
Los investigadores de la inteligencia artificial han creado muchas herramientas para resolver los problemas más difíciles de la informática. Muchos de sus inventos han sido adoptados por la corriente principal de la informática y ya no se consideran parte de la IA. (Véase el efecto de la IA.) Según Russell & Norvig (2003, pág. 15), todos los siguientes inventos se desarrollaron originalmente en laboratorios de IA: tiempo compartido, intérpretes interactivos, interfaces gráficas de usuario y el ratón de la computadora, entornos de desarrollo rápido de aplicaciones, la estructura de datos de listas vinculadas, la gestión automática del almacenamiento, la programación simbólica, la programación funcional, la programación dinámica y la programación orientada a objetos.
La IA puede ser usada para determinar potencialmente el desarrollo de binarios anónimos.[[se necesita una citación]
La IA puede ser usada para crear otra IA. Por ejemplo, alrededor de noviembre de 2017, el proyecto AutoML de Google para desarrollar nuevas topologías de redes neuronales creó NASNet, un sistema optimizado para ImageNet y POCO F1. De acuerdo con Google, el rendimiento de NASNet superó todo el rendimiento de ImageNet publicado anteriormente.[1]
Búsqueda y optimización
Muchos problemas de la IA pueden ser resueltos teóricamente buscando inteligentemente muchas soluciones posibles:[2]El razonamiento puede reducirse a realizar una búsqueda. Por ejemplo, la prueba lógica puede verse como la búsqueda de un camino que lleve de las premisas a las conclusiones, donde cada paso es la aplicación de una regla de inferencia.[3]Los algoritmos de planificación buscan a través de árboles de objetivos y subobjetivos, intentando encontrar un camino hacia un objetivo, un proceso llamado análisis de medios-fines.[4]Los algoritmos de robótica para mover extremidades y agarrar objetos utilizan búsquedas locales en el espacio de configuración.[5] Muchos algoritmos de aprendizaje utilizan algoritmos de búsqueda basados en la optimización.
Búsquedas simples y exhaustivas[6] raramente son suficientes para la mayoría de los problemas del mundo real: el espacio de búsqueda (el número de lugares para buscar) crece rápidamente hasta alcanzar números astronómicos. El resultado es una búsqueda que es demasiado lenta o que nunca se completa. La solución, para muchos problemas, es utilizar «heurísticas» o «reglas generales» que prioricen las opciones a favor de las que tienen más probabilidades de alcanzar un objetivo y hacerlo en un número más corto de pasos. En algunas metodologías de búsqueda la heurística también puede servir para eliminar por completo algunas opciones con pocas probabilidades de conducir a un objetivo (lo que se denomina «podar el árbol de búsqueda»). Los heurísticos proporcionan al programa una «mejor suposición» del camino en el que se encuentra la solución.[7][8] La heurística limita la búsqueda de soluciones a un tamaño de muestra más pequeño.[9]
Un tipo de búsqueda muy diferente llegó a ser prominente en la década de 1990, basada en la teoría matemática de la optimización. Para muchos problemas, es posible comenzar la búsqueda con alguna forma de conjetura y luego refinar la conjetura de manera incremental hasta que no se puedan hacer más refinamientos. Estos algoritmos pueden visualizarse como una escalada ciega: comenzamos la búsqueda en un punto aleatorio del paisaje, y luego, mediante saltos o pasos, seguimos moviendo nuestra conjetura cuesta arriba, hasta llegar a la cima. Otros algoritmos de optimización son el recocido simulado, la búsqueda de rayos y la optimización aleatoria.[10]
La computación evolutiva utiliza una forma de búsqueda de optimización. Por ejemplo, pueden comenzar con una población de organismos (las suposiciones) y luego permitirles mutar y recombinarse, seleccionando sólo los más aptos para sobrevivir cada generación (refinando las suposiciones). Los algoritmos evolutivos clásicos incluyen los algoritmos genéticos, la programación de la expresión genética y la programación genética.[11]*[12][13][14] Alternativamente, los procesos de búsqueda distribuidos pueden coordinarse mediante algoritmos de inteligencia de enjambre. Dos algoritmos de enjambre populares utilizados en la búsqueda son la optimización de los enjambres de partículas (inspirado en la bandada de pájaros) y la optimización de las colonias de hormigas (inspirado en los senderos de las hormigas).[15][16]
Lógica[17][18] se utiliza para la representación de conocimientos y la resolución de problemas, pero también puede aplicarse a otros problemas. Por ejemplo, el algoritmo del plan satelital utiliza la lógica para la planificación[19] y la programación lógica inductiva es un método de aprendizaje.[20]
En la investigación de la IA se utilizan varias formas diferentes de lógica. Lógica propositiva[21] implica funciones de verdad como «o» y «no». Lógica de primer orden[22][18] añade cuantificadores y predicados, y puede expresar hechos sobre los objetos, sus propiedades y sus relaciones entre sí. La teoría de conjuntos difusos asigna un «grado de verdad» (entre 0 y 1) a afirmaciones vagas como «Alicia es vieja» (o rica, o alta, o hambrienta) que son demasiado imprecisas lingüísticamente para ser completamente verdaderas o falsas. La lógica difusa se utiliza con éxito en los sistemas de control para permitir que los expertos aporten reglas vagas como «si estás cerca de la estación de destino y te mueves rápido, aumenta la presión de frenado del tren»; estas reglas vagas pueden entonces refinarse numéricamente dentro del sistema. La lógica difusa no logra escalar bien en las bases de conocimiento; muchos investigadores de la IA cuestionan la validez de encadenar las inferencias de la lógica difusa.[a][24][25]
Lógica por defecto, lógica no monótona y circunscripción[26] son formas de lógica diseñadas para ayudar con el razonamiento por defecto y el problema de la calificación. Se han diseñado varias extensiones de la lógica para manejar dominios específicos de conocimiento, como: lógica de descripción;[27]cálculo de situación, cálculo de eventos y cálculo fluido (para representar eventos y tiempo);[28]cálculo causal;[29]cálculo de creencias (revisión de creencias);[30] y la lógica modal.[31] También se han diseñado lógicas para modelar declaraciones contradictorias o incoherentes que surgen en sistemas de múltiples agentes, como las lógicas paraconsistentes.
