
El descenso de gradiente es un algoritmo de optimización que sigue el gradiente negativo de una función objetivo para localizar el mínimo de la función.
Una limitación del descenso de gradiente es que usa el mismo tamaño de paso (tasa de aprendizaje) para cada variable de entrada. AdaGradn y RMSProp son extensiones del descenso de gradiente que agregan una tasa de aprendizaje autoadaptable para cada parámetro de la función objetivo.
Adadelta se puede considerar una extensión adicional del descenso de gradiente que se basa en AdaGrad y RMSProp y cambia el cálculo del tamaño de paso personalizado para que las unidades sean consistentes y, a su vez, ya no requiera un hiperparámetro de tasa de aprendizaje inicial.
En este tutorial, descubrirá cómo desarrollar el descenso de gradiente con el algoritmo de optimización Adadelta desde cero.
Después de completar este tutorial, sabrá:
- El descenso de gradiente es un algoritmo de optimización que utiliza el gradiente de la función objetivo para navegar por el espacio de búsqueda.
- El descenso de gradiente se puede actualizar para usar un tamaño de paso adaptativo automáticamente para cada variable de entrada usando un promedio decreciente de derivadas parciales, llamado Adadelta.
- Cómo implementar el algoritmo de optimización Adadelta desde cero y aplicarlo a una función objetivo y evaluar los resultados.
Empecemos.

Descenso degradado con Adadelta desde cero
Foto de Robert Minkler, algunos derechos reservados.
Descripción general del tutorial
Este tutorial se divide en tres partes; ellos son:
- Descenso de gradiente
- Algoritmo de Adadelta
- Descenso de gradiente con Adadelta
- Problema de prueba bidimensional
- Optimización del descenso de gradientes con Adadelta
- Visualización de Adadelta
Descenso de gradiente
El descenso de gradientes es un algoritmo de optimización.
Técnicamente se le conoce como un algoritmo de optimización de primer orden, ya que hace uso explícito de la derivada de primer orden de la función objetivo de destino.
Los métodos de primer orden se basan en la información del gradiente para ayudar a dirigir la búsqueda de un mínimo …
– Página 69, Algoritmos de optimización, 2019.
La derivada de primer orden, o simplemente la «derivado, ”Es la tasa de cambio o pendiente de la función objetivo en un punto específico, p. para una entrada específica.
Si la función de destino toma múltiples variables de entrada, se denomina función multivariante y las variables de entrada se pueden considerar como un vector. A su vez, la derivada de una función objetivo multivariante también puede tomarse como un vector y se denomina generalmente gradiente.
- Degradado: Derivada de primer orden para una función objetivo multivariante.
La derivada o el gradiente apunta en la dirección del ascenso más pronunciado de la función de destino para una entrada específica.
El descenso de gradiente se refiere a un algoritmo de optimización de minimización que sigue el negativo del gradiente cuesta abajo de la función objetivo para localizar el mínimo de la función.
El algoritmo de descenso de gradiente requiere una función objetivo que se está optimizando y la función derivada para la función objetivo. La función objetivo F() devuelve una puntuación para un conjunto dado de entradas y la función derivada F'() da la derivada de la función objetivo para un conjunto dado de entradas.
El algoritmo de descenso de gradiente requiere un punto de partida (X) en el problema, como un punto seleccionado al azar en el espacio de entrada.
Luego se calcula la derivada y se da un paso en el espacio de entrada que se espera que resulte en un movimiento cuesta abajo en la función objetivo, asumiendo que estamos minimizando la función objetivo.
Un movimiento cuesta abajo se realiza calculando primero qué tan lejos moverse en el espacio de entrada, calculado como el tamaño de los pasos (llamado alfa o tasa de aprendizaje) multiplicado por el gradiente. Esto luego se resta del punto actual, asegurando que nos movemos contra el gradiente o hacia abajo de la función de destino.
- x = x – tamaño_paso * f ‘(x)
Cuanto más pronunciada sea la función objetivo en un punto dado, mayor será la magnitud del gradiente y, a su vez, mayor será el paso dado en el espacio de búsqueda. El tamaño del paso realizado se escala mediante un hiperparámetro de tamaño de paso.
- Numero de pie (alfa): Hiperparámetro que controla qué tan lejos moverse en el espacio de búsqueda contra el gradiente en cada iteración del algoritmo.
Si el tamaño del paso es demasiado pequeño, el movimiento en el espacio de búsqueda será pequeño y la búsqueda llevará mucho tiempo. Si el tamaño del paso es demasiado grande, la búsqueda puede rebotar en el espacio de búsqueda y omitir los óptimos.
Ahora que estamos familiarizados con el algoritmo de optimización del descenso de gradientes, echemos un vistazo a Adadelta.
Algoritmo de Adadelta
Adadelta (o «ADADELTA») es una extensión del algoritmo de optimización del descenso de gradientes.
El algoritmo fue descrito en el artículo de 2012 por Matthew Zeiler titulado «ADADELTA: An Adaptive Learning Rate Method».
Adadelta está diseñado para acelerar el proceso de optimización, p. Ej. disminuir el número de evaluaciones de funciones requeridas para alcanzar los óptimos, o para mejorar la capacidad del algoritmo de optimización, p. dar como resultado un mejor resultado final.
Se entiende mejor como una extensión de los algoritmos AdaGrad y RMSProp.
