nuestros métodos de investigación a la realidad.
Aplicaciones mundiales: un desafío más difícil con un potencial creciente.
saldar.
Esta publicación se basa en el siguiente documento: