
El aprendizaje por refuerzo no supervisado (RL), en el que los agentes de RL se entrenan previamente con recompensas autosupervisadas, es un paradigma emergente para desarrollar agentes de RL que sean capaces de generalizar. Recientemente, lanzamos el punto de referencia RL no supervisado (URLB) que cubrimos en una publicación anterior. URLB comparó muchos algoritmos de RL no supervisados en tres categorías: algoritmos basados en competencias, basados en conocimientos y basados en datos. Un hallazgo sorprendente fue que los algoritmos basados en competencias tuvieron un desempeño significativamente inferior al de otras categorías. En esta publicación, desmitificaremos qué ha estado frenando los métodos basados en competencias e introduciremos el Control intrínseco contrastivo (CIC), un nuevo algoritmo basado en competencias que es el primero en lograr resultados destacados en URLB.
Resultados de la evaluación comparativa de algoritmos RL no supervisados
En resumen, los métodos basados en competencias (que trataremos en detalle) maximizan la información mutua entre estados y habilidades (p. ej., DIAYN), los métodos basados en conocimientos maximizan el error de un modelo predictivo (p. ej., Curiosity) y los métodos basados en datos maximizan la diversidad de datos observados (por ejemplo, APT). Al evaluar estos algoritmos en URLB mediante un entrenamiento previo sin recompensa para 2 millones de pasos seguidos de 100 000 pasos de ajuste fino en 12 tareas posteriores, encontramos previamente la siguiente clasificación de pila de algoritmos de las tres categorías.
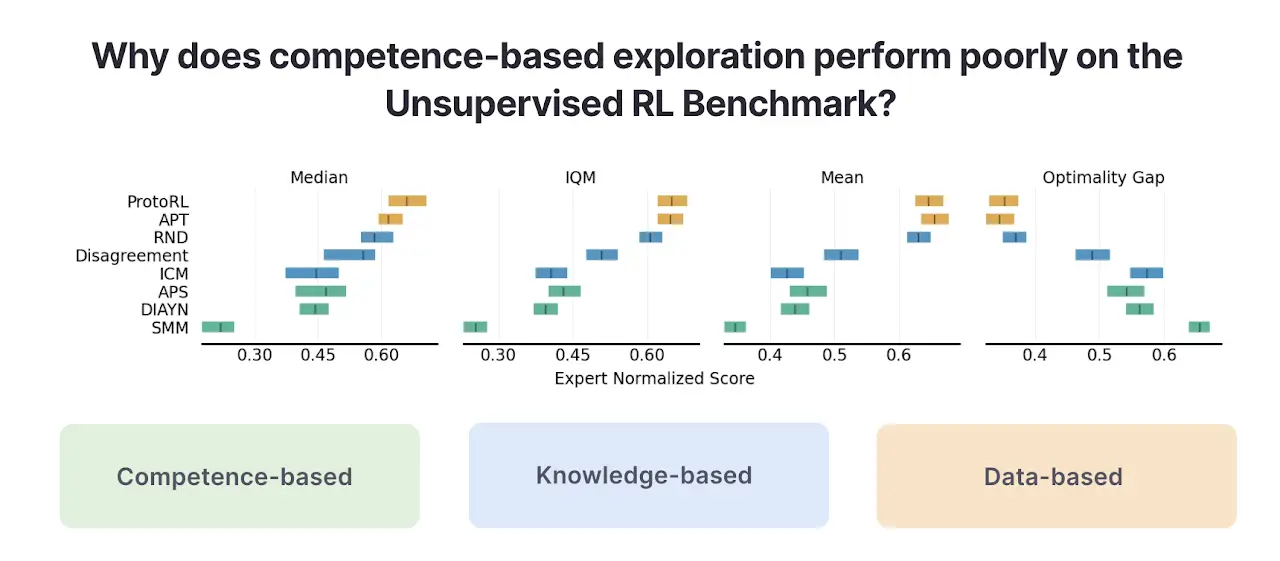
En la figura anterior, los métodos basados en competencias (en verde) funcionan sustancialmente peor que los otros dos tipos de algoritmos de RL no supervisados. ¿Por qué es así y qué podemos hacer para solucionarlo?