AdaGrad es una extensión del descenso de gradiente que calcula un tamaño de paso (tasa de aprendizaje) para cada parámetro de la función objetivo cada vez que se realiza una actualización. El tamaño del paso se calcula sumando primero las derivadas parciales para el parámetro visto hasta ahora durante la búsqueda, luego dividiendo el hiperparámetro del tamaño del paso inicial por la raíz cuadrada de la suma de las derivadas parciales al cuadrado.
El cálculo del tamaño de paso personalizado para un parámetro con AdaGrad es el siguiente:
- tamaño_paso_cust (t + 1) = tamaño_paso / (1e-8 + sqrt (s
Dónde cust_step_size (t + 1) es el tamaño de paso calculado para una variable de entrada para un punto dado durante la búsqueda, Numero de pie es el tamaño del paso inicial, sqrt () es la operación de raíz cuadrada, y S t) es la suma de las derivadas parciales cuadradas para la variable de entrada vista durante la búsqueda hasta el momento (incluida la iteración actual).
Se puede pensar en RMSProp como una extensión de AdaGrad en el sentido de que utiliza un promedio decreciente o promedio móvil de las derivadas parciales en lugar de la suma en el cálculo del tamaño de paso para cada parámetro. Esto se logra agregando un nuevo hiperparámetro «rho”Que actúa como un impulso para las derivadas parciales.
El cálculo de la derivada parcial cuadrática de la media móvil decreciente para un parámetro es el siguiente:
- s (t + 1) = (s
Dónde s (t + 1) es la derivada parcial cuadrática media de un parámetro para la iteración actual del algoritmo, S t) es la derivada parcial cuadrática media móvil decreciente de la iteración anterior, f ‘(x
Adadelta es una extensión adicional de RMSProp diseñada para mejorar la convergencia del algoritmo y eliminar la necesidad de una tasa de aprendizaje inicial especificada manualmente.
La idea presentada en este artículo se derivó de ADAGRAD con el fin de mejorar los dos principales inconvenientes del método: 1) el deterioro continuo de las tasas de aprendizaje a lo largo de la formación, y 2) la necesidad de una tasa de aprendizaje global seleccionada manualmente.
– ADADELTA: Un método de tasa de aprendizaje adaptativo, 2012.
El promedio móvil decreciente de la derivada parcial al cuadrado se calcula para cada parámetro, como con RMSProp. La diferencia clave está en el cálculo del tamaño del paso para un parámetro que usa el promedio decreciente del delta o cambio en el parámetro.
Esta elección de numerador fue para asegurar que ambas partes del cálculo tengan las mismas unidades.
Después de derivar de forma independiente la actualización RMSProp, los autores notaron que las unidades en las ecuaciones de actualización para el descenso del gradiente, el impulso y Adagrad no coinciden. Para solucionar este problema, utilizan un promedio en declive exponencial de las actualizaciones cuadradas.
– Páginas 78-79, Algoritmos de optimización, 2019.
Primero, el tamaño de paso personalizado se calcula como la raíz cuadrada de la media móvil decreciente del cambio en el delta dividida por la raíz cuadrada de la media móvil decreciente de las derivadas parciales cuadradas.
- cust_step_size (t + 1) = (ep + sqrt (delta
Dónde cust_step_size (t + 1) es el tamaño de paso personalizado para un parámetro para una actualización determinada, ep es un hiperparámetro que se suma al numerador y al denominador para evitar un error de división por cero, delta
La ep El hiperparámetro se establece en un valor pequeño, como 1e-3 o 1e-8. Además de evitar un error de división por cero, también ayuda con el primer paso del algoritmo cuando el cambio cuadrático medio móvil decreciente y el gradiente cuadrado medio móvil decreciente son cero.
A continuación, el cambio en el parámetro se calcula como el tamaño del paso personalizado multiplicado por la derivada parcial
- cambiar (t + 1) = tamaño_paso_personalizado (t + 1) * f ‘(x
A continuación, se actualiza el promedio decreciente del cambio al cuadrado del parámetro.
- delta (t + 1) = (delta
Dónde delta (t + 1) es el promedio decreciente del cambio en la variable que se utilizará en la siguiente iteración, cambiar (t + 1) se calculó en el paso anterior y rho es un hiperparámetro que actúa como impulso y tiene un valor como 0,9.
Finalmente, el nuevo valor de la variable se calcula utilizando el cambio.
- x (t + 1) = x
Luego, este proceso se repite para cada variable de la función objetivo, luego se repite todo el proceso para navegar por el espacio de búsqueda para un número fijo de iteraciones del algoritmo.
Ahora que estamos familiarizados con el algoritmo Adadelta, exploremos cómo podríamos implementarlo y evaluar su rendimiento.
Descenso de gradiente con Adadelta
En esta sección, exploraremos cómo implementar el algoritmo de optimización del descenso de gradientes con Adadelta.
Problema de prueba bidimensional
Primero, definamos una función de optimización.
Usaremos una función bidimensional simple que eleva al cuadrado la entrada de cada dimensión y define el rango de entradas válidas de -1.0 a 1.0.
La función objetivo () a continuación implementa esta función
|
# función objetiva def objetivo(X, y): regreso X**2.0 + y **2.0 |
Podemos crear una gráfica tridimensional del conjunto de datos para tener una idea de la curvatura de la superficie de respuesta.
