
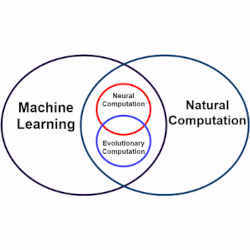
La intersección de la computación natural y evolutiva en el contexto del aprendizaje automático y la computación natural.
Crédito: Aprendizaje automático evolutivo: una encuesta, AKBAR TELIKANI et al, https://doi.org/10.1145/3467477
Las redes neuronales profundas (DNN) que utilizan el aprendizaje por refuerzo (RL, que explora un espacio de decisiones aleatorias para obtener combinaciones ganadoras) pueden crear algoritmos que compiten con los producidos por humanos para juegos, procesamiento del lenguaje natural (NLP), visión artificial (CV), educación , transporte, finanzas, salud y robótica, según el artículo seminal Introducción al aprendizaje por refuerzo profundo (DRL).
Desafortunadamente, los éxitos de las DNN son cada vez más difíciles de conseguir, debido a la sensibilidad de los hiperparámetros iniciales elegidos (como el ancho y la profundidad de la DNN, así como otras condiciones iniciales específicas de la aplicación). Sin embargo, estas limitaciones se han superado recientemente mediante la combinación de RL con la computación evolutiva (EC), que mantiene una población de agentes de aprendizaje, cada uno con condiciones iniciales únicas, que juntos «evolucionan» en una solución óptima, según Ran Cheng y colegas del Southern Universidad de Ciencia y Tecnología, Shenzhen, China, en cooperación con la Universidad de Bielefeld de Alemania y la Universidad de Surrey del Reino Unido.
Al elegir entre muchos agentes de aprendizaje en evolución (cada uno con diferentes condiciones iniciales), el aprendizaje de refuerzo evolutivo (EvoRL) está extendiendo la inteligencia de DRL a tareas humanas interdisciplinarias difíciles de resolver, como automóviles y robots autónomos, según Jurgen Branke, profesor de Investigación Operativa y Sistemas en la Universidad de Warwick del Reino Unido y editor en jefe de la nueva revista de ACM Transacciones sobre aprendizaje evolutivo y optimización
Branke dijo: «La naturaleza está utilizando dos formas de adaptación: la evolución y el aprendizaje. Por lo tanto, no parece sorprendente que la combinación de estos dos paradigmas también tenga éxito ‘in-silico’. [that is, algorithmic ‘evolution’ akin to ‘in-vivo’ biological evolution].»
Aprendizaje reforzado
El aprendizaje por refuerzo es el más nuevo de los tres algoritmos de aprendizaje principales para redes neuronales profundas (las DNN se diferencian del perceptrón seminal de tres capas al agregar muchas capas internas, cuya función no comprenden completamente sus programadores, lo que se denomina caja negra). Se supervisaron los dos primeros métodos de aprendizaje de DNN primarios anteriores: aprender de datos etiquetados por humanos (como fotografías de pájaros, automóviles y flores, cada uno etiquetado como tal) para aprender a reconocer y etiquetar automáticamente nuevas fotografías. El segundo método de aprendizaje más popular fue el no supervisado, que agrupa datos no etiquetados en gustos y disgustos, según los puntos en común encontrados por la caja negra de DNN.
El aprendizaje por refuerzo, por otro lado, agrupa datos no etiquetados en conjuntos de Me gusta, pero con el objetivo de maximizar las recompensas acumulativas que recibe de una función de evaluación forjada por humanos. El resultado es un DNN que usa RL para superar a otros métodos de aprendizaje, aunque aún usa capas internas que no encajan en un modelo matemático conocible. Por ejemplo, en la teoría de juegos, las recompensas acumulativas serían ganar juegos. La «optimización» se usa a menudo para describir la metodología obtenida mediante el aprendizaje por refuerzo, según Marco Wiering de la Universidad de Groningen (Países Bajos) y Martijn Otterlo de la Universidad de Radboud (Nijmegen, Países Bajos) en su artículo de 2012. Aprendizaje reforzadoaunque no hay forma de probar que el «comportamiento óptimo» encontrado con RL es la solución «más» óptima.
