
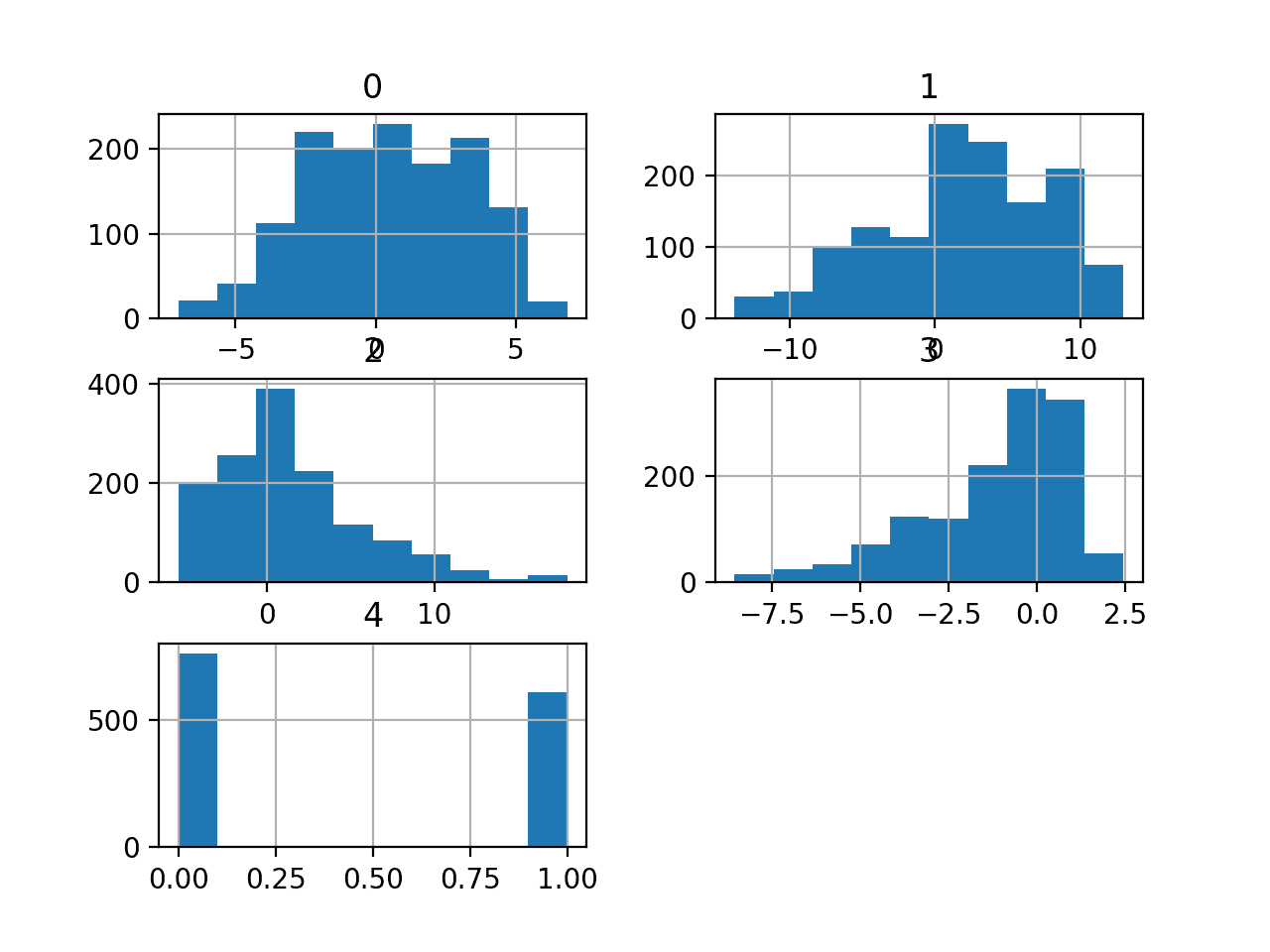
Puede resultar complicado desarrollar un modelo predictivo de red neuronal para un nuevo conjunto de datos.
Un enfoque es inspeccionar primero el conjunto de datos y desarrollar ideas sobre qué modelos podrían funcionar, luego explorar la dinámica de aprendizaje de modelos simples en el conjunto de datos y, finalmente, desarrollar y ajustar un modelo para el conjunto de datos con un arnés de prueba robusto.
