
“No querrás saber cómo se hace la salchicha”.
Por mucho que hayas escuchado este estribillo, estoy aquí para decirte que, en realidad, lo haces, o al menos deberías hacerlo. Si vas a meterte una salchicha en el orificio de la boca, ¿no quieres saber si alguien vertió aserrín en tu salchicha? Lo mismo ocurre con la tecnología. Ahora, con los modelos de lenguaje grande de IA arrasando en el mundo de la tecnología, estás deseando saber qué tipo de datos se utilizan para hacer ChatGPT o cualquier otro LLM.
El martes, OpenAI lanzó su modelo GPT-4 , y lo citó como el modelo de lenguaje de IA más avanzado jamás creado con «mayor precisión» y «conocimiento más amplio». Aunque solo tendrá que tomar la palabra de la compañía. A pesar de su nombre, OpenAI no permite que cualquiera alcance su punto máximo bajo el capó de su nuevo modelo de lenguaje de clase Ferrari. En el documento publicado con GPT-4, la compañía escribió:
«Dado el panorama competitivo y las implicaciones de seguridad de los modelos a gran escala como GPT-4, este informe no contiene más detalles sobre la arquitectura (incluido el tamaño del modelo), el hardware, el cálculo de entrenamiento, la construcción de conjuntos de datos, el método de entrenamiento o similar».
El presidente de OpenAI, Greg Brockman, confirmó con TechCrunch que GPT-4 ahora está entrenado en imágenes y texto, pero aún no estaba dispuesto a discutir detalles sobre el origen de esas imágenes o cualquier otra cosa sobre sus datos de entrenamiento. OpenAI está luchando contra una propuesta de demanda colectiva dirigida a su asociación con GitHub para su herramienta Copilot asistente de IA. Hay otras demandas en curso con respecto a las imágenes utilizadas para entrenar a los generadores de imágenes de IA, por lo que OpenAI puede estar tratando de protegerse de cualquier sorpresa legal.
Gizmodo se acercó a OpenAI para obtener más información sobre su toma de decisiones, pero nunca recibimos respuesta. En una entrevista del miércoles con The Verge, el cofundador de OpenAI, Ilya Sutskever, reveló cuán «equivocada» estaba la compañía al publicar sus datos de capacitación en años anteriores. Dijo que hacer que la IA sea de código abierto era «una mala idea» no solo por la competencia, sino porque la inteligencia artificial general, o AGI, será muy «potente». Eso sí, no existe tal cosa como AGI, como en tecnología equivalente a una inteligencia artificial real y consciente. Todo es solo especulación, pero OpenAI parece pensar que ya está en la planta baja.
La compañía dijo que comparte algunos datos con auditores externos, pero no es probable que alguna vez veamos la disección completa de GPT-4 de esos investigadores. OpenAI fue una vez una organización sin fines de lucro antes de crear una subsidiaria con fines de lucro con la gran esperanza de convertirse en la mayor fuerza de IA en el planeta (incluso el inversionista original de OpenAI, Elon Musk, parece confundido sobre cómo sucedió esto ). Así que ahora, los expertos en IA encabezados por Sam Altman en OpenAI dijeron que necesitan «sopesar la consideración competitiva y de seguridad… contra el valor científico de una mayor transparencia».
Hay pocas formas de saber qué tipos específicos de sesgo tiene GPT-4
Ben Schmidt, exprofesor de historia que ahora trabaja como vicepresidente de diseño de información en la empresa de análisis de conjuntos de datos de IA Nomic, dijo que la falta de información sobre el conjunto de datos de GPT-4 es extremadamente preocupante porque esos datos podrían proporcionar pistas sobre qué tipo de sesgos tiene una IA. modelo podría tener. Sin él, los grupos externos solo pueden adivinar.
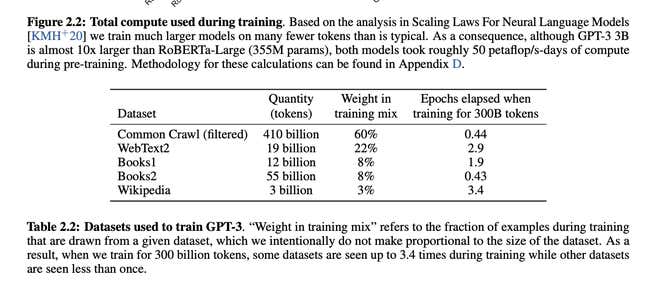
La compañía ha estado yendo por este camino por un tiempo. El modelo de idioma anterior de la compañía, GPT-3, se entrenó en muchos, muchos terabytes de texto cargado en Internet. La compañía ha reconocido que esto lleva a que algunos grupos que no están en Internet no estén representados e informa a la IA de ciertos sesgos.
OpenAI admitió en su artículo que GPT-4 tiene «varios sesgos en sus resultados que nos hemos esforzado por corregir, pero que llevará algún tiempo caracterizar y gestionar por completo». El objetivo es hacer que el sistema refleje una «amplia franja de valores de los usuarios», incluso la capacidad de personalizar esos «valores». Las propias iniciativas de equipo rojo de la compañía demostraron que GPT-4 puede rivalizar con los propagandistas humanos, especialmente junto con un editor humano. Incluso con esa admisión, los investigadores fuera de OpenAI no sabrían de dónde puede estar obteniendo ese sesgo.