El ejemplo completo de trazado de la función objetivo se enumera a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 dieciséis 17 18 19 20 21 22 23 24 |
# Gráfico 3d de la función de prueba de numpy importar arange de numpy importar rejilla de matplotlib importar pyplot # función objetiva def objetivo(X, y): regreso X**2.0 + y **2.0 # definir rango para entrada r_min, r_max = –1.0, 1.0 # rango de entrada de muestra uniformemente en incrementos de 0.1 xaxis = arange(r_min, r_max, 0,1) yaxis = arange(r_min, r_max, 0,1) # crea una malla a partir del eje X, y = rejilla(xaxis, yaxis) # calcular objetivos resultados = objetivo(X, y) # crea un gráfico de superficie con el esquema de color jet figura = pyplot.figura() eje = figura.gca(proyección=‘3d’) eje.plot_surface(X, y, resultados, cmap=‘chorro’) # mostrar la trama pyplot.show() |
La ejecución del ejemplo crea un gráfico de superficie tridimensional de la función objetivo.
Podemos ver la forma familiar de cuenco con los mínimos globales en f (0, 0) = 0.
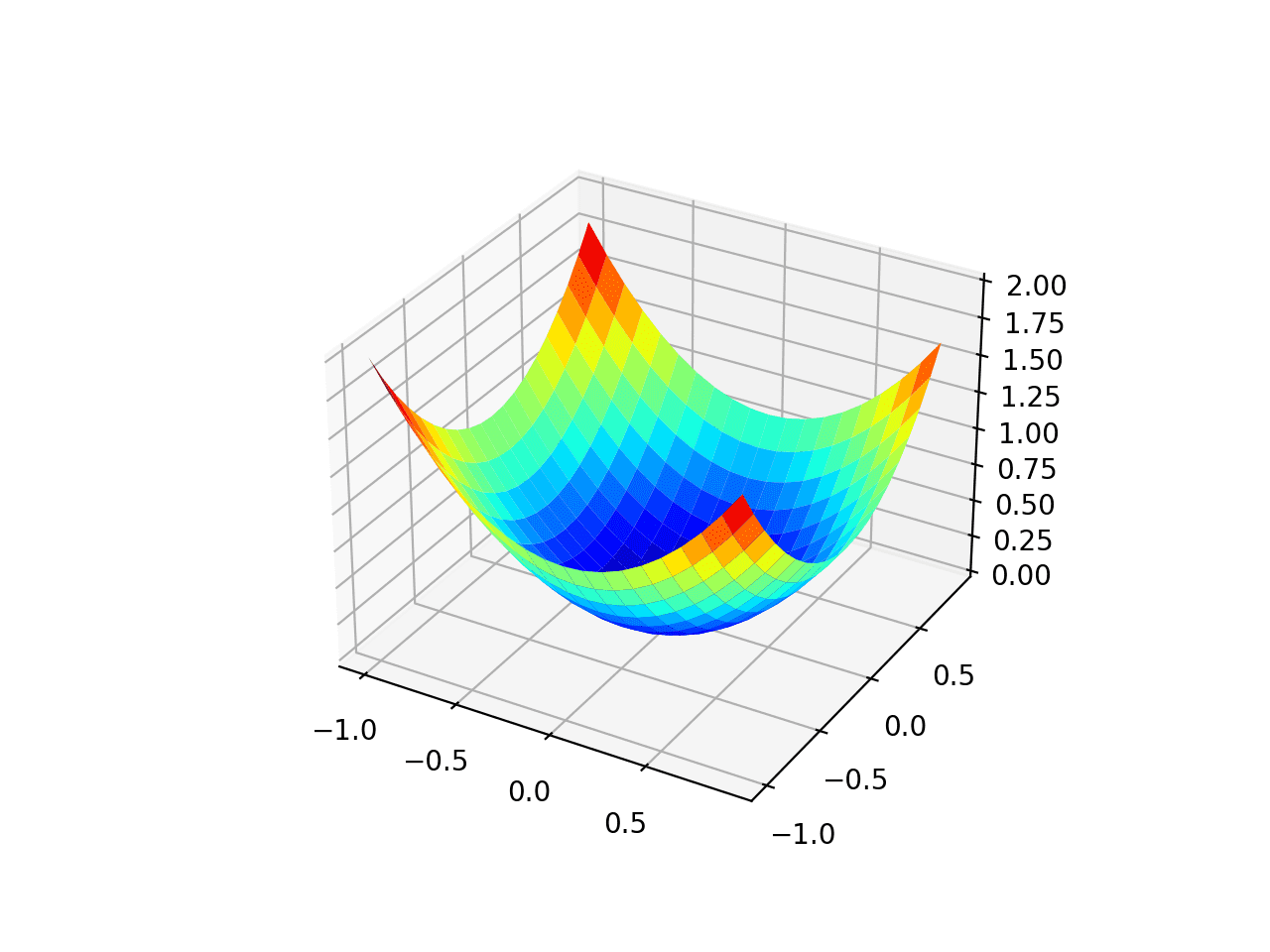
Gráfico tridimensional de la función objetivo de prueba
También podemos crear una gráfica bidimensional de la función. Esto será útil más adelante cuando queramos trazar el progreso de la búsqueda.
El siguiente ejemplo crea un gráfico de contorno de la función objetivo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 dieciséis 17 18 19 20 21 22 23 |
# gráfica de contorno de la función de prueba de numpy importar asarray de numpy importar arange de numpy importar rejilla de matplotlib importar pyplot # función objetiva def objetivo(X, y): regreso X**2.0 + y **2.0 # definir rango para entrada límites = asarray([[[[–1.0, 1.0], [[–1.0, 1.0]]) # rango de entrada de muestra uniformemente en incrementos de 0.1 xaxis = arange(límites[[0,0], límites[[0,1], 0,1) yaxis = arange(límites[[1,0], límites[[1,1], 0,1) # crea una malla a partir del eje X, y = rejilla(xaxis, yaxis) # calcular objetivos resultados = objetivo(X, y) # crear un gráfico de contorno relleno con 50 niveles y esquema de color jet pyplot.contourf(X, y, resultados, niveles=50, cmap=‘chorro’) # mostrar la trama pyplot.show() |
La ejecución del ejemplo crea un gráfico de contorno bidimensional de la función objetivo.