Este proceso se puede utilizar para desarrollar modelos de redes neuronales eficaces para problemas de modelado predictivo de clasificación y regresión.
En este tutorial, descubrirá cómo desarrollar un modelo de red neuronal de perceptrón multicapa para el conjunto de datos de clasificación binaria de billetes.
Después de completar este tutorial, sabrá:
- Cómo cargar y resumir el conjunto de datos de billetes y usar los resultados para sugerir preparaciones de datos y configuraciones de modelos a utilizar.
- Cómo explorar la dinámica de aprendizaje de modelos MLP simples en el conjunto de datos.
- Cómo desarrollar estimaciones sólidas del rendimiento del modelo, ajustar el rendimiento del modelo y hacer predicciones sobre nuevos datos.
Empecemos.

Desarrollar una red neuronal para la autenticación de billetes
Foto de Lenny K Photography, algunos derechos reservados.
Descripción general del tutorial
Este tutorial se divide en 4 partes; son:
- Conjunto de datos de clasificación de billetes
- Dinámica de aprendizaje de redes neuronales
- Evaluación robusta del modelo
- Modelo final y hacer predicciones
Conjunto de datos de clasificación de billetes
El primer paso es definir y explorar el conjunto de datos.
Trabajaremos con el «Billete de banco”Conjunto de datos de clasificación binaria estándar.
El conjunto de datos de billetes implica predecir si un billete determinado es auténtico dadas una serie de medidas tomadas de una fotografía.
El conjunto de datos contiene 1372 filas con 5 variables numéricas. Es un problema de clasificación con dos clases (clasificación binaria).
A continuación se proporciona una lista de las cinco variables del conjunto de datos.
- varianza de la imagen transformada Wavelet (continua).
- sesgo de la imagen transformada Wavelet (continua).
- curtosis de la imagen transformada Wavelet (continua).
- entropía de la imagen (continua).
- clase (entero).
A continuación se muestra una muestra de las primeras 5 filas del conjunto de datos
|
3.6216,8.6661, -2.8073, -0.44699,0 4.5459,8.1674, -2.4586, -1.4621,0 3.866, -2.6383,1.9242,0.10645,0 3.4566,9.5228, -4.0112, -3.5944,0 0.32924, -4.4552,4.5718, -0.9888,0 4.3684,9.6718, -3.9606, -3.1625,0 … |
Puede obtener más información sobre el conjunto de datos aquí:
Podemos cargar el conjunto de datos como un DataFrame de pandas directamente desde la URL; por ejemplo:
|
# cargue el conjunto de datos de billetes y resuma la forma desde pandas importar leer_csv # definir la ubicación del conjunto de datos url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/banknote_authentication.csv’ # cargar el conjunto de datos df = read_csv(url, encabezamiento=Ninguno) # resumir forma imprimir(df.forma) |
Al ejecutar el ejemplo, se carga el conjunto de datos directamente desde la URL e informa la forma del conjunto de datos.
En este caso, podemos confirmar que el conjunto de datos tiene 5 variables (4 entradas y una salida) y que el conjunto de datos tiene 1372 filas de datos.
No se trata de muchas filas de datos para una red neuronal y sugiere que una red pequeña, quizás con regularización, sería apropiada.
También sugiere que el uso de la validación cruzada de k-fold sería una buena idea dado que dará una estimación más confiable del rendimiento del modelo que una división de tren / prueba y porque un solo modelo encajará en segundos en lugar de horas o días con el conjuntos de datos más grandes.
A continuación, podemos obtener más información sobre el conjunto de datos observando estadísticas resumidas y una gráfica de los datos.
|
# mostrar estadísticas resumidas y gráficos del conjunto de datos de billetes desde pandas importar read_csv desde matplotlib importar pyplot # definir la ubicación del conjunto de datos url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/banknote_authentication.csv’ # cargar el conjunto de datos df = read_csv(url, encabezamiento=Ninguno) # mostrar estadísticas resumidas imprimir(df.describir()) # trazar histogramas df.hist() pyplot.show() |
Ejecutar el ejemplo primero carga los datos antes y luego imprime estadísticas de resumen para cada variable.