Con este fin, RL explora los rincones y grietas desconocidos de un espacio de soluciones para ver si obtienen recompensas más óptimas, así como para persuadir a DNN a encontrar soluciones más óptimas a partir de su conocimiento ya acumulado que ha demostrado dar como resultado más recompensas. El aprendizaje por refuerzo logra recompensas acumulativas cada vez mayores a medida que avanza hacia la optimización, según Richard Sutton, profesor de Ciencias de la Computación en Aprendizaje por Refuerzo e Inteligencia Artificial en la Universidad de Alberta de Canadá y Científico Investigador Distinguido en DeepMind, en colaboración con Andrew Bartow, profesor emérito de informática de la Universidad de Massachusetts (Amherst), en su 2012 papel Aprendizaje por refuerzo: una introducción.
class=»imagen» mostrar:bloque en línea»>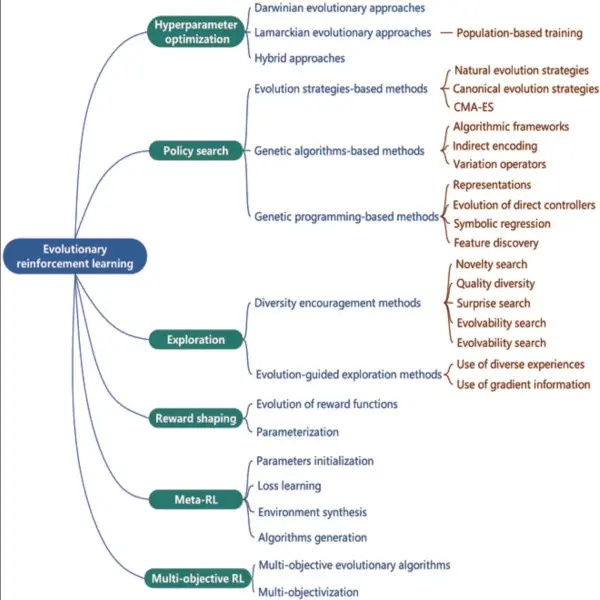
optimización de hiperparámetros—un algoritmo universal que también se utiliza en las otras cinco metodologías, ya que simultáneamente realiza un aprendizaje de extremo a extremo y mejora el rendimiento.
Búsqueda de políticas busca identificar una política que maximice la recompensa acumulada por una tarea dada.
Exploración alienta a los agentes a explorar más estados y acciones y capacita a agentes robustos para responder mejor a los cambios dinámicos en los entornos.
Dar forma a la recompensa tiene como objetivo mejorar la recompensa original con recompensas de configuración adicionales para tareas con recompensas escasas.
Meta-RL busca desarrollar un algoritmo de aprendizaje de propósito general que pueda adaptarse a diferentes tareas.
RL multiobjetivo tiene como objetivo obtener agentes de compensación en tareas con una serie de objetivos en conflicto.
Crédito: Aprendizaje por refuerzo evolutivo: una encuesta
Computación evolutiva
La computación evolutiva, por otro lado, crea una población aleatoria de agentes de resolución de problemas, luego los «evoluciona» sometiendo a cada uno a una selección «natural», es decir, descartando los peores, mutando el resto y repitiendo el proceso. Cada agente se mide frente a una función de aptitud, como en la «supervivencia del más apto». El proceso se repite tantas veces como sea necesario hasta que se obtiene una solución óptima, aunque no se garantiza que sea perfectamente óptima.
Cuando la computación evolutiva se combina con el aprendizaje por refuerzo (EvoRL), la metodología combinada desarrolla una población de agentes, cada uno con diferentes condiciones iniciales específicas de la aplicación, lo que elimina la necesidad de reiniciar manualmente un DRL que no converge en un óptimo adecuado.