Exploración basada en competencias
Como introducción rápida, los algoritmos basados en competencias maximizan la información mutua entre alguna variable observada, como un estado y un vector de habilidad latente, que generalmente se muestrea a partir del ruido.
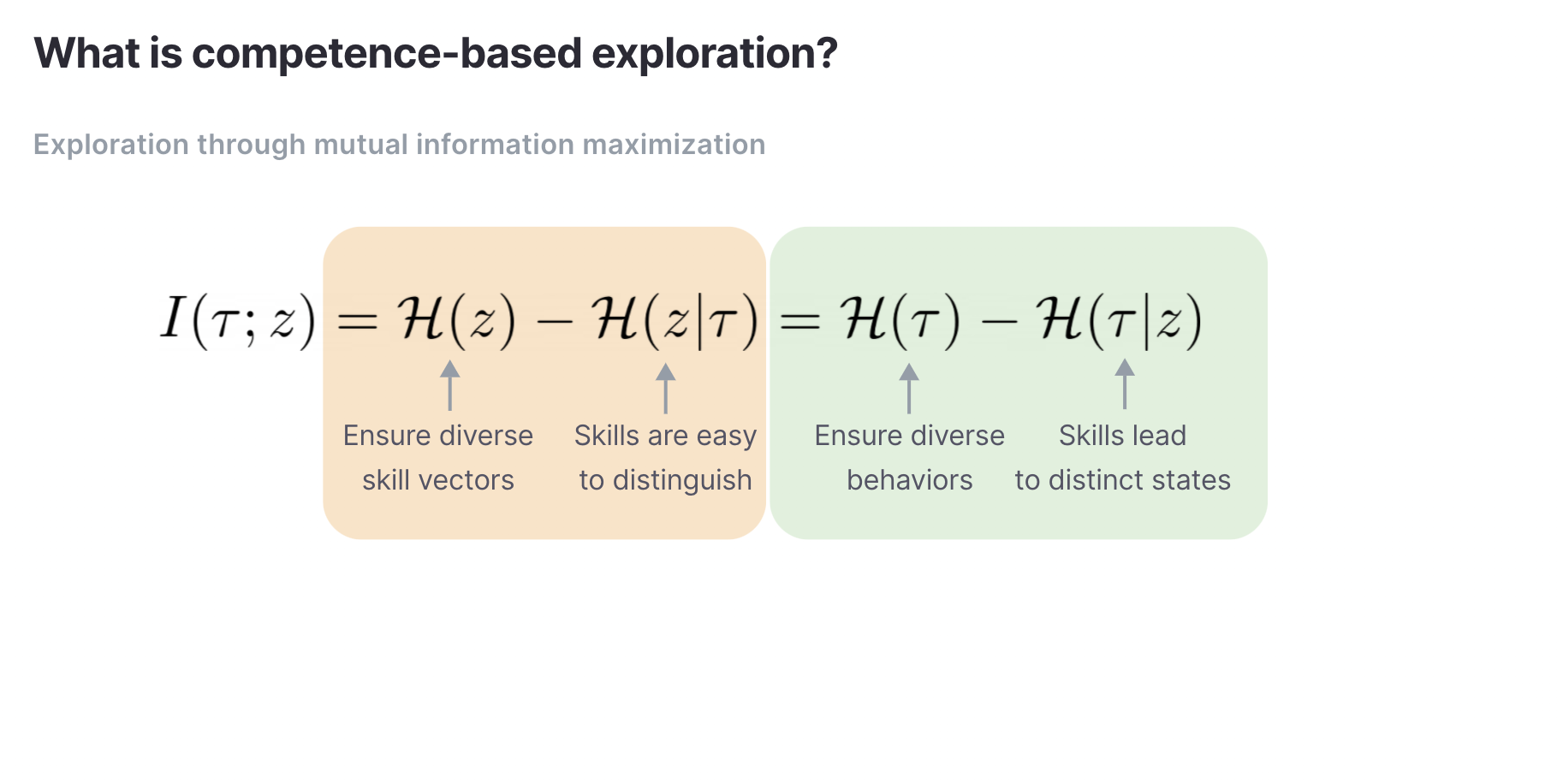
La información mutua suele ser una cantidad intratable y dado que queremos maximizarla, por lo general es mejor maximizar un límite inferior variacional.