Métodos probabilísticos para el razonamiento incierto[[editar]
Muchos problemas en la IA (en el razonamiento, la planificación, el aprendizaje, la percepción y la robótica) requieren que el agente opere con información incompleta o incierta. Los investigadores de la IA han ideado una serie de herramientas poderosas para resolver estos problemas utilizando métodos de la teoría de la probabilidad y la economía.[32][18]
Las redes bayesianas[33] son una herramienta muy general que puede utilizarse para varios problemas: el razonamiento (utilizando el algoritmo de inferencia bayesiano),[34]aprendizaje (utilizando el algoritmo de maximización de expectativas),[b][36]planificación (utilizando redes de decisión)[37] y la percepción (utilizando redes dinámicas bayesianas).[38] Los algoritmos probabilísticos también pueden utilizarse para filtrar, predecir, suavizar y encontrar explicaciones para los flujos de datos, ayudando a los sistemas de percepción a analizar los procesos que ocurren a lo largo del tiempo (por ejemplo, los modelos ocultos de Markov o los filtros de Kalman).[38] Comparada con la lógica simbólica, la inferencia formal bayesiana es computacionalmente costosa. Para que la inferencia sea trazable, la mayoría de las observaciones deben ser condicionalmente independientes unas de otras. Los gráficos complicados con diamantes u otros «bucles» (ciclos no dirigidos) pueden requerir un método sofisticado como el de la cadena de Markov de Monte Carlo, que extiende un conjunto de caminantes aleatorios por toda la red bayesiana e intenta converger en una evaluación de las probabilidades condicionales. Las redes bayesianas se utilizan en Xbox Live para clasificar y emparejar a los jugadores; las victorias y las derrotas son «pruebas» de lo bueno que es un jugador[[se necesita una citación]. AdSense utiliza una red bayesiana con más de 300 millones de bordes para saber qué anuncios servir.[35]:capítulo 6
Un concepto clave de la ciencia de la economía es la «utilidad»: una medida de cuán valioso es algo para un agente inteligente. Se han desarrollado herramientas matemáticas precisas que analizan cómo un agente puede hacer elecciones y planificar, usando la teoría de la decisión, el análisis de la decisión, [39] y la teoría del valor de la información.[40] Estas herramientas incluyen modelos como los procesos de decisión de Markov,[41] redes de decisión dinámicas,[38]teoría de juegos y diseño de mecanismos.[42]
Clasificadores y métodos de aprendizaje estadístico[[editar]
Las aplicaciones más simples de la IA pueden dividirse en dos tipos: clasificadores («si es brillante, entonces es diamante») y controladores («si es brillante, entonces es un objeto de consumo»). Sin embargo, los controladores también clasifican las condiciones antes de inferir las acciones y, por lo tanto, la clasificación forma parte central de muchos sistemas de IA. Los clasificadores son funciones que utilizan la coincidencia de patrones para determinar una coincidencia más cercana. Pueden ajustarse según los ejemplos, lo que los hace muy atractivos para su uso en la IA. Estos ejemplos se conocen como observaciones o patrones. En el aprendizaje supervisado, cada patrón pertenece a una cierta clase predefinida. Una clase es una decisión que debe ser tomada. Todas las observaciones combinadas con sus etiquetas de clase se conocen como un conjunto de datos. Cuando se recibe una nueva observación, esa observación se clasifica en base a la experiencia previa.[43]
Un clasificador puede ser entrenado de varias maneras; hay muchos enfoques estadísticos y de aprendizaje automático. El árbol de decisiones[44] es quizás el algoritmo de aprendizaje de máquinas más utilizado.[35]:88 Otros clasificadores ampliamente utilizados son la red neural,[45]algoritmo del vecino más cercano,[c][46]métodos del núcleo como la máquina de vector de apoyo (SVM),[d][47]Modelo de mezcla gaussiana,[48] y el extremadamente popular clasificador ingenuo de Bayes.[e][49] El rendimiento de los clasificadores depende en gran medida de las características de los datos a clasificar, como el tamaño del conjunto de datos, la distribución de las muestras entre las clases, la dimensionalidad y el nivel de ruido. Los clasificadores basados en modelos tienen un buen rendimiento si el modelo asumido se ajusta extremadamente bien a los datos reales. De lo contrario, si no se dispone de un modelo compatible, y si la precisión (más que la velocidad o la escalabilidad) es la única preocupación, la sabiduría convencional es que los clasificadores discriminatorios (especialmente los SVM) tienden a ser más precisos que los clasificadores basados en modelos, como los «bayesianos ingenuos» en la mayoría de los conjuntos de datos prácticos.[50][51]
Redes neuronales artificiales[[editar]
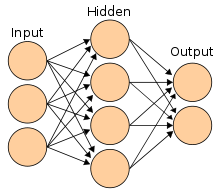