«EvoRL proporciona un marco poderoso para abordar problemas complejos aprovechando las fortalezas tanto de RL como de los métodos evolutivos. Permite a los agentes explorar una amplia gama de políticas, lo que lleva al descubrimiento de estrategias novedosas y contribuye al desarrollo de sistemas autónomos. » dijo Giuseppe Paolo, científico investigador sénior de IA en Noah’s Ark Lab en Huawei (París) y editor invitado de una edición especial próximamente sobre Aprendizaje por refuerzo evolutivo de la nueva revista de ACM. Transacciones sobre aprendizaje evolutivo y optimización.
Agrega otro editor invitado, Adam Gaier, científico investigador principal en el Laboratorio de IA de Autodesk (Alemania): «Queríamos llamar la atención de investigadores y profesionales en ambos campos sobre este campo combinado como una forma de fomentar una mayor exploración. En el número especial , presentamos una revisión extensa del campo, una nueva investigación original y una aplicación de EvoRL a un problema del mundo real. Como tal, EvoRL es un campo cada vez más activo que combina el poder del aprendizaje por refuerzo (RL) y la computación evolutiva para abordar Los principales obstáculos de RL. Si bien RL sobresale en tareas complejas, tiene dificultades con la sensibilidad a los valores de configuración iniciales, determinando las acciones que conducen a recompensas retrasadas y navegando por objetivos en conflicto. Los algoritmos evolutivos (EA), por otro lado, manejan estos problemas pero no fallan cuando se trata de escasez de datos y problemas complejos de alta dimensión. EvoRL combina elegantemente la optimización de RL y los métodos basados en la población de EA, mejorando la diversidad de exploración y superando las limitaciones de EA mientras amplifica las fortalezas de RL».
Mientras que el aprendizaje por refuerzo por sí solo suele seguir el gradiente proporcionado por la función de evaluación para mejorar de manera efectiva las posibles soluciones, el cálculo evolutivo comienza primero con una población de soluciones candidatas cuyas condiciones iniciales se eligen al azar. La población se evalúa mediante la función de aptitud proporcionada por el ser humano. Los que tienen la aptitud más baja se descartan, mientras que el resto se muta a través de la computación evolutiva y el proceso se repite hasta que se alcanza el punto de rendimientos decrecientes en la optimización. Esto permite que el proceso evolutivo esté menos sujeto a atascarse en los óptimos locales (un obstáculo para los enfoques basados en gradientes) y proporciona «creatividad», según Antoine Cully, profesor titular de Robótica e Inteligencia Artificial y director de Robótica Adaptativa e Inteligente. Lab en el Departamento de Informática del Imperial College London del Reino Unido.
Dijo Cully, también editor invitado de la edición especial, «El dominio del aprendizaje por refuerzo evolutivo es un área de investigación muy emocionante, ya que combina la creatividad y las capacidades de exploración de los algoritmos evolutivos, con la eficacia del gradiente descendente del aprendizaje por refuerzo profundo, que permite optimizar políticas complejas de redes neuronales. Apenas estamos comenzando a explorar las sinergias entre estas dos áreas de investigación, pero ya ha demostrado ser fructífero».
Según Cheng et al, hay seis variaciones principales de EvoRL que se usan hoy en día (como se indica en el título del gráfico anterior). La eficiencia es una importante dirección futura para el refinamiento, ya que los seis algoritmos principales de EvoRL son computacionalmente intensivos. Se necesitan mejoras en las codificaciones, los métodos de muestreo, los operadores de búsqueda, los marcos algorítmicos y las metodologías de aptitud/evaluación. También se necesitan puntos de referencia, pero pueden ser difíciles de elaborar, según Cheng et al, ya que los seis enfoques básicos utilizan diferentes hiperparámetros y algoritmos específicos de la aplicación. También se necesitan plataformas escalables y se están desarrollando, pero nuevamente se limitan en su mayoría a uno o dos de los seis enfoques principales.
R. Colin Johnson es un Kyoto Prize Fellow que ha trabajado como periodista tecnológico durante dos décadas.
entradas no encontradas