
El aprendizaje por refuerzo (RL) es un paradigma poderoso para resolver muchos problemas de interés en la inteligencia artificial, como el control de vehículos autónomos, asistentes digitales y asignación de recursos, por nombrar algunos. Hemos visto en los últimos cinco años que, cuando se les proporciona una función de recompensa extrínseca, los agentes de RL pueden dominar tareas muy complejas como jugar Go, Starcraft y la manipulación robótica hábil. Si bien los agentes de RL a gran escala pueden lograr resultados sorprendentes, incluso los mejores agentes de RL de hoy son limitados. La mayoría de los algoritmos de RL actuales solo pueden resolver la tarea única en la que fueron entrenados y no exhiben capacidades de generalización entre tareas o dominios.
Un efecto secundario de la estrechez de los sistemas RL actuales es que Los agentes de RL de hoy también son muy ineficientes en cuanto a datos. Si tuviéramos que capacitar a agentes similares a AlphaGo en muchas tareas, es probable que cada agente requiera miles de millones de pasos de capacitación porque los agentes de RL de hoy en día no tienen la capacidad para reutilizar el conocimiento previo para resolver nuevas tareas de manera más eficiente. RL, como lo conocemos, es supervisado: los agentes se adaptan en exceso a una recompensa extrínseca específica que limita su capacidad para generalizar.