Podemos ver que los valores varían con diferentes medias y desviaciones estándar, quizás se requiera alguna normalización o estandarización antes del modelado.
|
0 1 2 3 4 recuento 1372.000000 1372.000000 1372.000000 1372.000000 1372.000000 media 0.433735 1.922353 1.397627 -1.191657 0.444606 estándar 2,842763 5,869047 4,310030 2,101013 0,497103 min -7.042100 -13.773100 -5.286100 -8.548200 0.000000 25% -1,773000 -1,708200 -1,574975 -2,413450 0,000000 50% 0,496180 2,319650 0,616630 -0,586650 0,000000 75% 2.821475 6.814625 3.179250 0.394810 1.000000 máximo 6.824800 12.951600 17.927400 2.449500 1.000000 |
Luego se crea un gráfico de histograma para cada variable.
Podemos ver que quizás las dos primeras variables tienen una distribución similar a la de Gauss y las dos siguientes variables de entrada pueden tener una distribución gaussiana sesgada o una distribución exponencial.
Es posible que tengamos algún beneficio al usar una transformada de potencia en cada variable para hacer que la distribución de probabilidad sea menos sesgada, lo que probablemente mejorará el rendimiento del modelo.
Histogramas del conjunto de datos de clasificación de billetes
Ahora que estamos familiarizados con el conjunto de datos, exploremos cómo podríamos desarrollar un modelo de red neuronal.
Dinámica de aprendizaje de redes neuronales
Desarrollaremos un modelo de perceptrón multicapa (MLP) para el conjunto de datos utilizando TensorFlow.
No podemos saber qué modelo de arquitectura de hiperparámetros de aprendizaje sería bueno o mejor para este conjunto de datos, por lo que debemos experimentar y descubrir qué funciona bien.
Dado que el conjunto de datos es pequeño, un tamaño de lote pequeño probablemente sea una buena idea, p. Ej. 16 o 32 filas. Usar la versión de Adam del descenso de gradiente estocástico es una buena idea al comenzar, ya que adaptará automáticamente la tasa de aprendizaje y funciona bien en la mayoría de los conjuntos de datos.
Antes de evaluar los modelos en serio, es una buena idea revisar la dinámica de aprendizaje y ajustar la arquitectura del modelo y la configuración de aprendizaje hasta que tengamos una dinámica de aprendizaje estable, luego buscar sacar el máximo provecho del modelo.
Podemos hacer esto usando una división simple de tren / prueba de los datos y revisar los gráficos de las curvas de aprendizaje. Esto nos ayudará a ver si estamos aprendiendo demasiado o mal; entonces podemos adaptar la configuración en consecuencia.
Primero, debemos asegurarnos de que todas las variables de entrada sean valores de punto flotante y codificar la etiqueta de destino como valores enteros 0 y 1.
|
... # asegúrese de que todos los datos sean valores de punto flotante X = X.astipo(‘float32’) # codificar cadenas a números enteros y = LabelEncoder().fit_transform(y) |
A continuación, podemos dividir el conjunto de datos en variables de entrada y salida, luego en conjuntos de prueba y tren 67/33.
|
... # dividir en columnas de entrada y salida X, y = df.valores[[:, :–1], df.valores[[:, –1] # dividir en conjuntos de datos de prueba y de tren X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0,33) |
Podemos definir un modelo MLP mínimo. En este caso, usaremos una capa oculta con 10 nodos y una capa de salida (elegida arbitrariamente). Usaremos la función de activación de ReLU en la capa oculta y el «él_normal”Inicialización de peso, ya que juntos, son una buena práctica.
La salida del modelo es una activación sigmoidea para la clasificación binaria y minimizaremos la pérdida de entropía cruzada binaria.
|
... # determinar el número de características de entrada n_features = X.forma[[1] # definir modelo modelo = Secuencial() modelo.agregar(Denso(10, activación=‘relu’, kernel_initializer=‘él_normal’, input_shape=(n_features,))) modelo.agregar(Denso(1, activación=‘sigmoideo’)) # compilar el modelo modelo.compilar(optimizador=‘Adán’, pérdida=‘binary_crossentropy’) |
Ajustaremos el modelo para 50 épocas de entrenamiento (elegidas arbitrariamente) con un tamaño de lote de 32 porque es un conjunto de datos pequeño.
