

Estoy emocionado de compartir con ustedes parte del trabajo fascinante que hemos estado haciendo aquí en Release. Nuestro equipo ha estado explorando el poder de las incrustaciones, las bases de datos vectoriales y los modelos de lenguaje para crear funciones de productos innovadoras. En esta publicación, explicaré nuestro viaje a medida que exploramos OpenAI y ChatGPT y cómo estamos aprovechando ahora incrustaciones y bases de datos vectoriales a generar avisos para ChatGPT.
Comenzamos a buscar varias formas de aprovechar la IA en nuestro producto. Esperábamos poder hacer que ChatGPT generara plantillas de aplicaciones de lanzamiento, los planos que usamos para describir una aplicación en el lanzamiento. Rápidamente nos dimos cuenta de que ChatGPT solo está capacitado con datos anteriores a septiembre de 2021 y era cuestionable si sabía algo sobre Release.
La versión admite el uso de Docker y Docker Compose, por lo que podrá usar estos archivos en la versión para generar una plantilla de aplicación. Pero estaba claro que era necesario entrenar a ChatGPT utilizando la documentación de la versión o un gran corpus de plantillas de aplicaciones de versión si iba a generar una desde cero.
Explorando los complementos de ChatGPT
Los complementos de ChatGPT parecían la mejor manera de brindar a ChatGPT conocimientos externos a partir de su conjunto de capacitación. Nos registramos en la lista de espera de complementos de ChatGPT y finalmente obtuvimos acceso a los complementos de ChatGPT. El complemento de recuperación de ChatGPT parecía un lugar para comenzar a experimentar con los complementos de ChatGPT y comprender cómo funcionan.
Después de agregar algunos archivos al chatgpt-retrival-plugin, lo hicimos ejecutar Release. Luego comenzamos a trabajar en la carga de datos en el complemento, convirtiendo todos nuestros documentos en JSON y cargándolos en el complemento de recuperación usando el punto final `/upsert`. Una vez que se configuró el complemento ChatGPT, pudimos preguntarle a ChatGPT «¿Cómo creo una plantilla de aplicación en la versión?»