Podemos ver la forma del cuenco comprimida a los contornos mostrados con un degradado de color. Usaremos este gráfico para trazar los puntos específicos explorados durante el progreso de la búsqueda.
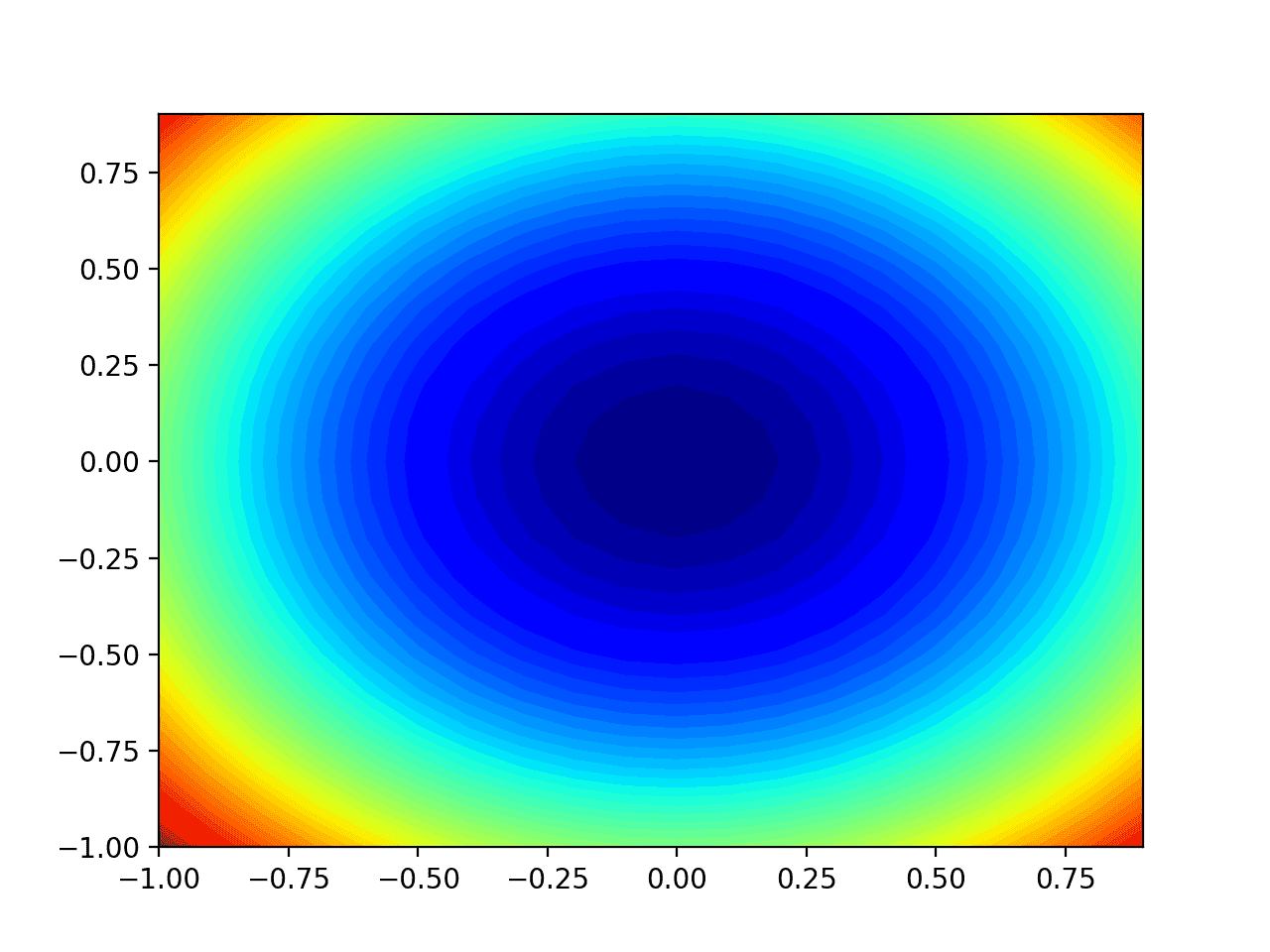
Gráfico de contorno bidimensional de la función objetivo de prueba
Ahora que tenemos una función de objetivo de prueba, veamos cómo podríamos implementar el algoritmo de optimización de Adadelta.
Optimización del descenso de gradientes con Adadelta
Podemos aplicar el descenso de gradiente con Adadelta al problema de prueba.
Primero, necesitamos una función que calcule la derivada de esta función.
La derivada de x ^ 2 es x * 2 en cada dimensión. La función derivada () implementa esto a continuación.
|
# derivada de la función objetivo def derivado(X, y): regreso asarray([[X * 2.0, y * 2.0]) |
A continuación, podemos implementar la optimización del descenso de gradientes.
Primero, podemos seleccionar un punto aleatorio en los límites del problema como punto de partida para la búsqueda.