Estamos ajustando el modelo a datos sin procesar, lo que creemos que podría ser una buena idea, pero es un punto de partida importante.
|
... # encajar en el modelo historia = modelo.encajar(X_train, y_train, épocas=50, tamaño del lote=32, verboso=0, validation_data=(X_test,y_test)) |
Al final del entrenamiento, evaluaremos el desempeño del modelo en el conjunto de datos de prueba y reportaremos el desempeño como la precisión de la clasificación.
|
... # predecir el conjunto de pruebas yhat = modelo.predecir_clases(X_test) # evaluar predicciones puntaje = puntuación_de_precisión(y_test, yhat) imprimir(‘Precisión:% .3f’ % puntaje) |
Finalmente, trazaremos las curvas de aprendizaje de la pérdida de entropía cruzada en el tren y los conjuntos de prueba durante el entrenamiento.
|
... # trazar curvas de aprendizaje pyplot.título(‘Curvas de aprendizaje’) pyplot.xlabel(‘Época’) pyplot.etiqueta(‘Entropía cruzada’) pyplot.trama(historia.historia[[‘pérdida’], etiqueta=‘tren’) pyplot.trama(historia.historia[[‘val_loss’], etiqueta=‘val’) pyplot.leyenda() pyplot.show() |
Uniendo todo esto, el ejemplo completo de la evaluación de nuestro primer MLP en el conjunto de datos de billetes se enumera a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 dieciséis 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
# ajuste un modelo mlp simple en el billete y revise las curvas de aprendizaje desde pandas importar read_csv desde sklearn.model_selection importar train_test_split desde sklearn.preprocesamiento importar LabelEncoder desde sklearn.métrica importar puntuación_de_precisión desde tensorflow.keras importar Secuencial desde tensorflow.keras.capas importar Denso desde matplotlib importar pyplot # cargar el conjunto de datos camino = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/banknote_authentication.csv’ df = read_csv(camino, encabezamiento=Ninguno) # dividir en columnas de entrada y salida X, y = df.valores[[:, :–1], df.valores[[:, –1] # asegúrese de que todos los datos sean valores de punto flotante X = X.astipo(‘float32’) # codificar cadenas a números enteros y = LabelEncoder().fit_transform(y) # dividir en conjuntos de datos de prueba y de tren X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0,33) # determinar el número de características de entrada n_features = X.forma[[1] # definir modelo modelo = Secuencial() modelo.agregar(Denso(10, activación=‘relu’, kernel_initializer=‘él_normal’, input_shape=(n_features,))) modelo.agregar(Denso(1, activación=‘sigmoideo’)) # compilar el modelo modelo.compilar(optimizador=‘Adán’, pérdida=‘binary_crossentropy’) # encajar en el modelo historia = modelo.encajar(X_train, y_train, épocas=50, tamaño del lote=32, verboso=0, validation_data=(X_test,y_test)) # predecir el conjunto de pruebas yhat = modelo.predecir_clases(X_test) # evaluar predicciones puntaje = puntuación_de_precisión(y_test, yhat) imprimir(‘Precisión:% .3f’ % puntaje) # trazar curvas de aprendizaje pyplot.título(‘Curvas de aprendizaje’) pyplot.xlabel(‘Época’) pyplot.etiqueta(‘Entropía cruzada’) pyplot.trama(historia.historia[[‘pérdida’], etiqueta=‘tren’) pyplot.trama(historia.historia[[‘val_loss’], etiqueta=‘val’) pyplot.leyenda() pyplot.show() |
Ejecutar el ejemplo primero ajusta el modelo en el conjunto de datos de entrenamiento, luego informa la precisión de la clasificación en el conjunto de datos de prueba.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo varias veces y compare el resultado promedio.
En este caso, podemos ver que el modelo logró una gran o perfecta precisión del 100%. Esto podría sugerir que el problema de la predicción es fácil y / o que las redes neuronales son adecuadas para el problema.
A continuación, se crean los gráficos de línea de la pérdida en el tren y los conjuntos de prueba.
Podemos ver que el modelo parece converger bien y no muestra ningún signo de sobreajuste o desajuste.