Hasta la fecha, el camino más prometedor hacia los sistemas de inteligencia artificial generalistas en lenguaje y visión ha sido a través de un entrenamiento previo sin supervisión. Los transformadores casuales y bidireccionales enmascarados han surgido como métodos escalables para modelos de lenguaje de preentrenamiento que han mostrado capacidades de generalización sin precedentes. Las arquitecturas siamesas y los codificadores automáticos enmascarados más recientemente también se han convertido en métodos de vanguardia para lograr una rápida adaptación de tareas en la visión.
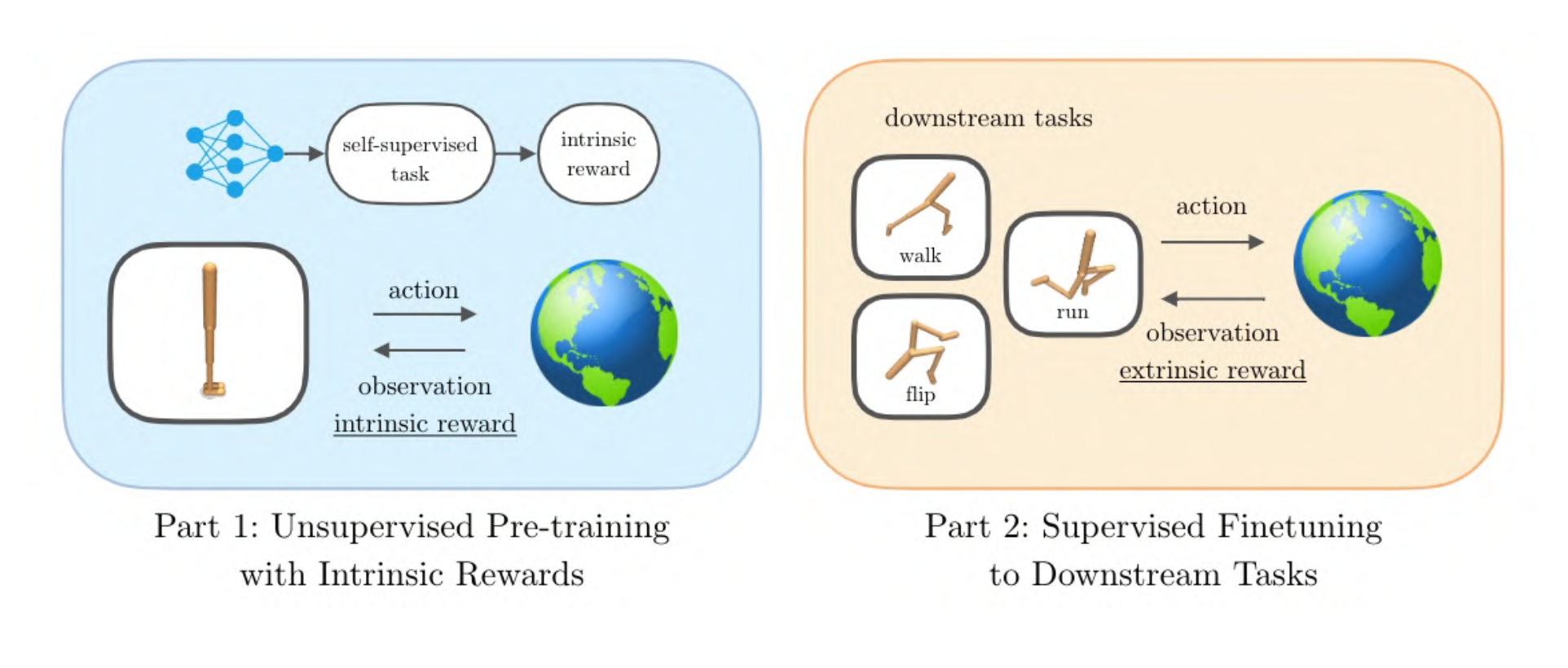
Si creemos que el entrenamiento previo es un enfoque poderoso para desarrollar agentes de IA generalistas, entonces es natural preguntarse si existen objetivos auto-supervisados que nos permitan entrenar previamente a los agentes de RL. A diferencia de los modelos de visión y lenguaje que actúan sobre datos estáticos, los algoritmos de RL influyen activamente en su propia distribución de datos. Al igual que en la visión y el lenguaje, el aprendizaje de la representación también es un aspecto importante para RL, pero el problema no supervisado que es exclusivo de RL es cómo los agentes pueden generar por sí mismos datos interesantes y diversos a través de objetivos auto-supervisados. Este es el problema de RL sin supervisión: ¿cómo aprendemos comportamientos útiles sin supervisión y luego los adaptamos para resolver rápidamente las tareas posteriores?