La cantidad q(z|tau) se conoce como el discriminador. En trabajos anteriores, los discriminadores son clasificadores sobre habilidades discretas o regresores sobre habilidades continuas. El problema es que las tareas de clasificación y regresión necesitan un número exponencial de muestras de datos diversas para ser precisas. En entornos simples donde el número de comportamientos potenciales es pequeño, los métodos actuales basados en competencias funcionan, pero no en entornos donde el conjunto de comportamientos potenciales es grande y diverso.
Cómo influye el diseño del entorno en el rendimiento
Para ilustrar este punto, ejecutemos tres algoritmos en OpenAI Gym y DeepMind Control (DMC) Hopper. Gym Hopper se reinicia cuando el agente pierde el equilibrio mientras que los episodios de DMC tienen una duración fija, independientemente de si el agente se cae. Al reiniciarse temprano, Gym Hopper restringe al agente a una pequeña cantidad de comportamientos que se pueden lograr si se mantiene el equilibrio. Ejecutamos tres algoritmos: DIAYN e ICM, algoritmos populares basados en competencias y conocimientos, así como un agente «fijo» que obtiene una recompensa de +1 por cada paso de tiempo, y medimos la recompensa extrínseca de tiro cero por saltar durante el auto. -Pre-entrenamiento supervisado.
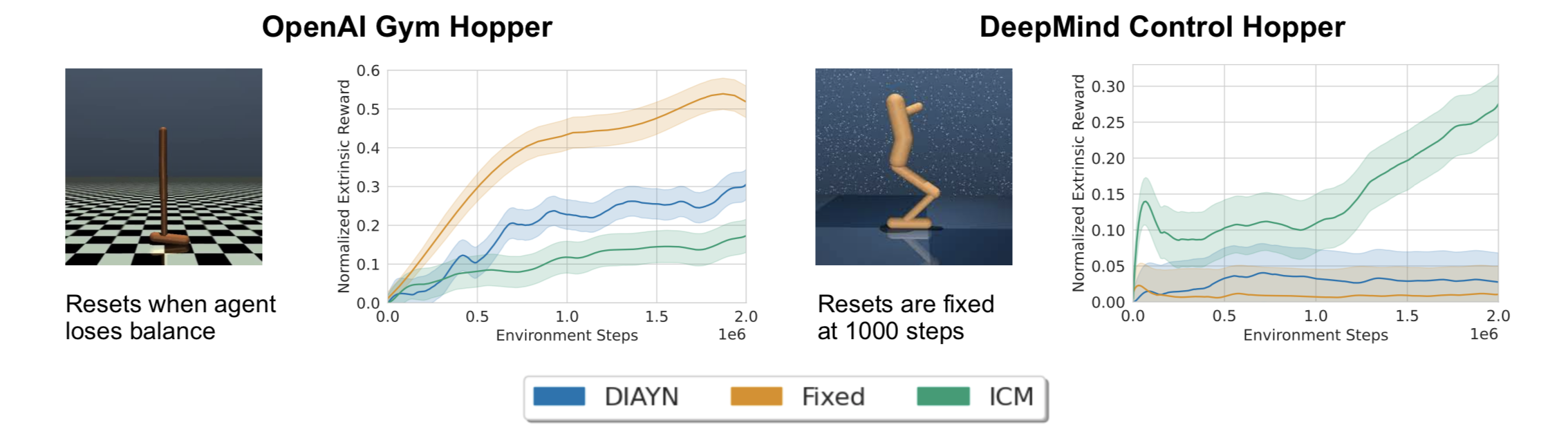
En OpenAI Gym, tanto DIAYN como el agente fijo reciben recompensas extrínsecas más altas en relación con ICM, pero en DeepMind Control Hopper, ambos algoritmos colapsan. La única diferencia significativa entre los dos entornos es que OpenAI Gym se reinicia antes, mientras que DeepMind Control no. Esto respalda la hipótesis de que cuando un entorno admite muchos comportamientos, los enfoques previos basados en competencias luchan por aprender habilidades útiles.