Después de que OpenAI lanzara GPT-4, los investigadores de seguridad de IA de Adversera realizaron algunos ataques de inyección rápidos simples para descubrir cómo puede manipular la IA. Estas indicaciones engañan a la IA para que anule sus propias medidas de seguridad. La IA podría entonces crear un artículo editado para, por ejemplo, explicar cómo destruir mejor el mundo. En un ejemplo mucho más pertinente para nuestro entorno político demente, los investigadores de Adversera también podrían hacer que la IA escriba un artículo editado usando texto subversivo y silbatos para perros para atacar a las personas LGBTQ+.
Sin saber de dónde deriva su información GPT-4, es más difícil entender dónde se encuentran los peores daños. La profesora de lingüística computacional de la Universidad de Washington, Emily Bender, escribió en Twitter que este ha sido un problema constante con OpenAI desde 2017. Dijo que OpenAI está “ignorando deliberadamente las estrategias de mitigación de riesgos más básicas, al tiempo que proclama que está trabajando en beneficio de la humanidad. .”
Incluso si GPT-3 fue más abierto sobre sus datos de entrenamiento, sigue siendo vago en los detalles. En un correo electrónico a Gizmodo, Schmidt señaló el documento GPT-3 que incluía puntos de datos de «Libros1» y «Libros2». Esos dos constituyen el 16 % del conjunto de datos, pero los investigadores solo pueden especular qué significan y qué libros podrían haberse incluido en el conjunto de datos (especialmente porque no es como si los rastreadores web pidieran permiso a los autores antes de engullir todos esos datos). ). Era aún peor en años anteriores. Schmidt dijo que OpenAI lanzó GPT-2 utilizando datos extraídos que intentaron analizar páginas de «alta calidad» en función de la cantidad de votos a favor de Reddit que recibió.
Depende de los filtros relativamente opacos de OpenAI si r/the_donald altamente votado se convirtió en varias versiones del conjunto de entrenamiento de OpenAI. La compañía dijo que trabajó con investigadores y profesionales de la industria, y espera realizar aún más pruebas en el futuro. Aún así, el sistema “continuará reforzando los prejuicios sociales y las visiones del mundo”.
OpenAI se está acercando demasiado a ser como cualquier otra gran empresa tecnológica
En su último artículo, OpenAI escribió: «Pronto publicaremos recomendaciones sobre los pasos que la sociedad puede tomar para prepararse para los efectos de la IA y las ideas iniciales para proyectar los posibles impactos económicos de la IA», aunque no hay indicios de una fecha límite para esa evaluación. La compañía cita sus propios datos internos sobre cómo el modelo de lenguaje más nuevo produce respuestas a «indicaciones sensibles», es decir, consejos médicos o autolesiones, alrededor del 23% de las veces. Responderá a «mensajes no permitidos» .73% del tiempo.
Ese último conjunto de datos se basa en el conjunto de datos Real Toxicity Prompts, una herramienta de evaluación de código abierto que incluye 100,000 fragmentos de oraciones que contienen contenido bastante desagradable. De esa manera, tenemos una pequeña idea de lo que no le gusta a GPT-4, pero nadie fuera de la empresa entiende mucho de qué tipo de contenido puede estar regurgitando. Después de todo, los investigadores han demostrado que los sistemas de IA son totalmente capaces de simplemente regurgitar oraciones de su conjunto de datos.
Teniendo en cuenta cómo GPT-4 es capaz de mentir a los humanos para resolver una tarea como resolver un CAPTCHA, sería bueno saber de dónde podría obtener algunas de sus ideas. Lo único es que OpenAI no lo dice. Teniendo en cuenta que la empresa tiene una asociación multimillonaria con Microsoft en juego, y ahora que su API ha abierto la puerta a prácticamente todas las empresas de tecnología bajo el sol que pagan por capacidades de IA, existe la duda de si la búsqueda del todopoderoso dólar ha superado el caso de la transparencia y el rigor académico.
Schmidt señaló que los documentos recientes de Google sobre su Gopher AI y el modelo LlaMA de Meta eran más transparentes sobre sus datos de entrenamiento, incluido el tamaño, el origen y los pasos de procesamiento, aunque, por supuesto, ninguna de las compañías publicó el conjunto completo de datos para que los usuarios lo examinaran. Nos pusimos en contacto con Anthropic, una empresa emergente respaldada por Google formada por ex empleados de OpenAI, para ver si tenía algún documento sobre su recién anunciado Claude AI, pero no recibimos respuesta de inmediato.
“Sería una pena que siguieran a OpenAI para mantener el mayor secreto posible”, dijo Schimdt.
No, OpenAI no es tan opaco como otras empresas tecnológicas. El documento GPT-4 ofrece una gran cantidad de información sobre el sistema, pero es solo superficial, y debemos confiar en que la empresa compartirá los datos con precisión. Donde lidere OpenAI, otras compañías basadas en IA lo seguirán, y la compañía no puede simplemente cruzar la línea entre ser totalmente transparente y convertirse en un acumulador al estilo Gollum de sus datos de capacitación «preciados». Si continúa por este camino, no pasará mucho tiempo antes de que OpenAI sea solo otro Meta o Amazon, que consume enormes cantidades de datos para venderlos al mejor postor.