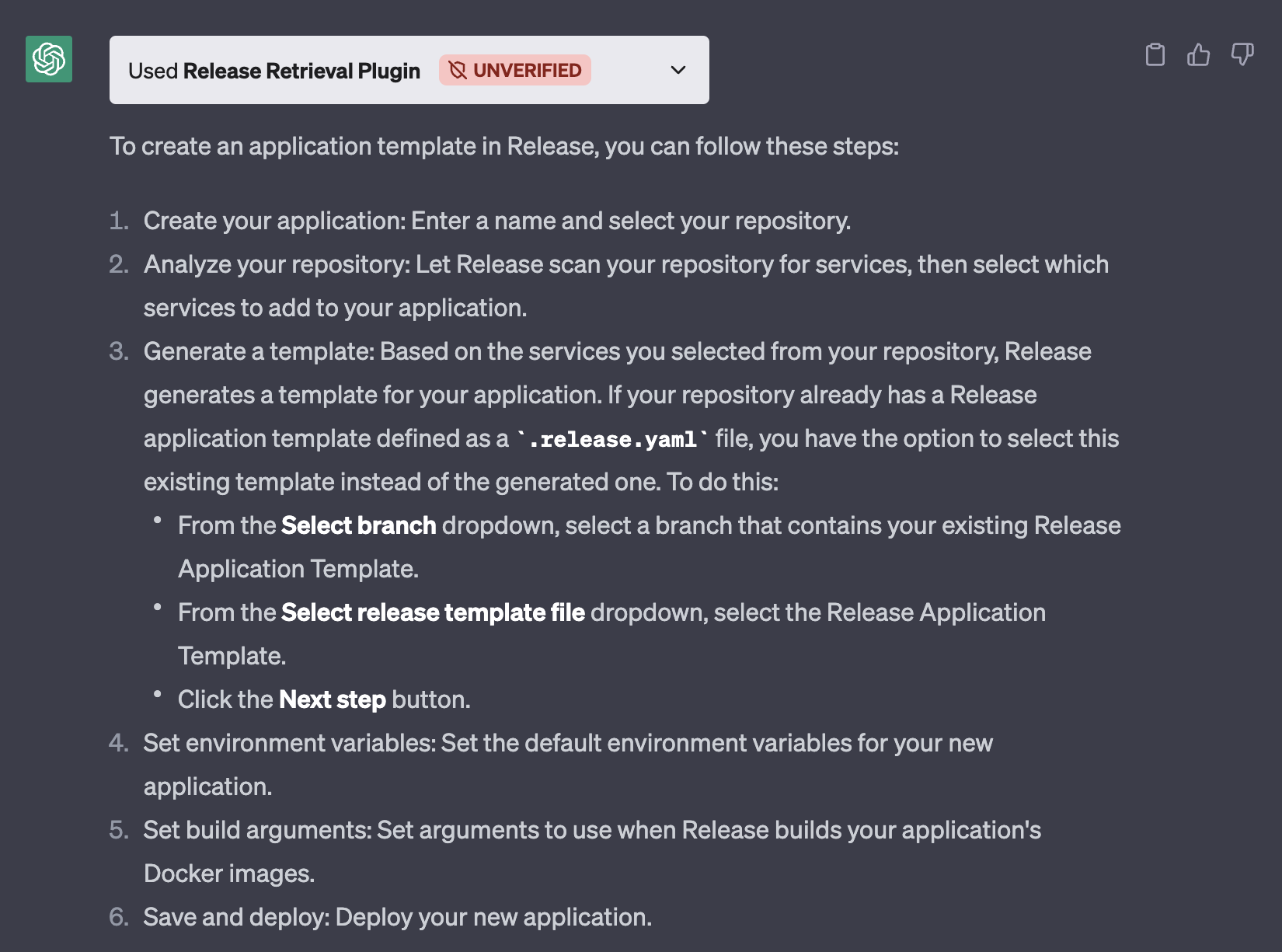
El complemento de recuperación funciona bien para hacer una pregunta que se puede responder utilizando la documentación a la que tiene acceso. Sin embargo, no estaba claro cuándo los complementos estarán disponibles en general para que todos los usuarios accedan. Planeamos desarrollar un complemento ChatGPT que todos puedan usar una vez que eso suceda.
Uso de incrustaciones y generación de avisos
Mientras nuestro equipo continuaba explorando el espacio de la IA, nos encontramos con un artículo del Blog de Supabase. El artículo explicaba un enfoque diferente para “entrenar” a ChatGPT. En lugar de que ChatGPT tenga acceso a nuestra documentación directamente, puede enviar fragmentos de los documentos a ChatGPT en el aviso. Aquí está la plantilla de solicitud que toma la pregunta de los usuarios y los fragmentos relevantes de los documentos para responder a una pregunta de los usuarios:
`
You are a very enthusiastic Release representative who loves
to help people! Given the following sections from the Release
documentation, answer the question using only that information,
outputted in markdown format. If you are unsure and the answer
is not explicitly written in the documentation, say
"Sorry, I don't know how to help with that."
Context sections:
${contextText}
x
"""
Answer as markdown (including related code snippets if available):
`
Las personas que ayudaron a crear la funcionalidad Supabase AI también crearon un proyecto independiente de código abierto next.js OpenAI Search Starter. Hemos estado utilizando este proyecto como punto de partida para nuestra búsqueda de documentación basada en IA.
¿Qué son las incrustaciones?
Tanto el complemento de recuperación de ChatGPT como la búsqueda de documentación de IA de Supabase dependen de la generación, el almacenamiento y la búsqueda de incrustaciones. Entonces, ¿qué es una incrustación?