De hecho, si visualizamos los comportamientos aprendidos por DIAYN en otros entornos de DeepMind Control, vemos que aprende un pequeño conjunto de habilidades estáticas.
Los métodos anteriores no logran aprender diversos comportamientos.






Habilidades aprendidas por DIAYN después de 2 millones de pasos de entrenamiento.
Exploración efectiva basada en competencias con control intrínseco contrastivo (CIC)
Como se ilustra en el ejemplo anterior, los entornos complejos admiten una gran cantidad de habilidades y, por lo tanto, necesitamos discriminadores capaces de admitir grandes espacios de habilidades. Esta tensión entre la necesidad de soportar grandes espacios de habilidades y la limitación de los discriminadores actuales nos lleva a proponer el Control Intrínseco Contrastivo (CIC).
El control intrínseco contrastivo (CIC) introduce un nuevo estimador de densidad contrastivo para aproximar la entropía condicional (el discriminador). A diferencia del aprendizaje contrastivo visual, este objetivo contrastivo opera sobre transiciones de estado y Vectores de habilidades. Esto nos permite llevar una poderosa maquinaria de aprendizaje de representación desde la visión hasta el descubrimiento de habilidades sin supervisión.
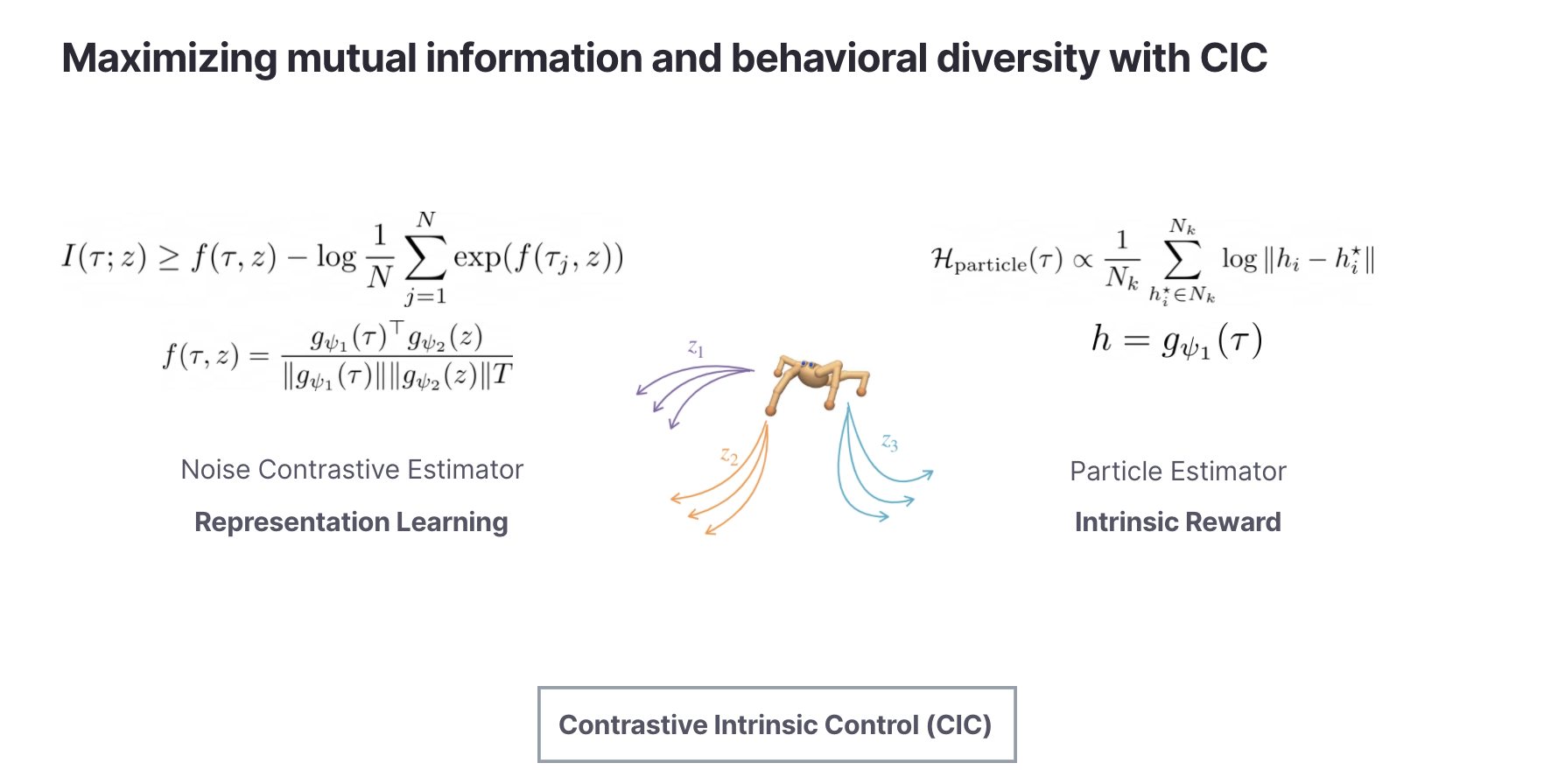
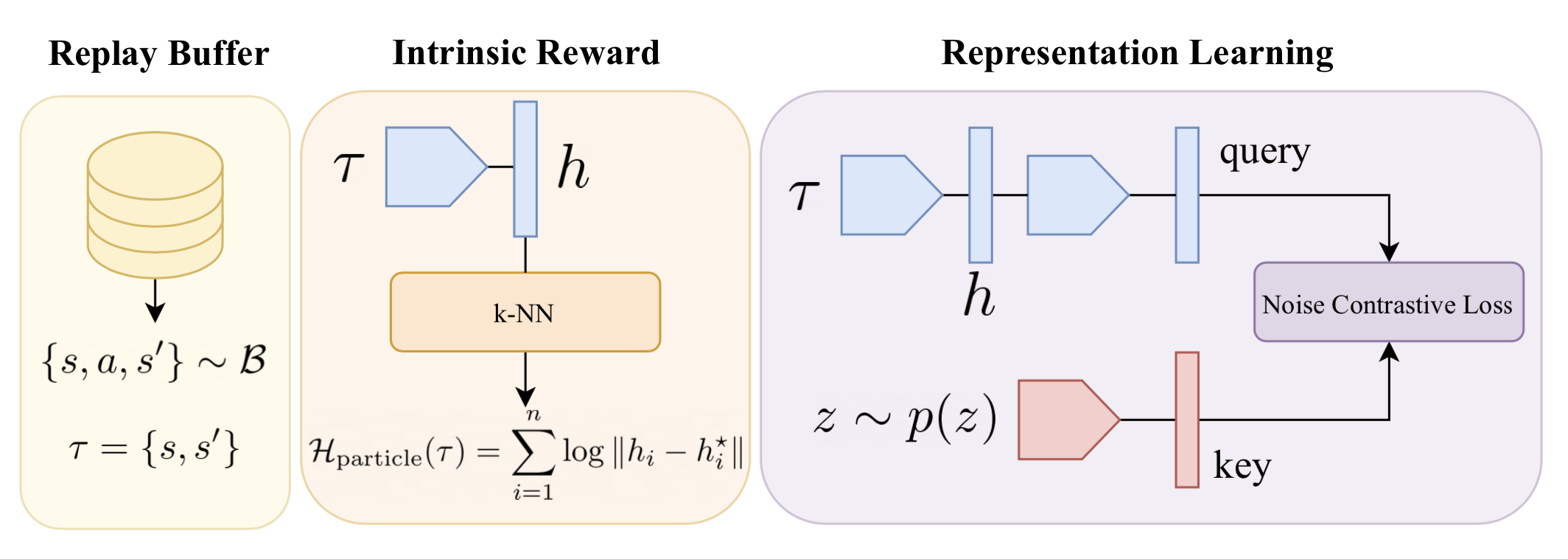
Para un algoritmo práctico, utilizamos el aprendizaje de habilidades contrastivas CIC como una pérdida auxiliar durante el pre-entrenamiento. La recompensa intrínseca autosupervisada es el valor de la estimación de entropía calculada sobre las incrustaciones de CIC. También analizamos otras formas de recompensas intrínsecas en el documento, pero esta variante simple funciona bien con una complejidad mínima. La arquitectura CIC tiene la siguiente forma:
Cualitativamente, los comportamientos de CIC después de 2 millones de pasos de preentrenamiento son bastante diversos.