El RL no supervisado es muy similar al RL supervisado. Ambos asumen que el entorno subyacente se describe mediante un proceso de decisión de Markov (MDP) o un MDP parcialmente observado, y ambos tienen como objetivo maximizar las recompensas. La principal diferencia es que la RL supervisada asume que la supervisión la proporciona el entorno a través de una recompensa extrínseca, mientras que la RL no supervisada define una recompensa intrínseca a través de una tarea auto supervisada. Al igual que la supervisión en la PNL y la visión, las recompensas supervisadas son diseñadas o proporcionadas como etiquetas por operadores humanos que son difíciles de escalar y limitan la generalización de los algoritmos de RL a tareas específicas.
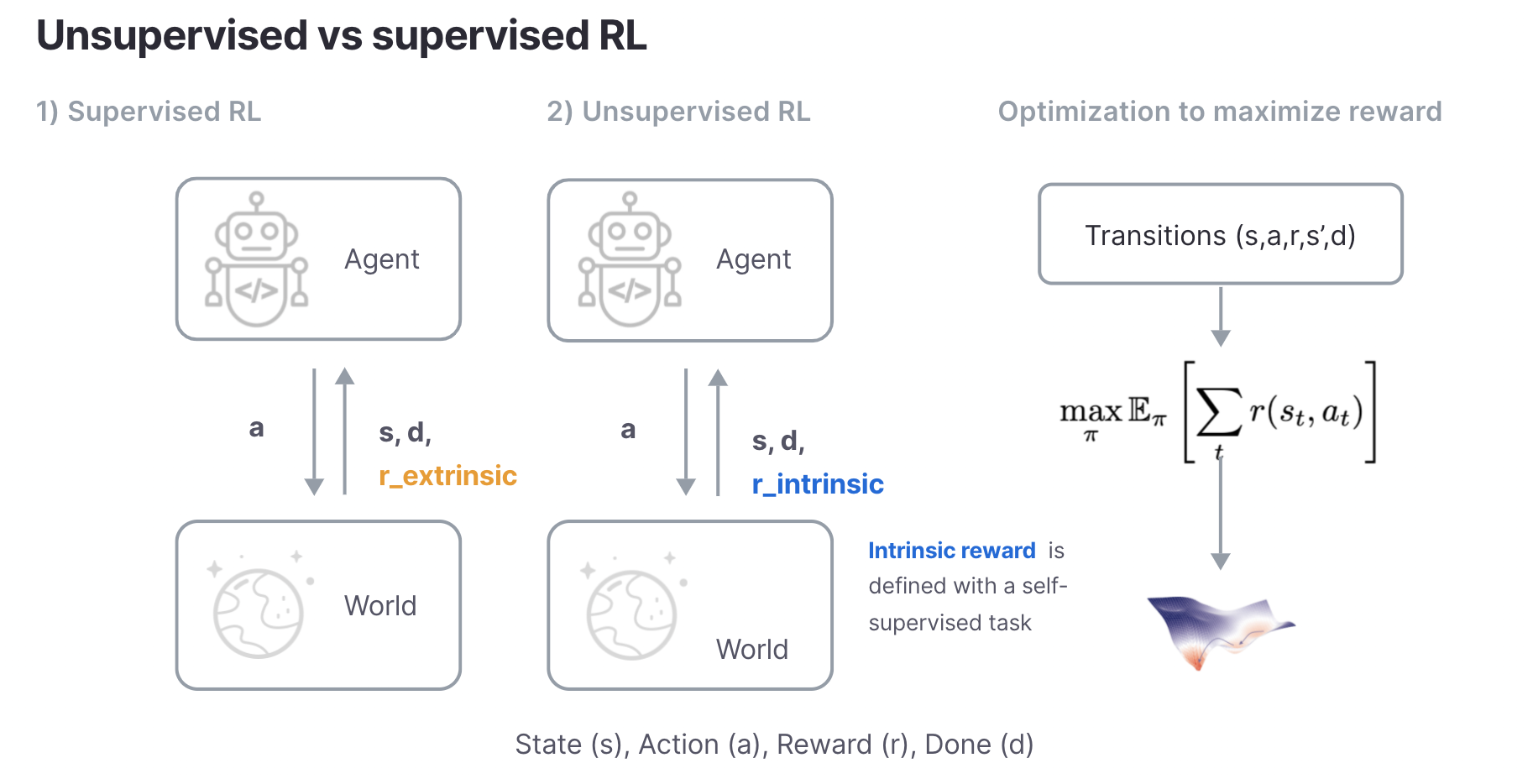
En el Robot Learning Lab (RLL), hemos estado tomando medidas para hacer de RL sin supervisión un enfoque plausible para desarrollar agentes de RL capaces de generalización. Con este fin, desarrollamos y publicamos un punto de referencia para RL sin supervisión con código PyTorch de código abierto para 8 líneas de base principales o populares.
El punto de referencia del aprendizaje por refuerzo no supervisado (URLB)
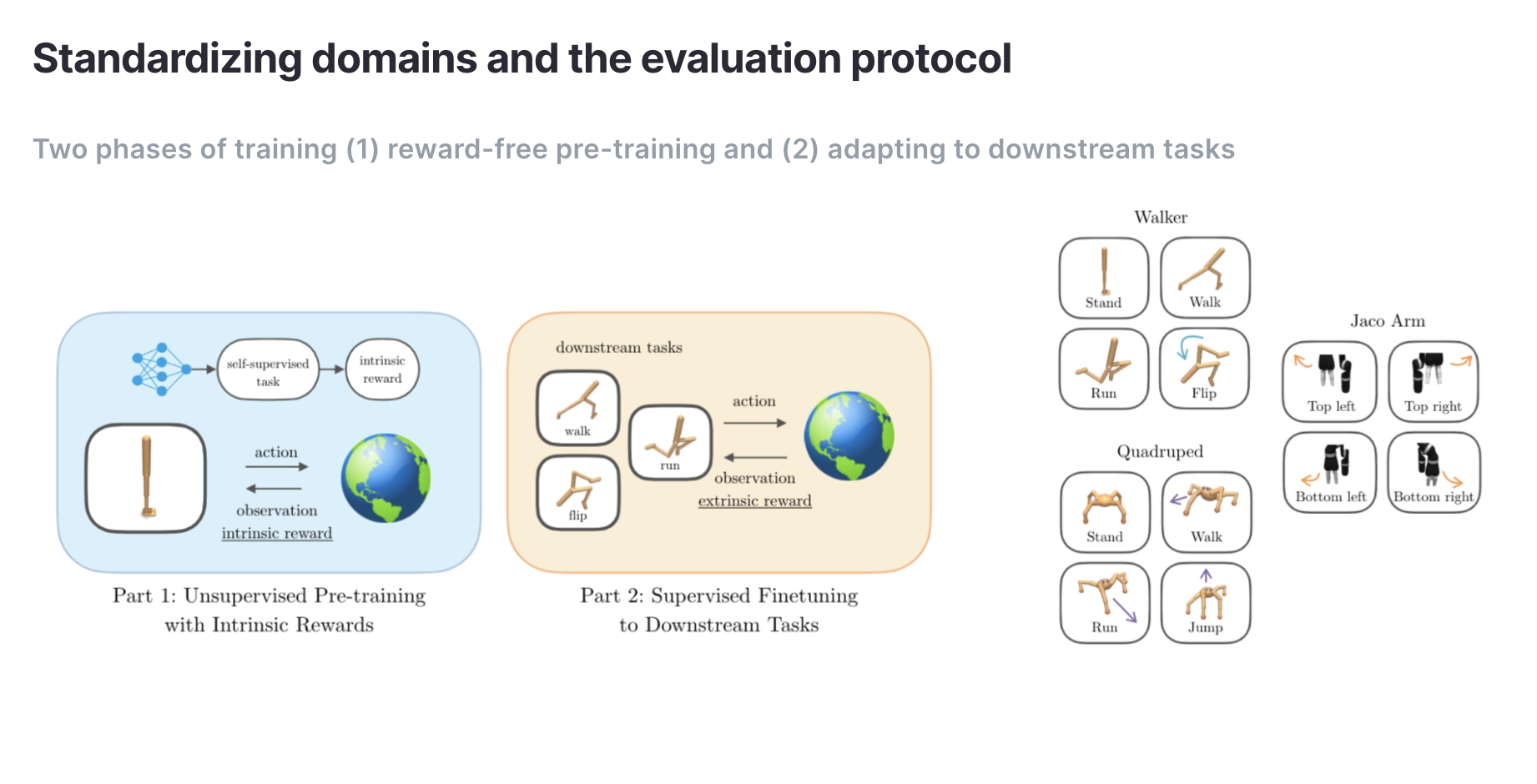
Si bien se han propuesto una variedad de algoritmos de RL sin supervisión en los últimos años, ha sido imposible compararlos de manera justa debido a las diferencias en la evaluación, los entornos y la optimización. Por esta razón, creamos URLB que proporciona procedimientos de evaluación estandarizados, dominios, tareas posteriores y optimización para algoritmos RL no supervisados.
URLB divide la formación en dos fases: una larga fase previa a la formación no supervisada seguida de una breve fase de ajuste fino supervisada. La versión inicial incluye tres dominios con cuatro tareas cada uno para un total de doce tareas posteriores para la evaluación.
La mayoría de los algoritmos de RL no supervisados conocidos hasta la fecha se pueden clasificar en tres categorías: basados en el conocimiento, basados en datos y basados en competencias. Los métodos basados en el conocimiento maximizan el error de predicción o la incertidumbre de un modelo predictivo (p. Ej., Curiosidad, desacuerdo, RND), los métodos basados en datos maximizan la diversidad de datos observados (p. Ej., APT, ProtoRL), los métodos basados en competencias maximizan la información mutua entre estados y algún vector latente a menudo denominado vector de «habilidad» o «tarea» (por ejemplo, DIAYN, SMM, APS).
Anteriormente estos algoritmos se implementaban utilizando diferentes algoritmos de optimización (Rainbow DQN, DDPG, PPO, SAC, etc). Como resultado, los algoritmos de RL sin supervisión han sido difíciles de comparar. En nuestras implementaciones estandarizamos el algoritmo de optimización de manera que la única diferencia entre varias líneas de base es el objetivo auto-supervisado.