Las incrustaciones son una forma de representar texto, imágenes u otros tipos de datos en un formato numérico que los algoritmos de aprendizaje automático pueden procesar fácilmente. En el contexto del procesamiento del lenguaje natural (NLP), las incrustaciones de palabras son representaciones vectoriales de palabras, donde cada palabra se asigna a un vector de tamaño fijo en un espacio de alta dimensión. Estos vectores capturan las relaciones semánticas y sintácticas entre palabras, permitiéndonos realizar operaciones matemáticas sobre ellas. El siguiente diagrama muestra la relación entre varias oraciones:
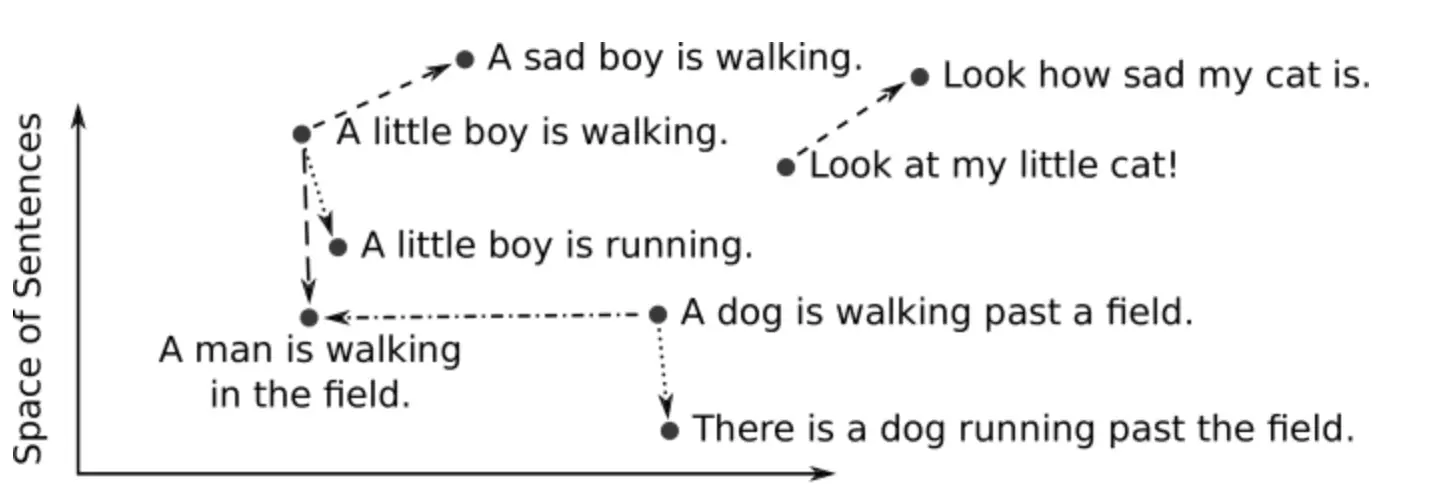
imagen de incrustaciones de oraciones – de DeepAI
Las incrustaciones se pueden usar para encontrar palabras que sean semánticamente similares a una palabra determinada. Al calcular la similitud del coseno entre los vectores de dos palabras, podemos determinar cuán similares son sus significados. Esta es una herramienta poderosa para tareas como la clasificación de texto, el análisis de sentimientos y la traducción de idiomas.
¿Qué son las bases de datos vectoriales?
Las bases de datos vectoriales, también conocidas como motores de búsqueda de vectores, son bases de datos especializadas diseñadas para almacenar y buscar vectores de alta dimensión de manera eficiente. Permiten la búsqueda rápida de similitudes y la búsqueda de vecinos más cercanos, que son operaciones esenciales cuando se trabaja con incrustaciones.
La búsqueda de documentación de IA de Supabase utiliza pgvector para almacenar y recuperar incrustaciones. Pero hoy existen muchas otras bases de datos vectoriales:
Pinecone, una base de datos de vectores totalmente gestionada
Weaviate, un motor de búsqueda vectorial de código abierto
Redis, una base de datos vectorial
Qdrant, un buscador de vectores
Milvus, una base de datos vectorial construida para la búsqueda de similitud escalable
Chroma, una tienda de incrustaciones de código abierto
Typesense, búsqueda rápida de vectores de código abierto
Todas estas bases de datos admiten tres cosas básicas: almacenar incrustaciones como vectores, la capacidad de buscar incrustaciones/vectores y, finalmente, clasificar los resultados en función de la similitud. Cuando se usa el modelo `text-embedding-ada-002` de OpenAI para generar incrustaciones, OpenAI recomienda usar la similitud de coseno que está integrada en la mayoría de las bases de datos vectoriales enumeradas anteriormente.
