
El Departamento de Neurocirugía de Brown publicó recientemente dos preprints que comparan el rendimiento de los modelos de lenguaje grande de inteligencia artificial ChatGPT, GPT-4 y Google Bard en los exámenes de la junta escrita de neurocirugía y el banco de preguntas preparatorias de la junta oral de neurocirugía.
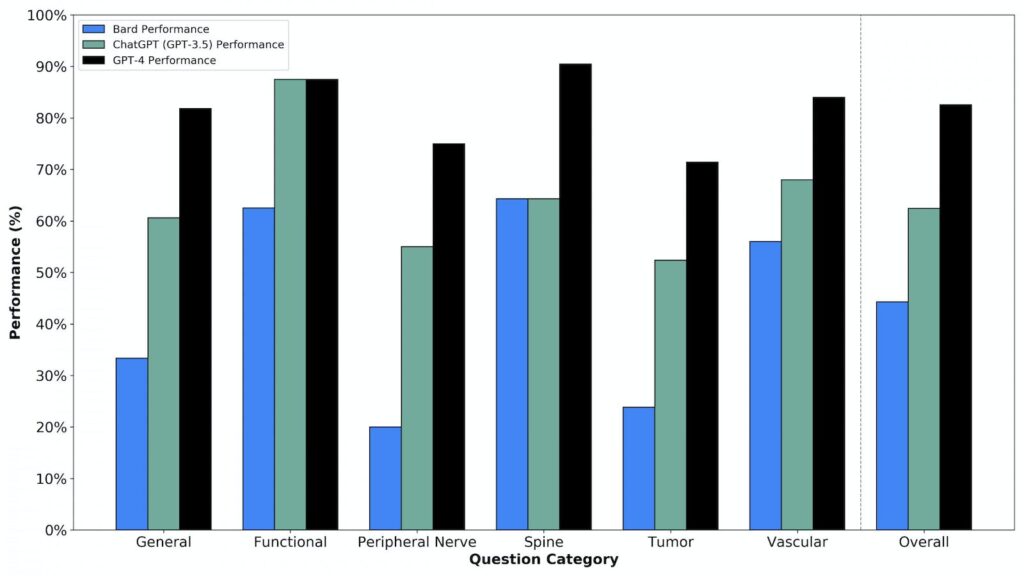
Descubrieron que estos modelos de IA podían aprobar los exámenes escritos con “gran éxito”. Cuando se les desafió a responder las preguntas más complicadas del examen oral, que requieren un pensamiento de orden superior basado en la experiencia clínica y la exposición, los modelos aún se desempeñaron «excelentemente», dijo Ziya Gokaslan, profesor y presidente de neurocirugía en la Escuela de Medicina Warren Alpert y neurocirujano. en jefe en el Hospital de Rhode Island y el Hospital Miriam.
Desde su publicación, la versión preliminar centrada en las preguntas del examen de la junta oral se ubicó en el percentil 99 del Altmetric Attention Score, que ha rastreado la cantidad de atención recibida por más de 23 millones de resultados de investigación en línea.
«Es una historia tan explosiva en el mundo y en la medicina», dijo el profesor de neurocirugía Warren Alpert Albert Telfeian, quien también es director de cirugía de columna endoscópica mínimamente invasiva en RIH y director de neurocirugía pediátrica en Hasbro Children’s Hospital.
Inspiración para el estudio y hallazgos clave
El proyecto se inspiró cuando el residente de neurocirugía de quinto año y coprimer autor Rohaid Ali estaba estudiando para su examen de la junta de neurocirugía con su amigo cercano de la Escuela de Medicina de Stanford, Ian Connolly, otro coprimer autor y residente de neurocirugía de cuarto año en el Hospital General de Massachusetts. . Habían visto que ChatGPT podía aprobar otros exámenes estandarizados, como el examen de la barra, y querían probar si ChatGPT podía responder alguna de las preguntas de su examen.
Esto llevó a Ali y Connolly a realizar estos estudios en colaboración con su tercer coautor, Oliver Tang ’19 MD’23. Descubrieron que GPT-4 era «mejor que el examinado humano promedio» y ChatGPT y Google Bard estaban al «nivel del residente de neurocirugía promedio que tomó estos exámenes simulados», dijo Ali.
«Uno de los aspectos más interesantes» del estudio fue la comparación entre los modelos de IA, ya que ha habido «muy pocas comparaciones directas estructuradas de (ellos) en cualquier campo», dijo Wael Asaad, profesor asociado de neurocirugía. y neurociencia en Warren Alpert y director del programa de epilepsia funcional y neurocirugía en RIH. Los hallazgos son «realmente emocionantes más allá de la neurocirugía», agregó.
El artículo encontró que GPT-4 superó a los otros LLM, recibiendo una puntuación de 82.6% en una serie de escenarios de manejo de casos de orden superior presentados en preguntas de exámenes orales de neurocirugía simulados.
Asaad señaló que se esperaba que GPT-4 superara a ChatGPT, que salió antes que GPT-4, así como a Google Bard. «Google se apresuró a saltar y… esa prisa se muestra en el sentido de que (Google Bard) no funciona tan bien».