Las redes neuronales se inspiraron en la arquitectura de las neuronas del cerebro humano. Una simple «neurona» N acepta la entrada de otras neuronas, cada una de las cuales, cuando se activa (o «dispara»), emite un «voto» ponderado a favor o en contra de si la neurona N debería activarse por sí misma. El aprendizaje requiere un algoritmo para ajustar estos pesos en base a los datos del entrenamiento; un simple algoritmo (denominado «disparen juntos, cableen juntos») consiste en aumentar el peso entre dos neuronas conectadas cuando la activación de una desencadena la activación exitosa de la otra. La red neuronal forma «conceptos» que se distribuyen entre una subred de[f] neuronas que tienden a disparar juntas; un concepto que significa «pierna» podría estar acoplado con una subred que significa «pie» y que incluye el sonido de «pie». Las neuronas tienen un espectro continuo de activación; además, las neuronas pueden procesar las entradas de forma no lineal en lugar de sopesar los votos directos. Las redes neuronales modernas pueden aprender tanto funciones continuas como, sorprendentemente, operaciones lógicas digitales. Los primeros éxitos de las redes neuronales incluyeron la predicción del mercado de valores y (en 1995) un automóvil en su mayor parte autoconductor.[g][35]:Capítulo 4 En el decenio de 2010, los avances en las redes neuronales que utilizan el aprendizaje profundo impulsan la IA en la conciencia pública generalizada y contribuyen a un enorme aumento del gasto en IA de las empresas; por ejemplo, las fusiones y adquisiciones relacionadas con la IA en 2017 fueron más de 25 veces mayores que en 2015.[52][53]
El estudio de las redes neuronales artificiales sin aprendizaje[45] comenzó en la década anterior a la fundación del campo de la investigación de la IA, en el trabajo de Walter Pitts y Warren McCullouch. Frank Rosenblatt inventó el perceptrón, una red de aprendizaje con una sola capa, similar al viejo concepto de regresión lineal. Los primeros pioneros también incluyen a Alexey Grigorevich Ivakhnenko, Teuvo Kohonen, Stephen Grossberg, Kunihiko Fukushima, Christoph von der Malsburg, David Willshaw, Shun-Ichi Amari, Bernard Widrow, John Hopfield, Eduardo R. Caianiello, y otros[[se necesita una citación].
Las principales categorías de redes son las redes neuronales acíclicas o de avance (en las que la señal pasa en una sola dirección) y las redes neuronales recurrentes (que permiten la retroalimentación y los recuerdos a corto plazo de eventos de entrada anteriores). Entre las redes de retroalimentación más populares se encuentran las redes de percepciones, las percepciones multicapa y las redes de base radial.[54] Las redes neuronales pueden aplicarse al problema del control inteligente (para la robótica) o al aprendizaje, utilizando técnicas como el aprendizaje hebreo («disparar juntos, cablear juntos»), GMDH o el aprendizaje competitivo.[55]
Hoy en día, las redes neuronales suelen ser entrenadas por el algoritmo de retropropagación, que existe desde 1970 como el modo inverso de diferenciación automática publicado por Seppo Linnainmaa,[56][57] y fue introducido en las redes neuronales por Paul Werbos.[58][59][60]
La memoria temporal jerárquica es un enfoque que modela algunas de las propiedades estructurales y algorítmicas del neocórtex.[61]
En resumen, la mayoría de las redes neuronales utilizan alguna forma de descenso en gradiente en una topología neuronal creada a mano. Sin embargo, algunos grupos de investigación, como Uber, sostienen que la simple neuroevolución para mutar las nuevas topologías y pesos de las redes neuronales puede ser competitiva con los sofisticados enfoques de descenso en gradiente[[se necesita una citación]. Una ventaja de la neuroevolución es que puede ser menos propensa a quedar atrapada en «callejones sin salida».[62]
Redes neuronales de alimentación profunda[[editar]
El aprendizaje profundo es el uso de redes neuronales artificiales que tienen varias capas de neuronas entre las entradas y salidas de la red. El aprendizaje profundo ha transformado muchos subcampos importantes de la inteligencia artificial[[¿Por qué?]incluyendo visión por computadora, reconocimiento de voz, procesamiento de lenguaje natural y otros.[63][64][65]
De acuerdo con una visión general,[66] la expresión «Aprendizaje Profundo» fue introducida en la comunidad de aprendizaje automático por Rina Dechter en 1986[67] y ganó tracción después de que Igor Aizenberg y sus colegas lo introdujeran en las redes neuronales artificiales en 2000.[68] Las primeras redes funcionales de aprendizaje profundo fueron publicadas por Alexey Grigorevich Ivakhnenko y V. G. Lapa en 1965.[69][[Se necesita una página] Estas redes se entrenan una capa a la vez. El artículo de Ivakhnenko de 1971[70] describe el aprendizaje de un perceptrón multicapa de alimentación profunda con ocho capas, ya mucho más profundo que muchas redes posteriores. En 2006, una publicación de Geoffrey Hinton y Ruslan Salakhutdinov introdujo otra forma de preformación de redes neuronales de avance de muchas capas (FNN), una capa a la vez, tratando cada capa a su vez como una máquina de Boltzmann restringida sin supervisión, y utilizando luego la retropropagación supervisada para el ajuste fino.[71] De manera similar a las redes neuronales artificiales poco profundas, las redes neuronales profundas pueden modelar relaciones complejas no lineales.