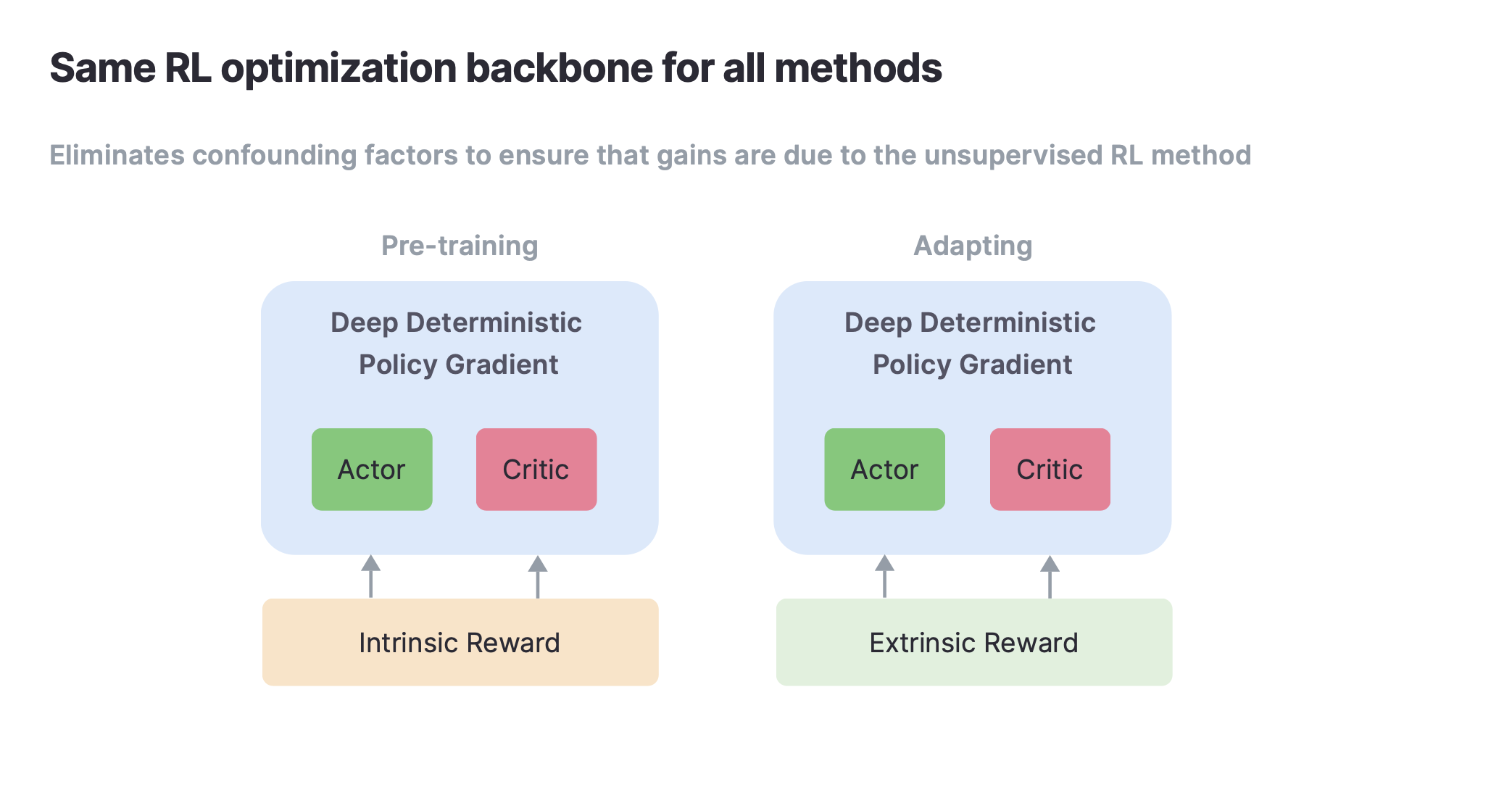
Implementamos y publicamos código para ocho algoritmos líderes que admiten observaciones de estado y basadas en píxeles en dominios basados en DeepMind Control Suite.

Al estandarizar los dominios, la evaluación y la optimización en todas las líneas de base implementadas en URLB, el resultado es una primera comparación directa y justa entre estos tres tipos diferentes de algoritmos.