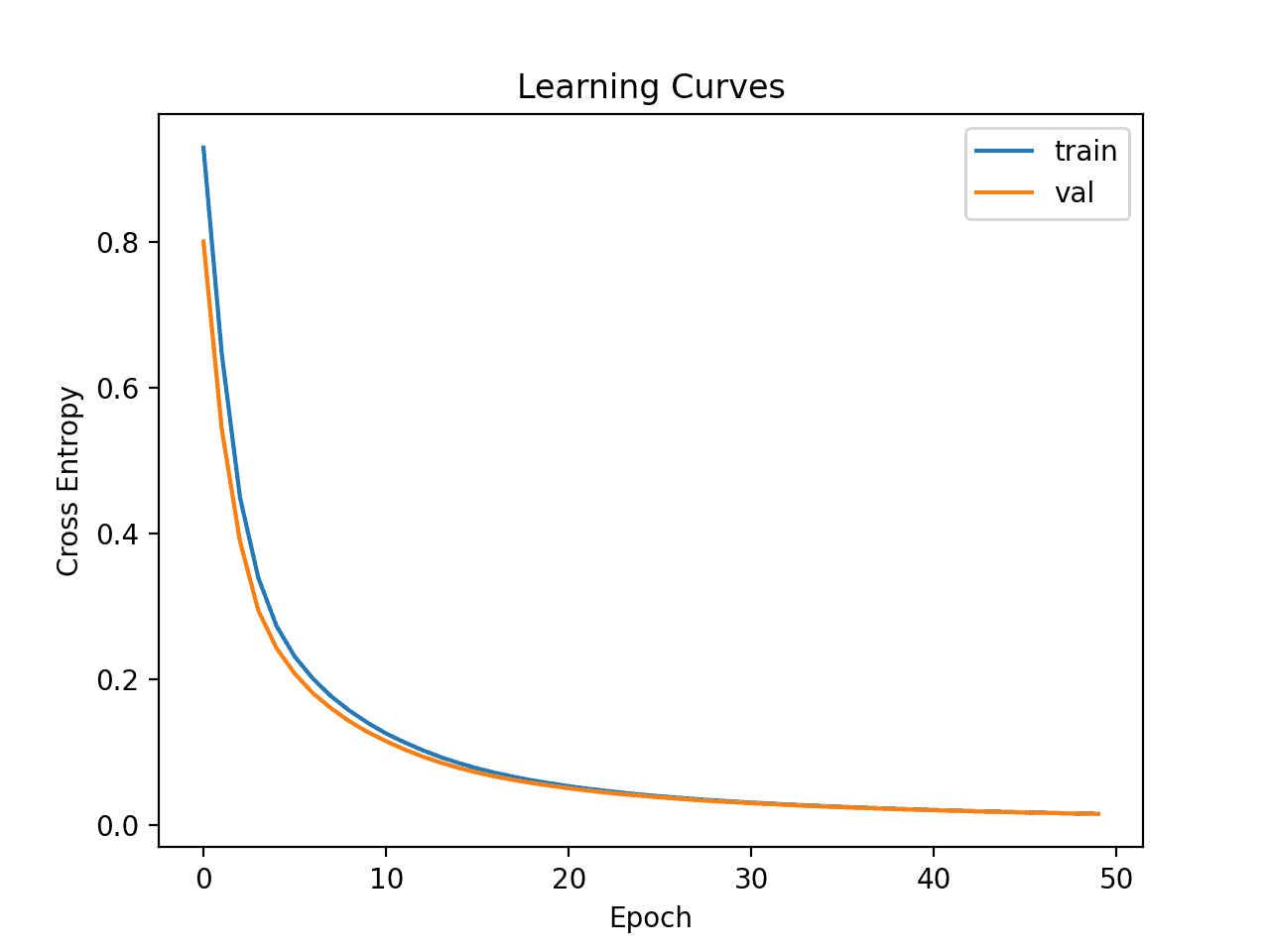
Curvas de aprendizaje del perceptrón multicapa simple en un conjunto de datos de billetes
Lo hicimos increíblemente bien en nuestro primer intento.
Ahora que tenemos una idea de la dinámica de aprendizaje para un modelo MLP simple en el conjunto de datos, podemos considerar el desarrollo de una evaluación más sólida del desempeño del modelo en el conjunto de datos.
Evaluación robusta del modelo
El procedimiento de validación cruzada de k veces puede proporcionar una estimación más confiable del rendimiento de MLP, aunque puede ser muy lento.
Esto se debe a que los modelos k deben ajustarse y evaluarse. Esto no es un problema cuando el tamaño del conjunto de datos es pequeño, como el conjunto de datos de los billetes.