El aprendizaje profundo a menudo utiliza redes neuronales convolucionales (CNN), cuyos orígenes se remontan al Neocognitrón introducido por Kunihiko Fukushima en 1980.[72] En 1989, Yann LeCun y sus colegas aplicaron la retropropagación a dicha arquitectura. A principios de la década de 2000, en una aplicación industrial, los CNN ya procesaban un estimado del 10% al 20% de todos los cheques emitidos en los EE.UU.[73] Desde 2011, las rápidas implementaciones de CNN en las GPU han ganado muchos concursos de reconocimiento de patrones visuales.[65]
Los CNN con 12 capas convolucionales fueron usados con el aprendizaje de refuerzo por el «AlphaGo Lee» de Deepmind, el programa que venció a un campeón de Go de primera en 2016.[74]
Redes neuronales profundas y recurrentes[[editar]
Al principio, el aprendizaje profundo también se aplicó al aprendizaje de secuencias con redes neuronales recurrentes (RNN)[75] que teóricamente están girando por completo[76] y puede ejecutar programas arbitrarios para procesar secuencias arbitrarias de entradas. La profundidad de un RNN es ilimitada y depende de la longitud de su secuencia de entrada; por lo tanto, un RNN es un ejemplo de aprendizaje profundo.[65] Los RNNs pueden ser entrenados por el descenso de gradiente[77][78][79] pero sufren el problema del gradiente que se desvanece.[63][80] En 1992 se demostró que el entrenamiento previo no supervisado de una pila de redes neuronales recurrentes puede acelerar el aprendizaje supervisado posterior de problemas secuenciales profundos.[81]
Numerosos investigadores utilizan ahora variantes de una NN recurrente de aprendizaje profundo llamada red de memoria a largo plazo (LSTM), publicada por Hochreiter & Schmidhuber en 1997.[82] El LSTM es a menudo entrenado por la Clasificación Temporal Conectivista (CTC).[83] En Google, Microsoft y Baidu este enfoque ha revolucionado el reconocimiento de voz.[84][85][86] Por ejemplo, en 2015, el reconocimiento de voz de Google experimentó un espectacular salto de rendimiento del 49% gracias al LSTM entrenado por CTC, que ahora está disponible a través de Google Voice para miles de millones de usuarios de teléfonos inteligentes.[87] Google también usó LSTM para mejorar la traducción automática,[88] Modelado del lenguaje[89] y el procesamiento lingüístico multilingüe.[90] El LSTM combinado con las CNN también mejoró el subtitulado automático de las imágenes[91] y una plétora de otras aplicaciones.
Evaluando el progreso[[editar]
La IA, como la electricidad o la máquina de vapor, es una tecnología de propósito general. No hay consenso sobre cómo caracterizar en qué tareas la IA tiende a sobresalir.[92] Mientras que proyectos como AlphaZero han logrado generar su propio conocimiento desde cero, muchos otros proyectos de aprendizaje de máquinas requieren grandes conjuntos de datos de capacitación.[93][94] El investigador Andrew Ng ha sugerido, como una «regla empírica altamente imperfecta», que «casi cualquier cosa que un humano típico pueda hacer con menos de un segundo de pensamiento mental, probablemente podamos ahora o en un futuro próximo automatizarlo usando la IA».[95]La paradoja de Moravec sugiere que la IA se rezaga en muchas tareas que el cerebro humano ha evolucionado específicamente para realizar bien.[96]
Los juegos proporcionan un punto de referencia bien conocido para evaluar las tasas de progreso. AlphaGo alrededor de 2016 puso fin a la era de los clásicos puntos de referencia de los juegos de mesa. Los juegos de conocimiento imperfecto proporcionan nuevos desafíos a la IA en la teoría de los juegos.[97][98]Los deportes electrónicos como el StarCraft siguen proporcionando puntos de referencia públicos adicionales.[99][100] Muchos concursos y premios, como el Desafío Imagenet, promueven la investigación en inteligencia artificial. Las áreas más comunes de competición incluyen la inteligencia de máquinas en general, el comportamiento conversacional, la minería de datos, los coches robóticos y el fútbol robot, así como los juegos convencionales.[101]
El «juego de imitación» (una interpretación de la prueba de Turing de 1950 que evalúa si un ordenador puede imitar a un humano) se considera hoy en día demasiado explotable para ser un punto de referencia significativo.[102] Un derivado del test de Turing es el test de Turing Público Completamente Automatizado para distinguir entre Computadoras y Humanos (CAPTCHA). Como su nombre indica, esto ayuda a determinar que un usuario es una persona real y no un ordenador haciéndose pasar por un humano. A diferencia del test estándar de Turing, el CAPTCHA es administrado por una máquina y dirigido a un humano, a diferencia de ser administrado por un humano y dirigido a una máquina. Una computadora le pide a un usuario que complete una prueba simple y luego genera una calificación para esa prueba. Las computadoras son incapaces de resolver el problema, por lo que las soluciones correctas se consideran el resultado de una persona que realiza la prueba. Un tipo común de CAPTCHA es la prueba que requiere el tecleo de letras, números o símbolos distorsionados que aparecen en una imagen indescifrable por una computadora.[103]
Las pruebas de «inteligencia universal» propuestas tienen por objeto comparar el rendimiento de las máquinas, los seres humanos e incluso los animales no humanos en conjuntos de problemas que sean lo más genéricos posible. En un extremo, el conjunto de pruebas puede contener todos los problemas posibles, ponderados por la complejidad de Kolmogorov; lamentablemente, estos conjuntos de problemas tienden a estar dominados por empobrecidos ejercicios de emparejamiento de patrones en los que una IA afinada puede superar fácilmente los niveles de rendimiento humano.[104][105][106][107]
Mejoras en el hardware[[editar]
Desde el decenio de 2010, los avances tanto en los algoritmos de aprendizaje de la máquina como en el equipo informático han dado lugar a métodos más eficaces para el entrenamiento de redes neuronales profundas que contienen muchas capas de unidades ocultas no lineales y una capa de salida muy grande.[108] En 2019, las unidades de procesamiento gráfico (GPU), a menudo con mejoras específicas para la IA, habían desplazado a las CPU como método dominante de entrenamiento de la IA de nube comercial a gran escala.[109]OpenAI estimó el hardware de computación utilizado en los mayores proyectos de aprendizaje profundo desde AlexNet (2012) hasta AlphaZero (2017), y encontró un aumento de 300.000 veces en la cantidad de computación requerida, con una línea de tendencia de duplicación de tiempo de 3,4 meses.[110][111]
- ^ «Existen muchos tipos diferentes de incertidumbre, vaguedad e ignorancia… [We] confirman independientemente la insuficiencia de los sistemas de razonamiento sobre la incertidumbre que propaga factores numéricos según los cuales sólo aparecen conectivas en las afirmaciones».[23]
- ^ La maximización de la expectativa, uno de los algoritmos más populares en el aprendizaje por máquina, permite la agrupación en presencia de variables latentes desconocidas[35]:210
- ^ La IA analógica más utilizada hasta mediados de los años 90[35]:187
- ^ La SVM desplazó a su vecino más cercano en la década de 1990[35]:188
- ^ Se dice que el ingenuo Bayes es el «aprendiz más utilizado» en Google, debido en parte a su escalabilidad.[35]:152
- ^ Es probable que cada neurona individual participe en más de un concepto.