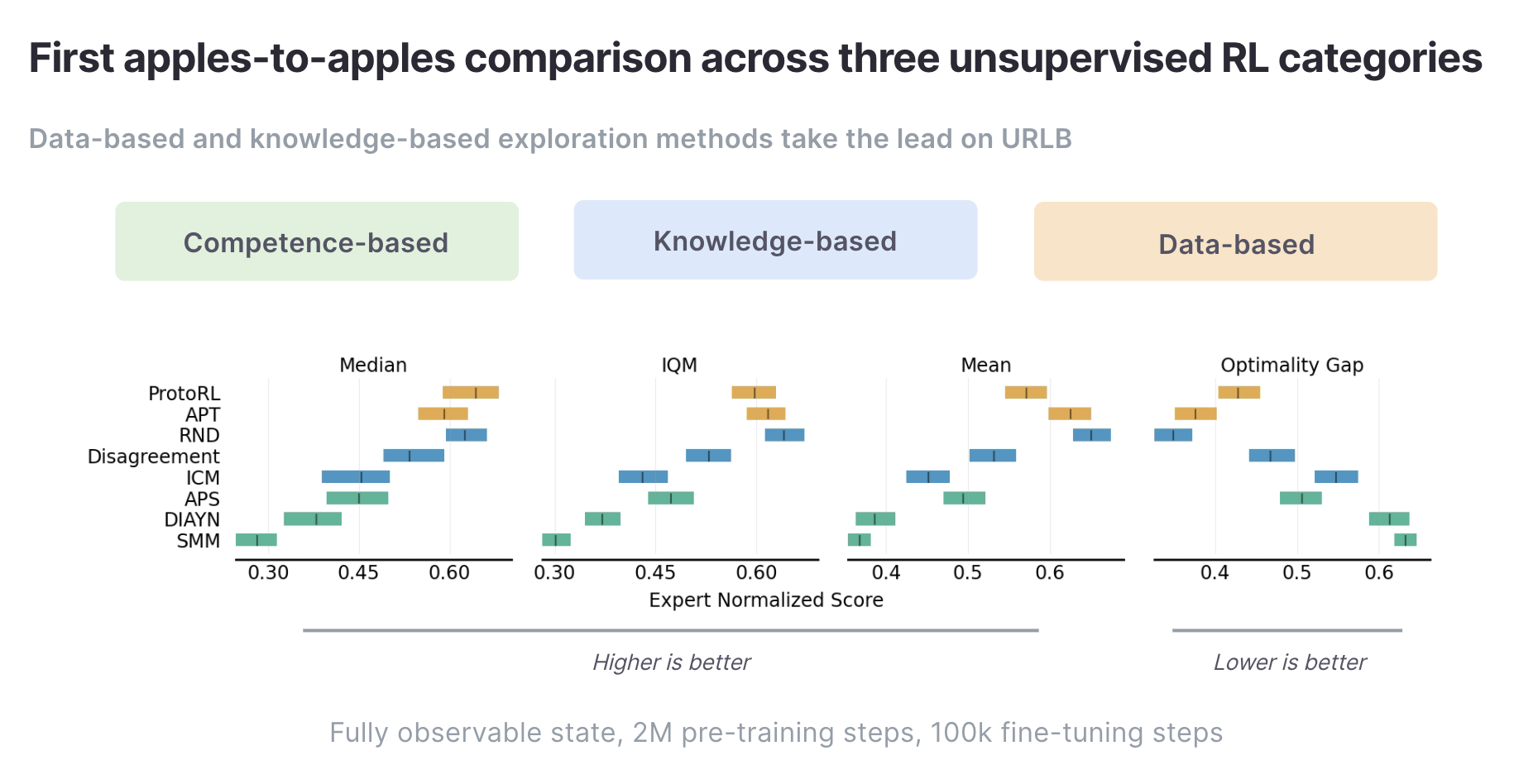
Arriba, mostramos estadísticas agregadas de ejecuciones de ajuste fino en las 12 tareas posteriores con 10 semillas cada una después del entrenamiento previo en el dominio de destino para 2M pasos. Encontramos que actualmente los métodos basados en datos (APT, ProtoRL) y RND son los enfoques principales en URLB.
También hemos identificado una serie de direcciones prometedoras para futuras investigaciones basadas en la evaluación comparativa de los métodos existentes. Por ejemplo, la exploración basada en competencias en su conjunto tiene un rendimiento inferior a la exploración basada en datos y conocimientos. Comprender por qué este es el caso es una línea interesante para futuras investigaciones. Para obtener información adicional e instrucciones para futuras investigaciones en RL sin supervisión, remitimos al lector al artículo de URLB.
El RL sin supervisión es un camino prometedor hacia el desarrollo de agentes RL generalistas. Hemos introducido un punto de referencia (URLB) para evaluar el desempeño de dichos agentes. Tenemos código de fuente abierta para URLB y esperamos que esto permita a otros investigadores crear prototipos y evaluar rápidamente algoritmos de RL sin supervisión.
Enlaces
Papel: URLB: Parámetro de aprendizaje por refuerzo no supervisado Michael Laskin *, Denis Yarats *, Hao Liu, Kimin Lee, Albert Zhan, Kevin Lu, Catherine Cang, Lerrel Pinto, Pieter Abbeel, NeurIPS, 2021, estos autores contribuyeron igualmente
Código: https://github.com/rll-research/url_benchmark