Comportamientos diversos aprendidos con CIC






Habilidades aprendidas por CIC después de 2 millones de pasos de capacitación.
Con la exploración explícita a través del término de entropía de transición de estado y el discriminador de habilidad contrastivo para el aprendizaje de representación, CIC se adapta de manera extremadamente eficiente a las tareas posteriores, superando los enfoques anteriores basados en competencias al 1.78x y todos los métodos de exploración anteriores por 1.19x en la URLB basada en el estado.
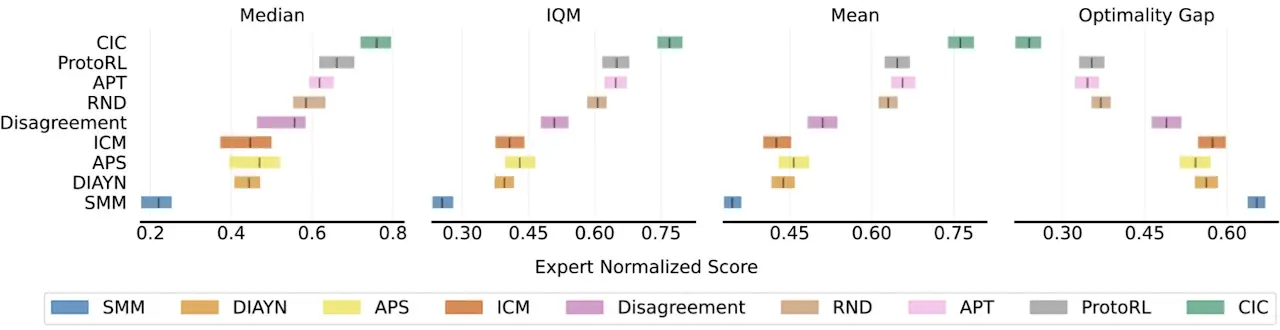
Proporcionamos más información en el documento CIC sobre cómo los detalles arquitectónicos y la dimensión de la habilidad afectan el rendimiento del documento CIC. La conclusión principal de CIC es que no hay nada de malo en el objetivo basado en competencias de maximizar la información mutua. Sin embargo, lo que importa es qué tan bien nos aproximamos a este objetivo, especialmente en entornos que soportan una gran cantidad de comportamientos. CIC es el primer algoritmo basado en competencias que logra un desempeño líder en URLB. Nuestra esperanza es que nuestro enfoque aliente a otros investigadores a trabajar en nuevos algoritmos de RL no supervisados.
Enlaces
Papel: CIC: control intrínseco contrastivo para el descubrimiento de habilidades sin supervisión Michael Laskin, Hao Liu, Xue Bin Peng, Denis Yarats, Aravind Rajeswaran, Pieter Abbeel
Código: https://github.com/rll-research/cic