Esto supone que tenemos una matriz que define los límites de la búsqueda con una fila para cada dimensión y la primera columna define el mínimo y la segunda columna define el máximo de la dimensión.
|
... # generar un punto inicial solución = límites[[:, 0] + rand(len(límites)) * (límites[[:, 1] – límites[[:, 0]) |
A continuación, necesitamos inicializar el promedio decreciente de las derivadas parciales al cuadrado y el cambio al cuadrado para cada dimensión a valores de 0.0.
|
... # lista de gradientes cuadrados promedio para cada variable sq_grad_avg = [[0.0 por _ en distancia(límites.forma[[0])] # lista de actualizaciones de parámetros promedio sq_para_avg = [[0.0 por _ en distancia(límites.forma[[0])] |
Luego podemos enumerar un número fijo de iteraciones del algoritmo de optimización de búsqueda definido por un «nitro”Hiperparámetro.
|
... # ejecutar el descenso de gradiente por eso en distancia(nitro): ... |
El primer paso es calcular el gradiente para la solución actual usando el derivado() función.
|
... # calcular gradiente degradado = derivado(solución[[0], solución[[1]) |
Luego, necesitamos calcular el cuadrado de la derivada parcial y actualizar la media móvil decreciente de las derivadas parciales al cuadrado con “rho”Hiperparámetro.
|
... # actualizar el promedio de las derivadas parciales cuadradas por I en distancia(degradado.forma[[0]): # calcular el gradiente al cuadrado sg = degradado[[I]**2.0 # actualizar la media móvil del gradiente al cuadrado sq_grad_avg[[I] = (sq_grad_avg[[I] * rho) + (sg * (1.0–rho)) |
Luego, podemos usar la media móvil decreciente de las derivadas parciales cuadradas y el gradiente para calcular el tamaño del paso para el siguiente punto. Haremos esto una variable a la vez.
|
... # construir solución nueva_solución = lista() por I en distancia(solución.forma[[0]): ... |
Primero, calcularemos el tamaño de paso personalizado para esta variable en esta iteración utilizando el promedio móvil decreciente de los cambios al cuadrado y las derivadas parciales al cuadrado, así como el hiperparámetro «ep».
|
... # calcular el tamaño del paso para esta variable alfa = (ep + sqrt(sq_para_avg[[I])) / (ep + sqrt(sq_grad_avg[[I])) |
A continuación, podemos usar el tamaño de paso personalizado y la derivada parcial para calcular el cambio en la variable.
|
... # calcula el cambio cambio = alfa * degradado[[I] |
Luego podemos usar el cambio para actualizar el promedio móvil decreciente del cambio al cuadrado usando el «rho”Hiperparámetro.
|
... # actualizar la media móvil de los cambios de parámetros al cuadrado sq_para_avg[[I] = (sq_para_avg[[I] * rho) + (cambio**2.0 * (1.0–rho)) |
Finalmente, podemos cambiar la variable y almacenar el resultado antes de pasar a la siguiente variable.
|
... # calcular la nueva posición en esta variable valor = solución[[I] – cambio # almacenar esta variable nueva_solución.adjuntar(valor) |
Esta nueva solución se puede evaluar usando la función objetivo () y se puede informar el rendimiento de la búsqueda.
|
... # evaluar el punto candidato solución = asarray(nueva_solución) solution_eval = objetivo(solución[[0], solución[[1]) # informe de progreso impresión(‘>% d f (% s) =% .5f’ % (eso, solución, solution_eval)) |
Y eso es.
Podemos unir todo esto en una función llamada adadelta () que toma los nombres de la función objetivo y la función derivada, una matriz con los límites del dominio y los valores del hiperparámetro para el número total de iteraciones del algoritmo y rhoy devuelve la solución final y su evaluación.
La ep El hiperparámetro también se puede tomar como argumento, aunque tiene un valor predeterminado sensible de 1e-3.
Esta función completa se enumera a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 dieciséis 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# algoritmo de descenso de gradiente con adadelta def adadelta(objetivo, derivado, límites, nitro, rho, ep=1e–3): # generar un punto inicial solución = límites[[:, 0] + rand(len(límites)) * (límites[[:, 1] – límites[[:, 0]) # lista de gradientes cuadrados promedio para cada variable sq_grad_avg = [[0.0 por _ en distancia(límites.forma[[0])] # lista de actualizaciones de parámetros promedio sq_para_avg = [[0.0 por _ en distancia(límites.forma[[0])] # ejecutar el descenso de gradiente por eso en distancia(nitro): # calcular gradiente degradado = derivado(solución[[0], solución[[1]) # actualizar el promedio de las derivadas parciales cuadradas por I en distancia(degradado.forma[[0]): # calcular el gradiente al cuadrado sg = degradado[[I]**2.0 # actualizar la media móvil del gradiente al cuadrado sq_grad_avg[[I] = (sq_grad_avg[[I] * rho) + (sg * (1.0–rho)) # construye una solución una variable a la vez nueva_solución = lista() por I en distancia(solución.forma[[0]): # calcular el tamaño del paso para esta variable alfa = (ep + sqrt(sq_para_avg[[I])) / (ep + sqrt(sq_grad_avg[[I])) # calcula el cambio cambio = alfa * degradado[[I] # actualizar la media móvil de los cambios de parámetros al cuadrado sq_para_avg[[I] = (sq_para_avg[[I] * rho) + (cambio**2.0 * (1.0–rho)) # calcular la nueva posición en esta variable valor = solución[[I] – cambio # almacenar esta variable nueva_solución.adjuntar(valor) # evaluar el punto candidato solución = asarray(nueva_solución) solution_eval = objetivo(solución[[0], solución[[1]) # informe de progreso impresión(‘>% d f (% s) =% .5f’ % (eso, solución, solution_eval)) regreso [[solución, solution_eval] |
Note: we have intentionally used lists and imperative coding style instead of vectorized operations for readability. Feel free to adapt the implementation to a vectorization implementation with NumPy arrays for better performance.