Cómo generar, almacenar y buscar incrustaciones
OpenAI proporciona un punto final de API para generar incrustaciones a partir de cualquier cadena de texto.
```ruby
# OpenAI recommends replacing newlines with spaces
# for best results (specific to embeddings)
input = section.gsub(/n/m, ' ')
response = openai.embeddings(parameters: { input: input, model: "text-embedding-ada-002"})
token_count = response['usage']['total_tokens'] # number of tokens used
embedding = response['data'].first['embedding'] # array of 1536 floats
```
Almacenar estos datos en Redis redis-stack-server y hacer que se puedan buscar requiere un índice. Para crear un índice usando redis-stack-server, debe ejecutar el siguiente comando:
```
FT.CREATE index ON JSON PREFIX 1 item: SCHEMA $.id AS id TEXT $.content AS content TEXT $.token_count AS token_count NUMERIC $.embedding AS embedding VECTOR FLAT 6 DIM 1536 DISTANCE_METRIC COSINE TYPE FLOAT64
```
Ahora podemos almacenar elementos en Redis e indexarlos con el siguiente comando:
```
JSON.SET item:1002020 $ '{"id":"963a2117895ec9a29f242f906fd188c6", "content":"# App Imports: …”, "embedding":[0.008565563,0.012807296…]}’
```
Tenga en cuenta que si no proporciona las 1536 dimensiones del vector, Redis no indexará sus datos y no le dará ninguna respuesta de error.
La búsqueda de resultados en Redis y su clasificación se pueden realizar con el siguiente comando:
```
FT.SEARCH index @embedding:[VECTOR_RANGE $r $BLOB]=>{$YIELD_DISTANCE_AS: my_scores} PARAMS 4 BLOB x00x00x00 r 5 LIMIT 0 10 SORTBY my_scores DIALECT 2
```
Tenga en cuenta que BLOB proporcionado está en formato binario y también debe tener las 1536 dimensiones de los datos vectoriales. Usamos la API de incrustaciones de OpenAI para generar el vector de incrustación y convertirlo en binario en Ruby usando `embedding.pack(«E*»)`.
Lanzamiento de la búsqueda de documentación impulsada por ChatGPT