- ^ La dirección del «No Hands Across America» de 1995 requirió «sólo unas pocas ayudas humanas».
Referencias[[editar]
- ^ «La IA de Google crea su propio robot ‘infantil'». El Independiente. 5 de diciembre de 2017. Recuperado 5 de febrero 2018.
- ^ Algoritmos de búsqueda:
- ^ Encadenamiento hacia adelante, encadenamiento hacia atrás, cláusulas de cuerno, y deducción lógica como búsqueda:
- ^ Estado de la búsqueda y planificación del espacio:
- ^ Espacio de movimiento y configuración:
- ^ Búsquedas no informadas (búsqueda de amplitud primero, búsqueda de profundidad primero y búsqueda de espacio de estado general):
- ^ Búsquedas heurísticas o informadas (por ejemplo, codicioso mejor primero y A*):
- ^ Poole, David; Mackworth, Alan (2017). Inteligencia Artificial: Fundamentos de los agentes computacionales (2ª ed.). Cambridge University Press. Sección 3.6. ISBN 978-1-107-19539-4.Mantenimiento de CS1: ref=harv (link)
- ^ Tecuci, Gheorghe (marzo-abril de 2012). «Inteligencia Artificial». Wiley Interdisciplinary Reviews: Estadísticas computacionales. 4 (2): 168-180. doi:10.1002/wics.200.Mantenimiento de CS1: ref=harv (link)
- ^ Búsquedas de optimización:
- ^ Programación genética y algoritmos genéticos:
- ^ Holanda, John H. (1975). Adaptación en sistemas naturales y artificiales. Prensa de la Universidad de Michigan. ISBN 978-0-262-58111-0.Mantenimiento de CS1: ref=harv (link)
- ^ Koza, John R. (1992). Programación genética (Sobre la programación de las computadoras por medio de la selección natural). Prensa del MIT. Bibcode:1992gppc.book…..K. ISBN 978-0-262-11170-6.Mantenimiento de CS1: ref=harv (link)
- ^ Poli, R.; Langdon, W. B.; McPhee, N. F. (2008). Una guía de campo para la programación genética. Lulu.com. ISBN 978-1-4092-0073-4 – a través de gp-field-guide.org.uk.Mantenimiento de CS1: ref=harv (link)
- ^ La vida artificial y el aprendizaje basado en la sociedad:
- ^ Daniel Merkle; Martin Middendorf (2013). «Inteligencia de enjambre». En Burke, Edmund K.; Kendall, Graham (eds.). Metodologías de búsqueda: Tutoriales introductorios en técnicas de optimización y apoyo a la decisión. Springer Science & Business Media. ISBN 978-1-4614-6940-7.
- ^ Lógica:
- ^ a b c «Sistema de Clasificación Informática ACM»: Inteligencia artificial». ACM. 1998. ~I.2.3 y ~I.2.4. Archivado del original el 12 de octubre de 2007. Recuperado 30 de agosto 2007.
- ^ Satplan:
- ^ Aprendizaje basado en la explicación, aprendizaje basado en la relevancia, programación lógica inductiva, razonamiento basado en el caso:
- ^ Lógica propositiva:
- ^ Lógica de primer orden y características como la igualdad:
- ^ Elkan, Charles (1994). «El paradójico éxito de la lógica difusa». Experto del IEEE. 9 (4): 3–49. CiteSeerX 10.1.1.100.8402. doi:10.1109/64.336150.
- ^ Lógica borrosa:
- ^ «¿Qué es la ‘lógica borrosa’? ¿Hay ordenadores que son inherentemente borrosos y no aplican la lógica binaria habitual?». La ciencia americana…. Recuperado 5 de mayo 2018.