We can then define our hyperparameters and call the adadelta() function to optimize our test objective function.
In this case, we will use 120 iterations of the algorithm and a value of 0.99 for the rho hyperparameter, chosen after a little trial and error.
|
... # seed the pseudo random number generator semilla(1) # define range for input bounds = asarray([[[[–1.0, 1.0], [[–1.0, 1.0]]) # define the total iterations n_iter = 120 # momentum for adadelta rho = 0.99 # perform the gradient descent search with adadelta mejor, puntaje = adadelta(objective, derivative, bounds, n_iter, rho) impresión(‘Done!’) impresión(‘f(%s) = %f’ % (mejor, puntaje)) |
Tying all of this together, the complete example of gradient descent optimization with Adadelta is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 dieciséis 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
# gradient descent optimization with adadelta for a two-dimensional test function de math import sqrt de numpy import asarray de numpy.random import rand de numpy.random import semilla # objective function def objective(X, y): regreso x**2.0 + y**2.0 # derivative of objective function def derivative(X, y): regreso asarray([[x * 2.0, y * 2.0]) # gradient descent algorithm with adadelta def adadelta(objective, derivative, bounds, n_iter, rho, ep=1e–3): # generate an initial point solución = bounds[[:, 0] + rand(len(bounds)) * (bounds[[:, 1] – bounds[[:, 0]) # list of the average square gradients for each variable sq_grad_avg = [[0.0 por _ en range(bounds.forma[[0])] # list of the average parameter updates sq_para_avg = [[0.0 por _ en range(bounds.forma[[0])] # run the gradient descent por eso en range(n_iter): # calculate gradient gradient = derivative(solución[[0], solución[[1]) # update the average of the squared partial derivatives por i en range(gradient.forma[[0]): # calculate the squared gradient sg = gradient[[i]**2.0 # update the moving average of the squared gradient sq_grad_avg[[i] = (sq_grad_avg[[i] * rho) + (sg * (1.0–rho)) # build a solution one variable at a time new_solution = lista() por i en range(solución.forma[[0]): # calculate the step size for this variable alpha = (ep + sqrt(sq_para_avg[[i])) / (ep + sqrt(sq_grad_avg[[i])) # calculate the change cambio = alpha * gradient[[i] # update the moving average of squared parameter changes sq_para_avg[[i] = (sq_para_avg[[i] * rho) + (change**2.0 * (1.0–rho)) # calculate the new position in this variable valor = solución[[i] – cambio # store this variable new_solution.append(valor) # evaluate candidate point solución = asarray(new_solution) solution_eval = objective(solución[[0], solución[[1]) # report progress impresión(‘>%d f(%s) = %.5f’ % (eso, solución, solution_eval)) regreso [[solución, solution_eval] # seed the pseudo random number generator semilla(1) # define range for input bounds = asarray([[[[–1.0, 1.0], [[–1.0, 1.0]]) # define the total iterations n_iter = 120 # momentum for adadelta rho = 0.99 # perform the gradient descent search with adadelta mejor, puntaje = adadelta(objective, derivative, bounds, n_iter, rho) impresión(‘Done!’) impresión(‘f(%s) = %f’ % (mejor, puntaje)) |
Running the example applies the Adadelta optimization algorithm to our test problem and reports performance of the search for each iteration of the algorithm.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that a near optimal solution was found after perhaps 105 iterations of the search, with input values near 0.0 and 0.0, evaluating to 0.0.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 dieciséis 17 18 19 20 21 22 23 |