Hemos reemplazado el backend next.js OpenAI Search Starter con Ruby y Redis. Lanzaremos nuestro proyecto como una gema de código abierto que permitirá a cualquier persona agregar rápidamente búsquedas de documentos basadas en IA a su sitio.
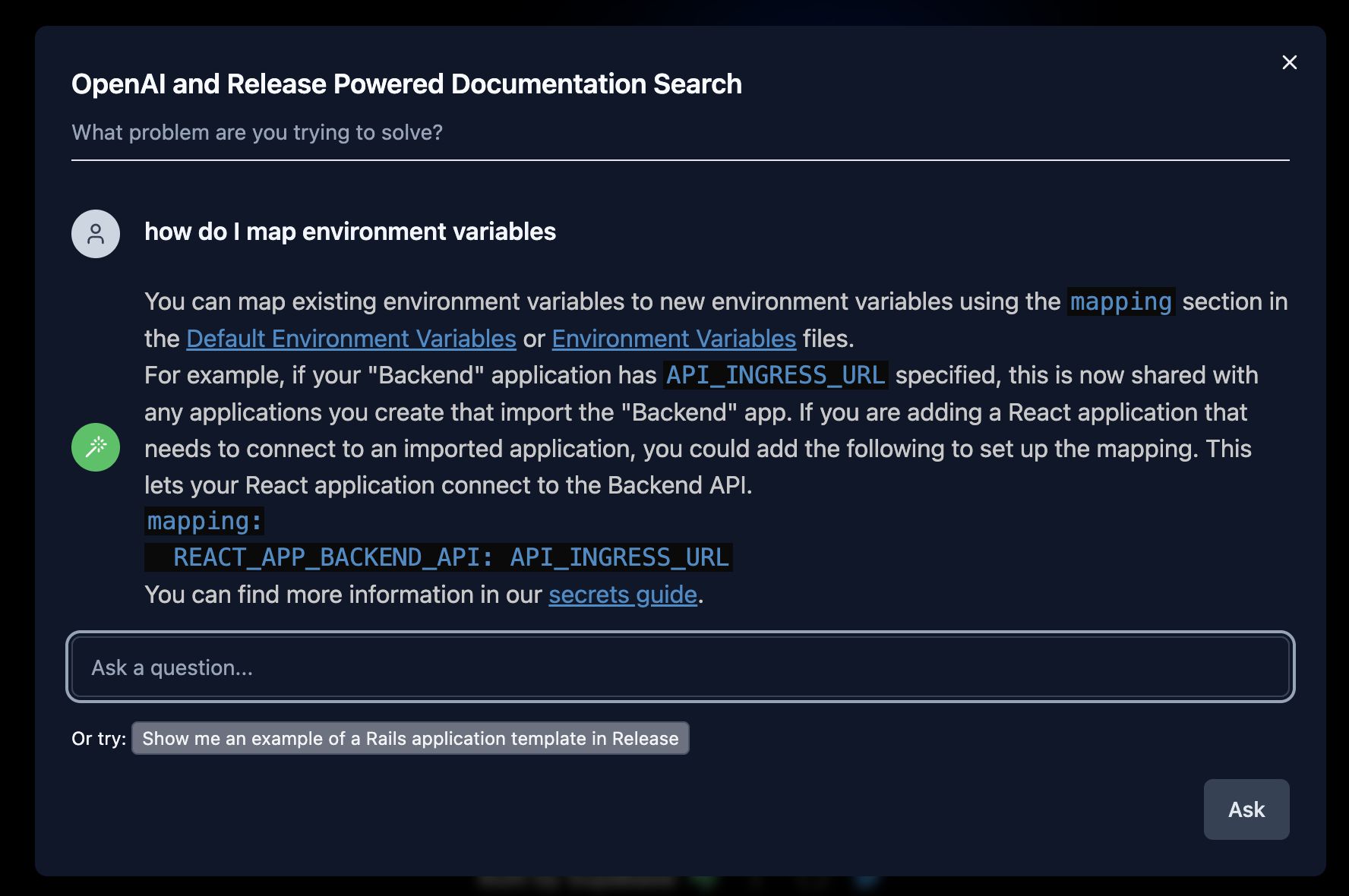
Tenemos un ejemplo funcional de Release AI Powered Documentation Search usando una versión ligeramente modificada de next.js OpenAI Search Starter. Hemos agregado soporte para el desplazamiento, una mejor representación de la reducción (que tenía la versión de Supabase) y la capacidad de conectar su API de búsqueda.
Conclusión
Al combinar el poder de las incrustaciones, las bases de datos vectoriales y los modelos de lenguaje como ChatGPT, hemos podido crear funciones de productos que brindan información valiosa y mejoran las experiencias de los usuarios. Ya sea respondiendo consultas de clientes, generando contenido personalizado o brindando recomendaciones, nuestro enfoque ha abierto nuevas posibilidades para la innovación.
Estamos entusiasmados con el potencial de esta tecnología y esperamos explorar nuevas formas de aprovecharla en el futuro. A medida que continuamos desarrollando y refinando nuestras ofertas de productos, nos comprometemos a permanecer a la vanguardia de la investigación de IA y PNL. Nuestro objetivo es crear herramientas y soluciones que permitan a las empresas y a las personas aprovechar el poder de los modelos lingüísticos de manera significativa e impactante.
Gracias por tomarse el tiempo para leer nuestra publicación de blog. Esperamos que lo haya encontrado informativo y que haya despertado su curiosidad sobre las interesantes posibilidades que ofrecen las incrustaciones, las bases de datos vectoriales y los modelos de lenguaje como ChatGPT. Si tiene alguna pregunta o desea obtener más información sobre nuestro trabajo en Release, no dude en comunicarse con nosotros o reservar una demostración. ¡Nos encantaría saber de usted!