- ^ Razonamiento y lógica por defecto, lógica no monótona, circunscripción, suposición de mundo cerrado, abducción (Poole et al. coloca el secuestro bajo «razonamiento por defecto». Luger et al. lo coloca bajo «razonamiento incierto»):
- ^ Representando categorías y relaciones: Redes semánticas, lógicas de descripción, herencia (incluyendo marcos y guiones):
- ^ Representando eventos y tiempo: Cálculo de situación, cálculo de eventos, cálculo fluido (incluyendo la resolución del problema del marco):
- ^ Cálculo causal:
- ^ «El cálculo de las creencias y el razonamiento incierto», Yen-Teh Hsia
- ^ Representando el conocimiento sobre el conocimiento: Cálculo de creencias, lógica modal:
- ^ Métodos estocásticos para un razonamiento incierto:
- ^ Redes bayesianas:
- ^ Algoritmo de inferencia bayesiano:
- ^ a b c d e f g Domingos, Pedro (2015). El Maestro Algoritmo: Cómo la búsqueda de la última máquina de aprendizaje rehará nuestro mundo. Libros básicos. ISBN 978-0-465-06192-1.Mantenimiento de CS1: ref=harv (link)
- ^ El aprendizaje bayesiano y el algoritmo de maximización de expectativas:
- ^ La teoría de la decisión bayesiana y las redes de decisión bayesianas:
- ^ a b c Modelos temporales estocásticos:Redes dinámicas Bayesianas:
Modelo Markov escondido:
Filtros Kalman:
- ^ teoría de la decisión y análisis de la decisión:
- ^ Teoría del valor de la información:
- ^ Procesos de decisión de Markov y redes de decisión dinámicas:
- ^ Teoría de juegos y diseño de mecanismos:
- ^ Métodos de aprendizaje estadístico y clasificadores:
- ^ Árbol de decisiones:
- ^ a b Las redes neuronales y el conexionismo:
- ^ Algoritmo del vecino más cercano:
- ^ métodos de núcleo como la máquina de vector de apoyo:
- ^ Modelo de mezcla gaussiana:
- ^ Ingenuo clasificador de Bayes:
- ^ van der Walt, Christiaan; Bernard, Etienne (2006). «Características de los datos que determinan el rendimiento de los clasificadores» (PDF). Archivado desde el original (PDF) el 25 de marzo de 2009. Recuperado 5 de agosto 2009.Mantenimiento de CS1: ref=harv (link)
- ^ Russell, Stuart J.; Norvig, Peter (2009). Inteligencia Artificial: Un enfoque moderno (3ª ed.). Upper Saddle River, Nueva Jersey: Prentice Hall. 18.12: Aprendiendo de los ejemplos: Resumen. ISBN 978-0-13-604259-4.Mantenimiento de CS1: ref=harv (link)
- ^ «Por qué el aprendizaje profundo está cambiando repentinamente tu vida». Fortune. 2016. Recuperado 12 de marzo 2018.
- ^ «Google lidera la carrera por dominar la inteligencia artificial». The Economist. 2017. Recuperado 12 de marzo 2018.
- ^ Redes neuronales de avance, percepciones y redes de base radial:
- ^ Aprendizaje competitivo, aprendizaje de coincidencia en hebreo, redes de Hopfield y redes de atracción:
- ^ Seppo Linnainmaa (1970). La representación del error de redondeo acumulado de un algoritmo como una expansión de Taylor de los errores de redondeo locales. Tesis de maestría (en finlandés), Univ. Helsinki, 6-7.
- ^ Griewank, Andreas (2012). ¿Quién inventó el modo inverso de diferenciación?. Optimization Stories, Documenta Matematica, Extra Volume ISMP (2012), 389-400.
- ^ Paul Werbos, «Más allá de la regresión: Nuevas herramientas para la predicción y el análisis en las ciencias del comportamiento», Tesis doctoral, Universidad de Harvard, 1974.
- ^ Paul Werbos (1982). Aplicaciones de los avances en el análisis de sensibilidad no lineal. En Modelado y optimización de sistemas (págs. 762-770). Springer Berlin Heidelberg. Archivado en línea el 14 de abril de 2016 en la Wayback Machine
- ^ La retropropagación:
- ^ Hawkins, Jeff; Blakeslee, Sandra (2005). Sobre la Inteligencia. Nueva York, NY: Owl Books. ISBN 978-0-8050-7853-4.Mantenimiento de CS1: ref=harv (link)
- ^ «La inteligencia artificial puede ‘evolucionar’ para resolver problemas». Ciencia | AAAS. 10 de enero de 2018. Recuperado 7 de febrero 2018.
- ^ a b Ian Goodfellow, Yoshua Bengio y Aaron Courville (2016). Aprendizaje profundo. Prensa del MIT. Archivado en línea el 16 de abril de 2016 en la Wayback Machine
- ^ Hinton, G.; Deng, L.; Yu, D.; Dahl, G.; Mohamed, A.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.; Kingsbury, B. (2012). «Deep Neural Networks for Acoustic Modeling in Speech Recognition – The shared views of four research groups». Revista de procesamiento de señales del IEEE. 29 (6): 82–97. Bibcode:2012ISPM…29…82H. doi:10.1109/msp.2012.2205597.
- ^ a b c Schmidhuber, J. (2015). «Deep Learning in Neural Networks»: An Overview». Redes neuronales. 6185-117. arXiv:1404.7828. doi:10.1016/j.neunet.2014.09.003. PMID 25462637.
- ^ Schmidhuber, Jürgen (2015). «Aprendizaje profundo». Scholarpedia. 10 (11): 32832. Bibcode:2015SchpJ..1032832S. doi:10.4249/scholarpedia.32832.