… >100 f([-1.45142626e-07 2.71163181e-03]) = 0.00001 >101 f([-1.24898699e-07 2.56875692e-03]) = 0.00001 >102 f([-1.07454197e-07 2.43328237e-03]) = 0.00001 >103 f([-9.24253035e-08 2.30483111e-03]) = 0.00001 >104 f([-7.94803792e-08 2.18304501e-03]) = 0.00000 >105 f([-6.83329263e-08 2.06758392e-03]) = 0.00000 >106 f([-5.87354975e-08 1.95812477e-03]) = 0.00000 >107 f([-5.04744185e-08 1.85436071e-03]) = 0.00000 >108 f([-4.33652179e-08 1.75600036e-03]) = 0.00000 >109 f([-3.72486699e-08 1.66276699e-03]) = 0.00000 >110 f([-3.19873691e-08 1.57439783e-03]) = 0.00000 >111 f([-2.74627662e-08 1.49064334e-03]) = 0.00000 >112 f([-2.3572602e-08 1.4112666e-03]) = 0.00000 >113 f([-2.02286891e-08 1.33604264e-03]) = 0.00000 >114 f([-1.73549914e-08 1.26475787e-03]) = 0.00000 >115 f([-1.48859650e-08 1.19720951e-03]) = 0.00000 >116 f([-1.27651224e-08 1.13320504e-03]) = 0.00000 >117 f([-1.09437923e-08 1.07256172e-03]) = 0.00000 >118 f([-9.38004754e-09 1.01510604e-03]) = 0.00000 >119 f([-8.03777865e-09 9.60673346e-04]) = 0.00000 Done! f([-8.03777865e-09 9.60673346e-04]) = 0.000001 |
Visualization of Adadelta
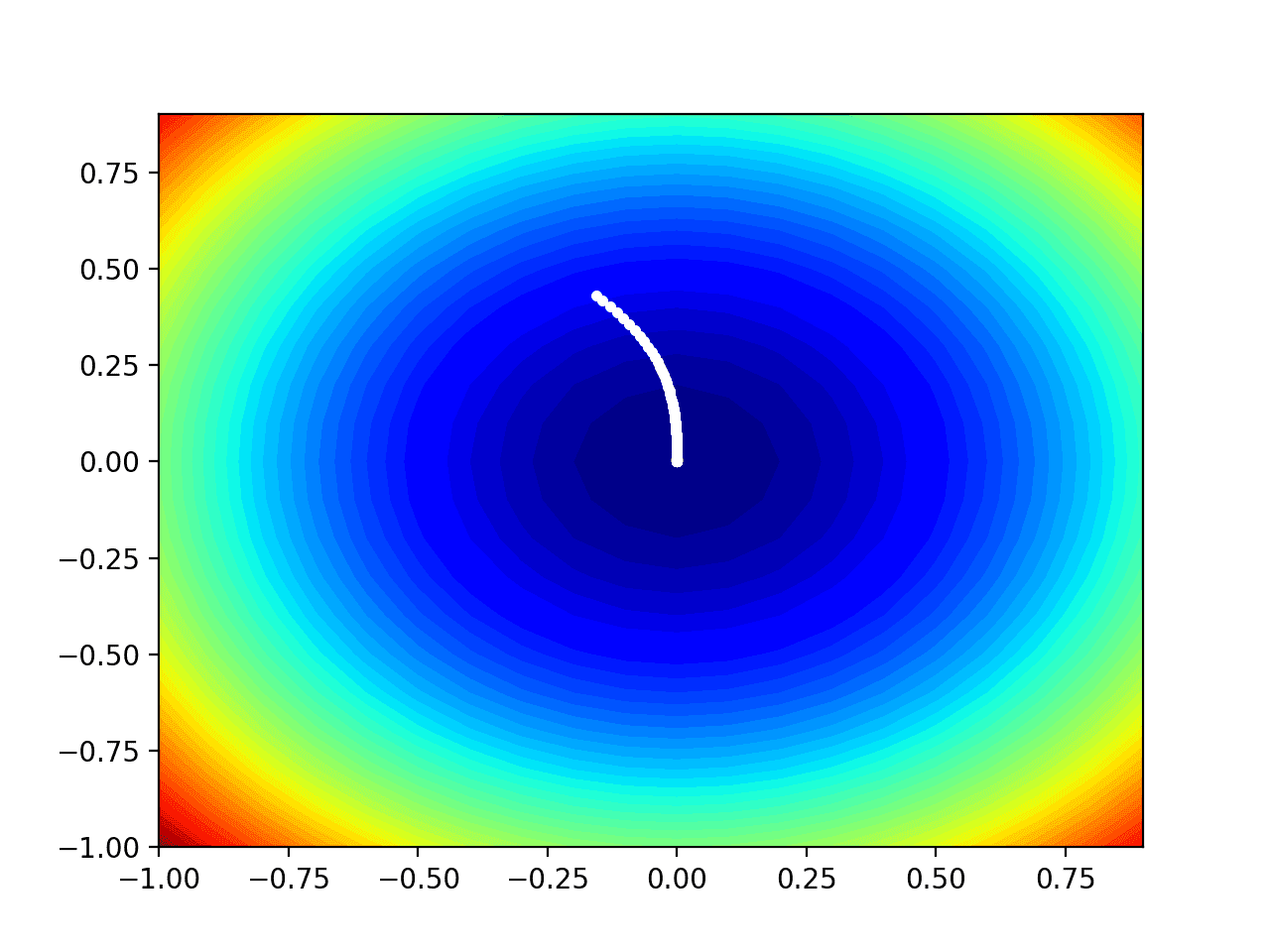
We can plot the progress of the Adadelta search on a contour plot of the domain.
This can provide an intuition for the progress of the search over the iterations of the algorithm.
We must update the adadelta() function to maintain a list of all solutions found during the search, then return this list at the end of the search.
The updated version of the function with these changes is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 dieciséis 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# gradient descent algorithm with adadelta def adadelta(objective, derivative, bounds, n_iter, rho, ep=1e–3): # track all solutions solutions = lista() # generate an initial point solución = bounds[[:, 0] + rand(len(bounds)) * (bounds[[:, 1] – bounds[[:, 0]) # list of the average square gradients for each variable sq_grad_avg = [[0.0 por _ en range(bounds.forma[[0])] # list of the average parameter updates sq_para_avg = [[0.0 por _ en range(bounds.forma[[0])] # run the gradient descent por eso en range(n_iter): # calculate gradient gradient = derivative(solución[[0], solución[[1]) # update the average of the squared partial derivatives por i en range(gradient.forma[[0]): # calculate the squared gradient sg = gradient[[i]**2.0 # update the moving average of the squared gradient sq_grad_avg[[i] = (sq_grad_avg[[i] * rho) + (sg * (1.0–rho)) # build solution new_solution = lista() por i en range(solución.forma[[0]): # calculate the step size for this variable alpha = (ep + sqrt(sq_para_avg[[i])) / (ep + sqrt(sq_grad_avg[[i])) # calculate the change cambio = alpha * gradient[[i] # update the moving average of squared parameter changes sq_para_avg[[i] = (sq_para_avg[[i] * rho) + (change**2.0 * (1.0–rho)) # calculate the new position in this variable valor = solución[[i] – cambio # store this variable new_solution.append(valor) # store the new solution solución = asarray(new_solution) solutions.append(solución) # evaluate candidate point solution_eval = objective(solución[[0], solución[[1]) # report progress impresión(‘>%d f(%s) = %.5f’ % (eso, solución, solution_eval)) regreso solutions |
We can then execute the search as before, and this time retrieve the list of solutions instead of the best final solution.