Pero estos modelos aún tienen limitaciones: como los modelos basados en texto no pueden ver imágenes, obtuvieron puntajes significativamente más bajos en preguntas relacionadas con imágenes que requieren un razonamiento de orden superior. También afirmaron hechos falsos, denominados «alucinaciones», en las respuestas a estas preguntas.
Una pregunta, por ejemplo, presentaba una imagen de una parte resaltada de un brazo y preguntaba qué nervio inervaba la distribución sensorial en el área. GPT-4 evaluó correctamente que no podía responder la pregunta porque es un modelo basado en texto y no podía ver la imagen, mientras que Google Bard respondió con una respuesta «completamente inventada», dijo Ali.
“Es importante abordar la atención viral en las redes sociales que estos (modelos) han ganado, lo que sugiere que (ellos) podrían ser un neurocirujano, pero también es importante aclarar que estos modelos aún no están listos para el horario estelar y no deben considerarse un reemplazo para las actividades humanas actualmente”, agregó Ali. “Como neurocirujanos, es crucial que integremos de manera segura los modelos de IA para el uso de los pacientes e investiguemos activamente sus puntos ciegos para garantizar la mejor atención posible para los pacientes”.
Asaad agregó que en escenarios clínicos reales, los neurocirujanos podrían recibir información engañosa o irrelevante. Los LLM “no se desempeñan muy bien en estos escenarios del mundo real que son más abiertos y menos claros”, dijo.
Consideraciones éticas con la medicina y la IA
También hubo casos en los que la respuesta correcta del modelo de IA a ciertos escenarios sorprendió a los investigadores.
Para una pregunta sobre una lesión grave por arma de fuego en la cabeza, la respuesta fue que probablemente no haya una intervención quirúrgica que altere significativamente la trayectoria del curso de la enfermedad. “Fascinantemente, estos chatbots de IA estaban dispuestos a seleccionar esa respuesta”, dijo Ali.
“Eso es algo que no esperábamos (y) algo que vale la pena considerar”, dijo Ali. «Si estos modelos de IA nos dieran recomendaciones éticas en esta área, ¿qué implicaciones tiene eso para nuestro campo o el campo de la medicina en general?»
Recibe The Herald en tu bandeja de entrada todos los días.
Otra preocupación es que estos modelos se entrenan con datos de ensayos clínicos que históricamente han subrepresentado a ciertas comunidades desfavorecidas. “Debemos estar atentos a los riesgos potenciales de propagar las disparidades en la salud y abordar estos sesgos… para evitar recomendaciones dañinas”, dijo Ali.
Asaad agregó que «no es algo exclusivo de esos sistemas, muchos humanos tienen prejuicios, por lo que solo se trata de tratar de comprender ese sesgo y eliminarlo del sistema».
Telfeian también abordó la importancia de las conexiones humanas entre médicos y pacientes de las que aún carecen los modelos de IA. “Si su médico estableció un terreno común con usted, como decir ‘oh, usted es de aquí o fue a esta escuela’, entonces, de repente, está más dispuesto a aceptar lo que le recomendarían”, dijo.
“Eliminar al cirujano de la ecuación no está en el futuro previsible”, dijo Curt Doberstein, profesor de neurocirugía en Warren Alpert y director de cirugía cerebrovascular en RIH. «Veo (IA) como una gran ayuda tanto para los pacientes como para los médicos, pero hay muchas capacidades que aún no existen».
Futuro de la IA en medicina
Con respecto al futuro de los modelos de IA en la medicina, Asaad predijo que “el factor humano se reducirá lentamente, y cualquiera que no lo vea de esa manera, que piense que hay algo mágico en lo que hacen los humanos… se está perdiendo lo más profundo”. imagen de lo que significa tener inteligencia».
“La inteligencia no es magia. Es solo un proceso que estamos comenzando a aprender a replicar en sistemas artificiales”, dijo Asaad.
Asaad también dijo que ve futuras aplicaciones de IA para servir como asistentes de proveedores médicos.
Debido a que el campo de la medicina avanza rápidamente, es difícil para los proveedores mantenerse al día con los nuevos desarrollos que los ayudarían a evaluar los casos, dijo. Los modelos de IA podrían «brindarle ideas o recursos que sean relevantes para el problema que enfrenta clínicamente».
Doberstein también destacó el papel de la IA que ayuda con la documentación y la comunicación del paciente para ayudar a aliviar el agotamiento del proveedor, aumentar la seguridad del paciente y promover las interacciones médico-paciente.
Gokaslan agregó que «no hay duda de que estos sistemas llegarán a la medicina y la cirugía, y creo que serán extremadamente útiles, pero creo que debemos tener cuidado al probarlos de manera efectiva y usarlos con cuidado».
“Estamos en la punta del iceberg: estas cosas acaban de salir”, dijo Doberstein. «Va a ser un proceso en el que todos en la ciencia tendrán que aprender y adaptarse constantemente a todas las nuevas tecnologías y cambios que surjan».
“Esa es la parte emocionante”, agregó Doberstein.
Gabriella es la editora sénior de ciencia e investigación de The Brown Daily Herald. Ella es una estudiante de tercer año de San Francisco que estudia neurociencia en la pista premédica.