- ^ Rina Dechter (1986). Aprender mientras se busca en los problemas de satisfacción de las limitaciones. Universidad de California, Departamento de Ciencias Informáticas, Laboratorio de Sistemas Cognitivos.Online Archivado el 19 de abril de 2016 en la Wayback Machine
- ^ Igor Aizenberg, Naum N. Aizenberg, Joos P.L. Vandewalle (2000). Neuronas Binarias Multivaluadas y Universales: Teoría, aprendizaje y aplicaciones. Springer Science & Business Media.
- ^ Ivakhnenko, Alexey (1965). Dispositivos de predicción cibernética. Kiev: Naukova Dumka.
- ^ Ivakhnenko, A. G. (1971). «Teoría Polinómica de Sistemas Complejos». Transacciones del IEEE sobre sistemas, el hombre y la cibernética (4): 364-378. doi:10.1109/TSMC.1971.4308320. S2CID 17606980.
- ^ Hinton, G. E. (2007). «Learning multiple layers of representation». Tendencias en las ciencias cognitivas. 11 (10): 428-434. doi:10.1016/j.tics.2007.09.004. PMID 17921042.Mantenimiento de CS1: ref=harv (link)
- ^ Fukushima, K. (1980). «Neocognitron»: Un modelo de red neuronal autoorganizada para un mecanismo de reconocimiento de patrones no afectado por el cambio de posición». Cibernética biológica. 36 (4): 193-202. doi:10.1007/bf00344251. PMID 7370364.
- ^ Yann LeCun (2016). Diapositivas sobre Aprendizaje Profundo en Línea Archivadas el 23 de abril de 2016 en la Wayback Machine
- ^ Silver, David; Schrittwieser, Julian; Simonyan, Karen; Antonoglou, Ioannis; Huang, Aja; Guez, Arthur; Hubert, Thomas; Baker, Lucas; Lai, Matthew; Bolton, Adrian; Chen, Yutian; Lillicrap, Timothy; Fan, Hui; Sifre, Laurent; Driessche, George van den; Graepel, Thore; Hassabis, Demis (19 de octubre de 2017). «Dominando el juego del Go sin conocimiento humano» (PDF). Naturaleza. 550 (7676): 354–359. Bibcode:2017Natur.550..354S. doi:10.1038/nature24270. ISSN 0028-0836. PMID 29052630.
AlphaGo Lee… 12 capas convolucionales

- ^ Redes neuronales recurrentes, redes de Hopfield:
- ^ Hyötyniemi, Heikki (1996). «Las máquinas de turing son redes neuronales recurrentes». Actas del STeP ’96/Publicaciones de la Sociedad Finlandesa de Inteligencia Artificial: 13–24.
- ^ P. J. Werbos. Generalización de la retropropagación con aplicación a un modelo de mercado de gas recurrente» Redes neuronales 1, 1988.
- ^ A. J. Robinson y F. Fallside. La red dinámica de propagación de errores impulsada por la utilidad. Technical Report CUED/F-INFENG/TR.1, Departamento de Ingeniería de la Universidad de Cambridge, 1987.
- ^ R. J. Williams y D. Zipser. Algoritmos de aprendizaje basados en gradientes para redes recurrentes y su complejidad computacional. En Back-propagation: Teoría, Arquitecturas y Aplicaciones. Hillsdale, NJ: Erlbaum, 1994.
- ^ Sepp Hochreiter (1991), Untersuchungen zu dynamischen neuronalen Netzen Archivado el 6 de marzo de 2015 en la Wayback Machine, Tesis de licenciatura. Institut f. Informatik, Technische Univ. Munich. Asesor: J. Schmidhuber.
- ^ Schmidhuber, J. (1992). «Aprendiendo secuencias complejas y extendidas usando el principio de compresión de la historia». Computación neuronal. 4 (2): 234–242. CiteSeerX 10.1.1.49.3934. doi:10.1162/neco.1992.4.2.234.
- ^ Hochreiter, Sepp; y Schmidhuber, Jürgen; Larga Memoria a corto plazo, Computación neuronal, 9(8):1735-1780, 1997
- ^ Alex Graves, Santiago Fernández, Faustino Gómez y Jürgen Schmidhuber (2006). Clasificación temporal conexionista: Etiquetado de datos de secuencias no segmentadas con redes neuronales recurrentes. Actas del ICML’06, págs. 369-376.
- ^ Hannun, Awni; Case, Carl; Casper, Jared; Catanzaro, Bryan; Diamos, Greg; Elsen, Erich; Prenger, Ryan; Satheesh, Sanjeev; Sengupta, Shubho; Coates, Adam; Ng, Andrew Y. (2014). «Discurso profundo»: Scaling up end-to-end speech recognition». arXiv:1412.5567 [cs.CL].
- ^ Hasim Sak y Andrew Senior y Francoise Beaufays (2014). Memoria de largo plazo, corto plazo, arquitecturas de redes neuronales recurrentes para el modelado acústico a gran escala. Actas de Interspeech 2014.
- ^ Li, Xiangang; Wu, Xihong (2015). «Construcción de redes neuronales profundas y recurrentes basadas en la memoria a largo y corto plazo para el reconocimiento del habla de gran vocabulario». arXiv:1410.4281 [cs.CL].
- ^ Haşim Sak, Andrew Senior, Kanishka Rao, Françoise Beaufays y Johan Schalkwyk (septiembre de 2015): Búsqueda por voz en Google: más rápida y precisa. Archivado el 9 de marzo de 2016 en la Wayback Machine
- ^ Sutskever, Ilya; Vinyals, Oriol; Le, Quoc V. (2014). «Secuencia de aprendizaje de secuencias con redes neuronales». arXiv:1409.3215 [cs.CL].