|
... # seed the pseudo random number generator semilla(1) # define range for input bounds = asarray([[[[–1.0, 1.0], [[–1.0, 1.0]]) # define the total iterations n_iter = 120 # rho for adadelta rho = 0.99 # perform the gradient descent search with adadelta solutions = adadelta(objective, derivative, bounds, n_iter, rho) |
We can then create a contour plot of the objective function, as before.
|
... # sample input range uniformly at 0.1 increments xaxis = arange(bounds[[0,0], bounds[[0,1], 0,1) yaxis = arange(bounds[[1,0], bounds[[1,1], 0,1) # create a mesh from the axis X, y = meshgrid(xaxis, yaxis) # compute targets resultados = objective(X, y) # create a filled contour plot with 50 levels and jet color scheme pyplot.contourf(X, y, resultados, levels=50, cmap=‘jet’) |
Finally, we can plot each solution found during the search as a white dot connected by a line.
|
... # plot the sample as black circles solutions = asarray(solutions) pyplot.plot(solutions[[:, 0], solutions[[:, 1], ‘.-‘, color=‘w’) |
Tying this all together, the complete example of performing the Adadelta optimization on the test problem and plotting the results on a contour plot is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 dieciséis 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 |
# example of plotting the adadelta search on a contour plot of the test function de math import sqrt de numpy import asarray de numpy import arange de numpy.random import rand de numpy.random import semilla de numpy import meshgrid de matplotlib import pyplot de mpl_toolkits.mplot3d import Axes3D # objective function def objective(X, y): regreso x**2.0 + y**2.0 # derivative of objective function def derivative(X, y): regreso asarray([[x * 2.0, y * 2.0]) # gradient descent algorithm with adadelta def adadelta(objective, derivative, bounds, n_iter, rho, ep=1e–3): # track all solutions solutions = lista() # generate an initial point solución = bounds[[:, 0] + rand(len(bounds)) * (bounds[[:, 1] – bounds[[:, 0]) # list of the average square gradients for each variable sq_grad_avg = [[0.0 por _ en range(bounds.forma[[0])] # list of the average parameter updates sq_para_avg = [[0.0 por _ en range(bounds.forma[[0])] # run the gradient descent por eso en range(n_iter): # calculate gradient gradient = derivative(solución[[0], solución[[1]) # update the average of the squared partial derivatives por i en range(gradient.forma[[0]): # calculate the squared gradient sg = gradient[[i]**2.0 # update the moving average of the squared gradient sq_grad_avg[[i] = (sq_grad_avg[[i] * rho) + (sg * (1.0–rho)) # build solution new_solution = lista() por i en range(solución.forma[[0]): # calculate the step size for this variable alpha = (ep + sqrt(sq_para_avg[[i])) / (ep + sqrt(sq_grad_avg[[i])) # calculate the change cambio = alpha * gradient[[i] # update the moving average of squared parameter changes sq_para_avg[[i] = (sq_para_avg[[i] * rho) + (change**2.0 * (1.0–rho)) # calculate the new position in this variable valor = solución[[i] – cambio # store this variable new_solution.append(valor) # store the new solution solución = asarray(new_solution) solutions.append(solución) # evaluate candidate point solution_eval = objective(solución[[0], solución[[1]) # report progress impresión(‘>%d f(%s) = %.5f’ % (eso, solución, solution_eval)) regreso solutions # seed the pseudo random number generator semilla(1) # define range for input bounds = asarray([[[[–1.0, 1.0], [[–1.0, 1.0]]) # define the total iterations n_iter = 120 # rho for adadelta rho = 0.99 # perform the gradient descent search with adadelta solutions = adadelta(objective, derivative, bounds, n_iter, rho) # sample input range uniformly at 0.1 increments xaxis = arange(bounds[[0,0], bounds[[0,1], 0,1) yaxis = arange(bounds[[1,0], bounds[[1,1], 0,1) # create a mesh from the axis X, y = meshgrid(xaxis, yaxis) # compute targets resultados = objective(X, y) # create a filled contour plot with 50 levels and jet color scheme pyplot.contourf(X, y, resultados, levels=50, cmap=‘jet’) # plot the sample as black circles solutions = asarray(solutions) pyplot.plot(solutions[[:, 0], solutions[[:, 1], ‘.-‘, color=‘w’) # show the plot pyplot.show() |
Running the example performs the search as before, except in this case, the contour plot of the objective function is created.
In this case, we can see that a white dot is shown for each solution found during the search, starting above the optima and progressively getting closer to the optima at the center of the plot.
Contour Plot of the Test Objective Function With Adadelta Search Results Shown
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Papers
Books
APIs
Articles
Summary
In this tutorial, you discovered how to develop the gradient descent with Adadelta optimization algorithm from scratch.
Specifically, you learned:
- Gradient descent is an optimization algorithm that uses the gradient of the objective function to navigate the search space.
- Gradient descent can be updated to use an automatically adaptive step size for each input variable using a decaying average of partial derivatives, called Adadelta.
- How to implement the Adadelta optimization algorithm from scratch and apply it to an objective function and evaluate the results.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.