Podemos usar la clase StratifiedKFold y enumerar cada pliegue manualmente, ajustar el modelo, evaluarlo y luego informar la media de las puntuaciones de evaluación al final del procedimiento.
|
... # preparar la validación cruzada kfold = KFold(10) # enumerar divisiones puntuaciones = lista() por train_ix, test_ix en kfold.separar(X, y): # ajustar y evaluar el modelo … ... ... # resumir todas las puntuaciones imprimir(‘Precisión media:% .3f (% .3f)’ % (significar(puntuaciones), std(puntuaciones))) |
Podemos usar este marco para desarrollar una estimación confiable del rendimiento del modelo MLP con nuestra configuración base, e incluso con una variedad de diferentes preparaciones de datos, arquitecturas de modelos y configuraciones de aprendizaje.
Es importante que primero desarrollemos una comprensión de la dinámica de aprendizaje del modelo en el conjunto de datos en la sección anterior antes de usar la validación cruzada de k-veces para estimar el rendimiento. Si comenzamos a ajustar el modelo directamente, podríamos obtener buenos resultados, pero si no, es posible que no tengamos idea de por qué, p. que el modelo se ajustaba demasiado o no.
Si volvemos a realizar cambios importantes en el modelo, es una buena idea volver atrás y confirmar que el modelo está convergiendo adecuadamente.
El ejemplo completo de este marco para evaluar el modelo MLP base de la sección anterior se enumera a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 dieciséis 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
# k-veces de validación cruzada del modelo base para el conjunto de datos de billetes desde numpy importar significar desde numpy importar std desde pandas importar read_csv desde sklearn.model_selection importar Estratificado KFold desde sklearn.preprocesamiento importar LabelEncoder desde sklearn.métrica importar puntuación_de_precisión desde tensorflow.keras importar Secuencial desde tensorflow.keras.capas importar Denso desde matplotlib importar pyplot # cargar el conjunto de datos camino = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/banknote_authentication.csv’ df = read_csv(camino, encabezamiento=Ninguno) # dividir en columnas de entrada y salida X, y = df.valores[[:, :–1], df.valores[[:, –1] # asegúrese de que todos los datos sean valores de punto flotante X = X.astipo(‘float32’) # codificar cadenas a números enteros y = LabelEncoder().fit_transform(y) # preparar la validación cruzada kfold = Estratificado KFold(10) # enumerar divisiones puntuaciones = lista() por train_ix, test_ix en kfold.separar(X, y): # datos divididos X_train, X_test, y_train, y_test = X[[train_ix], X[[test_ix], y[[train_ix], y[[test_ix] # determinar el número de características de entrada n_features = X.forma[[1] # definir modelo modelo = Secuencial() modelo.agregar(Denso(10, activación=‘relu’, kernel_initializer=‘él_normal’, input_shape=(n_features,))) modelo.agregar(Denso(1, activación=‘sigmoideo’)) # compilar el modelo modelo.compilar(optimizador=‘Adán’, pérdida=‘binary_crossentropy’) # encajar en el modelo modelo.encajar(X_train, y_train, épocas=50, tamaño del lote=32, verboso=0) # predecir el conjunto de pruebas yhat = modelo.predecir_clases(X_test) # evaluar predicciones puntaje = precisión_puntaje(y_test, yhat) imprimir(‘>%. 3f’ % puntaje) puntuaciones.adjuntar(puntaje) # resumir todas las puntuaciones imprimir(‘Precisión media:% .3f (% .3f)’ % (significar(puntuaciones), std(puntuaciones))) |
La ejecución del ejemplo informa el rendimiento del modelo en cada iteración del procedimiento de evaluación e informa la desviación media y estándar de la precisión de la clasificación al final de la ejecución.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo varias veces y compare el resultado promedio.
En este caso, podemos ver que el modelo MLP logró una precisión media de alrededor del 99,9 por ciento.
Esto confirma nuestra expectativa de que la configuración del modelo base funciona muy bien para este conjunto de datos y, de hecho, el modelo se ajusta bien al problema y quizás el problema sea bastante trivial de resolver.