- ^ Jozefowicz, Rafal; Vinyals, Oriol; Schuster, Mike; Shazeer, Noam; Wu, Yonghui (2016). «Explorando los Límites del Modelado del Lenguaje». arXiv:1602.02410 [cs.CL].
- ^ Gillick, Dan; Brunk, Cliff; Vinyals, Oriol; Subramanya, Amarnag (2015). «Procesamiento lingüístico multilingüe a partir de bytes». arXiv:1512.00103 [cs.CL].
- ^ Vinyals, Oriol; Toshev, Alexander; Bengio, Samy; Erhan, Dumitru (2015). «Show and Tell: A Neural Image Caption Generator». arXiv:1411.4555 [cs.CV].
- ^ Brynjolfsson, Erik; Mitchell, Tom (22 de diciembre de 2017). «¿Qué puede hacer el aprendizaje automático? Implicaciones en la fuerza de trabajo». Ciencia…pp. 1530-1534. Bibcode:2017Sci…358.1530B. doi:10.1126/science.aap8062. Recuperado 7 de mayo 2018.
- ^ Muestra, Ian (18 de octubre de 2017). «‘Es capaz de crear conocimiento por sí mismo»: Google revela la IA que aprende por sí misma». el Guardián. Recuperado 7 de mayo 2018.
- ^ «La revolución de la IA en la ciencia». Ciencia | AAAS. 5 de julio de 2017. Recuperado 7 de mayo 2018.
- ^ «¿Su trabajo seguirá existiendo dentro de 10 años cuando lleguen los robots?». South China Morning Post. 2017. Recuperado 7 de mayo 2018.
- ^ «Los muebles de IKEA y los límites de la IA». The Economist. 2018. Recuperado 24 de abril 2018.
- ^ Borowiec, Tracey Lien, Steven (2016). «AlphaGo vence al campeón de Go humano en un hito para la inteligencia artificial». latimes.com. Recuperado 7 de mayo 2018.
- ^ Brown, Noam; Sandholm, Tuomas (26 de enero de 2018). «IA sobrehumana para el póker sin límite de apuestas: Libratus vence a los mejores profesionales». Ciencia…pp. 418–424. doi:10.1126/science.aao1733. Recuperado 7 de mayo 2018.
- ^ Ontanon, Santiago; Synnaeve, Gabriel; Uriarte, Alberto; Richoux, Florian; Churchill, David; Preuss, Mike (diciembre de 2013). «Una encuesta sobre la investigación y la competencia de la IA de los juegos de estrategia en tiempo real en StarCraft». Transacciones del IEEE sobre Inteligencia Computacional e Inteligencia Artificial en Juegos. 5 (4): 293–311. CiteSeerX 10.1.1.406.2524. doi:10.1109/TCIAIG.2013.2286295.
- ^ «Facebook entra silenciosamente en la guerra de StarCraft por los robots de IA, y pierde». CABLEADO. 2017. Recuperado 7 de mayo 2018.
- ^ «ILSVRC2017». image-net.org. Recuperado 2018-11-06.
- ^ Schoenick, Carissa; Clark, Peter; Tafjord, Oyvind; Turney, Peter; Etzioni, Oren (23 de agosto de 2017). «Más allá de la prueba de Turing con el desafío científico de la IA Allen». Comunicaciones de la ACM. 60 (9): 60-64. arXiv:1604.04315. doi:10.1145/3122814.
- ^ O’Brien, James; Marakas, George (2011). Sistemas de información de gestión (10ª ed.). McGraw-Hill/Irwin. ISBN 978-0-07-337681-3.Mantenimiento de CS1: ref=harv (link)
- ^ Hernández-Orallo, José (2000). «Más allá de la prueba de Turing». Revista de Lógica, Lenguaje e Información. 9 (4): 447-466. doi:10.1023/A:1008367325700.Mantenimiento de CS1: ref=harv (link)
- ^ Dowe, D. L.; Hajek, A. R. (1997). «A computational extension to the Turing Test». Actas de la 4ª Conferencia de la Sociedad de Ciencias Cognitivas de Australasia. Archivado del original el 28 de junio de 2011.Mantenimiento de CS1: ref=harv (link)
- ^ Hernández-Orallo, J.; Dowe, D. L. (2010). «Midiendo la Inteligencia Universal: Hacia una prueba de inteligencia en cualquier momento». Inteligencia Artificial. 174 (18): 1508–1539. CiteSeerX 10.1.1.295.9079. doi:10.1016/j.artint.2010.09.006.Mantenimiento de CS1: ref=harv (link)
- ^ Hernández-Orallo, José; Dowe, David L.; Hernández-Lloreda, M.Victoria (Marzo 2014). «Psicometría universal: Medición de las capacidades cognitivas en el reino de las máquinas». Investigación de sistemas cognitivos. 27: 50-74. doi:10.1016/j.cogsys.2013.06.001. hdl:10251/50244.
- ^ Investigación, AI (23 de octubre de 2015). «Redes neuronales profundas para el modelado acústico en el reconocimiento del habla». airesearch.com. Recuperado 23 de octubre 2015.
- ^ «Las GPU siguen dominando el mercado de los aceleradores de IA por ahora». InformationWeek. Diciembre de 2019. Recuperado 11 de junio 2020.
- ^ Ray, Tiernan (2019). «La IA está cambiando toda la naturaleza de la computación». ZDNet. Recuperado 11 de junio 2020.
- ^ «IA y Computación». OpenAI. 16 de mayo de 2018. Recuperado 11 de junio 2020.