

Dos meses después de su debut arrasando en los puntos de referencia de inferencia de MLPerf, las GPU NVIDIA H100 Tensor Core establecieron récords mundiales en cargas de trabajo de IA empresarial en las últimas pruebas de entrenamiento de IA del grupo de la industria.
Juntos, los resultados muestran que H100 es la mejor opción para los usuarios que exigen el máximo rendimiento al crear e implementar modelos avanzados de IA.
MLPerf es el estándar de la industria para medir el rendimiento de la IA. Está respaldado por un amplio grupo que incluye a Amazon, Arm, Baidu, Google, la Universidad de Harvard, Intel, Meta, Microsoft, la Universidad de Stanford y la Universidad de Toronto.
En un benchmark de MLPerf relacionado también publicado hoy, las GPU NVIDIA A100 Tensor Core elevaron el nivel que establecieron el año pasado en computación de alto rendimiento (HPC).
Las GPU H100 (también conocidas como Hopper) subieron el listón en el rendimiento por acelerador en MLPerf Training. Ofrecieron hasta 6,7 veces más rendimiento que las GPU de la generación anterior cuando se enviaron por primera vez a la capacitación de MLPerf. En la misma comparación, las GPU A100 actuales tienen 2,5 veces más potencia, gracias a los avances en el software.
Debido en parte a su Transformer Engine, Hopper se destacó en el entrenamiento del popular modelo BERT para el procesamiento del lenguaje natural. Se encuentra entre los modelos de IA de MLPerf más grandes y con más rendimiento.
MLPerf brinda a los usuarios la confianza para tomar decisiones de compra informadas porque los puntos de referencia cubren las cargas de trabajo de IA más populares de la actualidad: visión por computadora, procesamiento de lenguaje natural, sistemas de recomendación, aprendizaje reforzado y más. Las pruebas son revisadas por pares, por lo que los usuarios pueden confiar en sus resultados.
Las GPU A100 alcanzan un nuevo pico en HPC
En el conjunto separado de puntos de referencia MLPerf HPC, las GPU A100 superaron todas las pruebas de entrenamiento de modelos de IA en cargas de trabajo científicas exigentes que se ejecutan en supercomputadoras. Los resultados muestran la capacidad de la plataforma NVIDIA AI para adaptarse a los desafíos técnicos más difíciles del mundo.
Por ejemplo, las GPU A100 entrenaron modelos de IA en la prueba CosmoFlow para astrofísica 9 veces más rápido que los mejores resultados de hace dos años en la primera ronda de MLPerf HPC. En esa misma carga de trabajo, el A100 también entregó hasta 66 veces más rendimiento por chip que una oferta alternativa.
Los puntos de referencia de HPC entrenan modelos para trabajar en astrofísica, pronóstico del tiempo y dinámica molecular. Se encuentran entre muchos campos técnicos, como el descubrimiento de fármacos, la adopción de IA para avanzar en la ciencia.
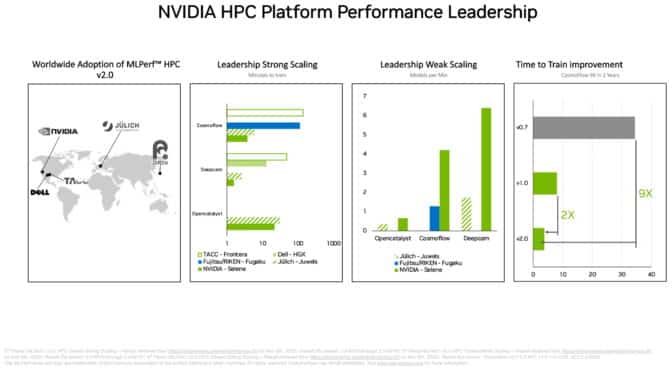
Los centros de supercomputación de Asia, Europa y EE. UU. participaron en la última ronda de pruebas MLPerf HPC. En su debut en los puntos de referencia de DeepCAM, Dell Technologies mostró sólidos resultados con las GPU NVIDIA A100.
Un ecosistema sin igual
En los puntos de referencia de capacitación de IA empresarial, un total de 11 empresas, incluido el servicio en la nube de Microsoft Azure, realizaron presentaciones utilizando las GPU NVIDIA A100, A30 y A40. Los fabricantes de sistemas, incluidos ASUS, Dell Technologies, Fujitsu, GIGABYTE, Hewlett Packard Enterprise, Lenovo y Supermicro, utilizaron un total de nueve sistemas certificados por NVIDIA para sus presentaciones.
En la última ronda, al menos tres empresas se unieron a NVIDIA para presentar los resultados de las ocho cargas de trabajo de capacitación de MLPerf. Esa versatilidad es importante porque las aplicaciones del mundo real a menudo requieren un conjunto de diversos modelos de IA.
Los socios de NVIDIA participan en MLPerf porque saben que es una herramienta valiosa para los clientes que evalúan proveedores y plataformas de IA.
Bajo el capó
La plataforma NVIDIA AI proporciona una pila completa desde chips hasta sistemas, software y servicios. Eso permite mejoras continuas en el rendimiento a lo largo del tiempo.
Por ejemplo, las presentaciones en las últimas pruebas de HPC aplicaron un conjunto de optimizaciones y técnicas de software descritas en un artículo técnico. Juntos, redujeron el tiempo de ejecución en un punto de referencia en 5 veces, de 101 minutos a solo 22 minutos.
Un segundo artículo describe cómo NVIDIA optimizó su plataforma para los puntos de referencia de IA empresarial. Por ejemplo, usamos NVIDIA DALI para cargar y preprocesar de manera eficiente los datos para un punto de referencia de visión por computadora.
Todo el software utilizado en las pruebas está disponible en el repositorio de MLPerf, por lo que cualquiera puede obtener estos resultados de clase mundial. NVIDIA incorpora continuamente estas optimizaciones en contenedores disponibles en NGC, un centro de software para aplicaciones de GPU.