Esto es sorprendente (para mí) porque hubiera esperado que se requiriera algo de escalado de datos y tal vez una transformación de potencia.
|
> 1.000 > 1.000 > 1.000 > 1.000 > 0,993 > 1.000 > 1.000 > 1.000 > 1.000 > 1.000 Precisión media: 0,999 (0,002) |
A continuación, veamos cómo podríamos ajustar un modelo final y usarlo para hacer predicciones.
Modelo final y hacer predicciones
Una vez que elegimos una configuración de modelo, podemos entrenar un modelo final con todos los datos disponibles y usarlo para hacer predicciones sobre nuevos datos.
En este caso, usaremos el modelo con abandono y un tamaño de lote pequeño como nuestro modelo final.
Podemos preparar los datos y ajustar el modelo como antes, aunque en todo el conjunto de datos en lugar de en un subconjunto de entrenamiento del conjunto de datos.
|
... # dividir en columnas de entrada y salida X, y = df.valores[[:, :–1], df.valores[[:, –1] # ensure all data are floating point values X = X.astype(‘float32’) # encode strings to integer le = LabelEncoder() y = le.fit_transform(y) # determine the number of input features n_features = X.forma[[1] # define model model = Sequential() model.add(Dense(10, activation=‘relu’, kernel_initializer=‘he_normal’, input_shape=(n_features,))) model.add(Dense(1, activation=‘sigmoid’)) # compile the model model.compile(optimizer=‘adam’, loss=‘binary_crossentropy’) |
We can then use this model to make predictions on new data.
First, we can define a row of new data.
|
... # define a row of new data row = [[3.6216,8.6661,–2.8073,–0.44699] |
Note: I took this row from the first row of the dataset and the expected label is a ‘0’.
We can then make a prediction.
|
... # make prediction yhat = model.predict_classes([[row]) |
Then invert the transform on the prediction, so we can use or interpret the result in the correct label (which is just an integer for this dataset).
|
... # invert transform to get label for class yhat = le.inverse_transform(yhat) |
And in this case, we will simply report the prediction.
|
... # report prediction print(‘Predicted: %s’ % (yhat[[0])) |
Tying this all together, the complete example of fitting a final model for the banknote dataset and using it to make a prediction on new data is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 dieciséis 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# fit a final model and make predictions on new data for the banknote dataset desde pandas import read_csv desde sklearn.preprocessing import LabelEncoder desde sklearn.metrics import accuracy_score desde tensorflow.keras import Sequential desde tensorflow.keras.layers import Dense desde tensorflow.keras.layers import Dropout # load the dataset camino = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/banknote_authentication.csv’ df = read_csv(camino, header=Ninguno) # split into input and output columns X, y = df.values[[:, :–1], df.values[[:, –1] # ensure all data are floating point values X = X.astype(‘float32’) # encode strings to integer le = LabelEncoder() y = le.fit_transform(y) # determine the number of input features n_features = X.forma[[1] # define model model = Sequential() model.add(Dense(10, activation=‘relu’, kernel_initializer=‘he_normal’, input_shape=(n_features,))) model.add(Dense(1, activation=‘sigmoid’)) # compile the model model.compile(optimizer=‘adam’, loss=‘binary_crossentropy’) # fit the model model.fit(X, y, epochs=50, batch_size=32, verbose=0) # define a row of new data row = [[3.6216,8.6661,–2.8073,–0.44699] # make prediction yhat = model.predict_classes([[row]) # invert transform to get label for class yhat = le.inverse_transform(yhat) # report prediction print(‘Predicted: %s’ % (yhat[[0])) |
Running the example fits the model on the entire dataset and makes a prediction for a single row of new data.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that the model predicted a “0” label for the input row.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Tutorials
Resumen
In this tutorial, you discovered how to develop a Multilayer Perceptron neural network model for the banknote binary classification dataset.
Specifically, you learned:
- How to load and summarize the banknote dataset and use the results to suggest data preparations and model configurations to use.
- How to explore the learning dynamics of simple MLP models on the dataset.
- How to develop robust estimates of model performance, tune model performance and make predictions on new data.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Develop Deep Learning Projects with Python!

What If You Could Develop A Network in Minutes
…with just a few lines of Python
Discover how in my new Ebook:
Deep Learning With Python
It covers end-to-end projects on topics like:
Multilayer Perceptrons, Convolutional Nets y Recurrent Neural Nets, and more…
Finally Bring Deep Learning To
Your Own Projects
Skip the Academics. Just Results.
See What’s Inside