
El NiFi es un marco de flujo de datos de código abierto. Está altamente automatizado para el flujo de datos entre sistemas. Funciona como un transportador de datos entre el productor y el consumidor de datos. Productor significa el sistema que genera datos y consumidor significa el otro sistema que consume datos. El NiFi garantiza la solución de la alta complejidad, la escalabilidad, la capacidad de mantenimiento y otros grandes desafíos de un gran flujo de datos.
El NiFi se utiliza ampliamente en la energía y los servicios públicos, los servicios financieros, las telecomunicaciones, la atención de la salud y las ciencias de la vida, la cadena de suministro al por menor, la fabricación y muchos otros.
Las fuentes comúnmente utilizadas son los repositorios de datos, archivos planos, XML, JSON, ubicación SFTP, servidores web, HDFS y muchos otros.
Los destinos pueden ser S3, NAS, HDFS, SFTP, Servidores Web, RDBMS, Kafka etc.,
¿Por qué el NiFi?
Los usos principales del NiFi incluyen la ingestión de datos. En cualquier proyecto de Big Data, el mayor desafío es traer diferentes tipos de datos de diferentes fuentes a un lago de datos centralizado. El NiFi es capaz de ingerir cualquier tipo de datos de cualquier fuente a cualquier destino. El NiFi viene con más de 280 procesadores incorporados que son lo suficientemente capaces de transportar datos entre sistemas.
El NiFi es una herramienta fácil de usar que prefiere la configuración a la codificación.
Sin embargo, el NiFi no se limita a la ingestión de datos solamente. El NiFi también puede realizar la procedencia de los datos, la limpieza de los datos, la evolución de los esquemas, la agregación de datos, la transformación, la programación de trabajos y muchos otros. Discutiremos esto con más detalle en algún otro blog muy pronto con una tubería de flujo de datos del mundo real.
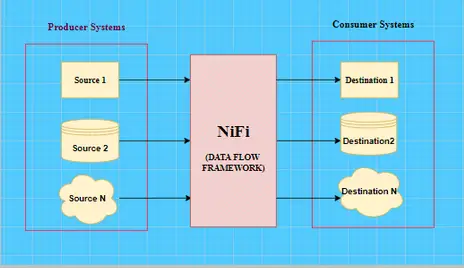
Por lo tanto, podemos decir que el NiFi es un marco altamente automatizado que se utiliza para reunir, transportar, mantener y agregar datos de diversos tipos desde diversas fuentes hasta su destino en un conducto de flujo de datos.
Una muestra de tubería de flujo de datos de NiFi se vería como algo abajo
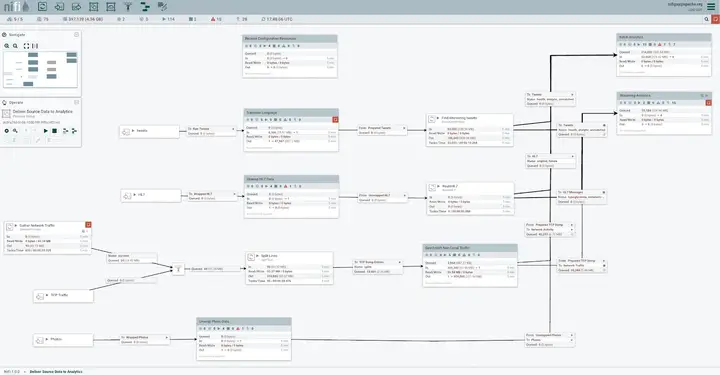
Parece demasiado complejo, ¿verdad? Esta es la belleza del NiFi: podemos construir complejas tuberías con la ayuda de alguna configuración básica. Por lo tanto, recuerde siempre que el NiFi asegura configuración sobre la codificación.
Instrucciones paso a paso para construir una tubería de datos en NiFi
Antes de seguir adelante con los componentes del NiFi. Como desarrollador, para crear un pipeline de NiFi necesitamos configurar o construir ciertos procesadores y agruparlos en un grupo de procesadores y conectar cada uno de estos grupos para crear un pipeline de NiFi.
Entendamos estos componentes usando una tubería en tiempo real.
Supongamos que tenemos algunos archivos planos entrantes en el directorio de origen. Ahora, diseñaré y configuraré una tubería para comprobar estos archivos y entender su nombre, tipo y otras propiedades. Este procedimiento se conoce como listado. Después de listar los archivos los ingeriremos en un directorio de destino.
Crearemos un grupo de procesadores «List – Fetch» seleccionando y arrastrando el icono del grupo de procesadores de la barra de herramientas superior derecha y dándole un nombre.
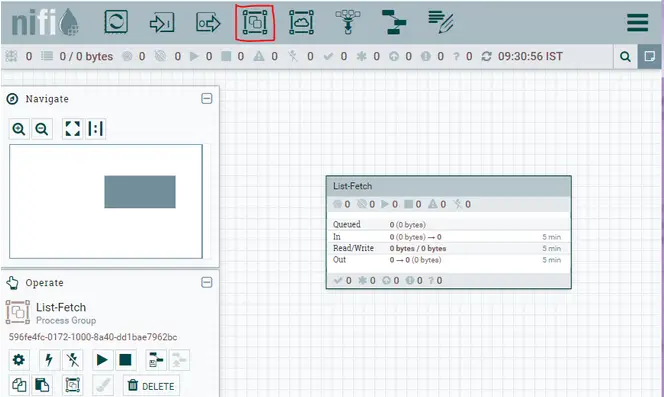
Ahora, haga doble clic en el grupo de procesadores para entrar en la «Lista de búsqueda» y arrastre el icono del procesador para crear un procesador. Se abrirá una ventana emergente, busque el procesador requerido y añádalo.
El procesador se añade pero con alguna advertencia ⚠ ya que no está configurado. Haga clic en el botón derecho e ir a configurar. Aquí, podemos agregar/actualizar la programación, configuración, propiedades y cualquier comentario para el procesador. A partir de ahora, actualizaremos la ruta de origen de nuestro procesador en la pestaña de propiedades. Cada uno de los campos marcados en audaz son obligatorios y cada campo tiene un signo de interrogación al lado, lo que explica su uso.
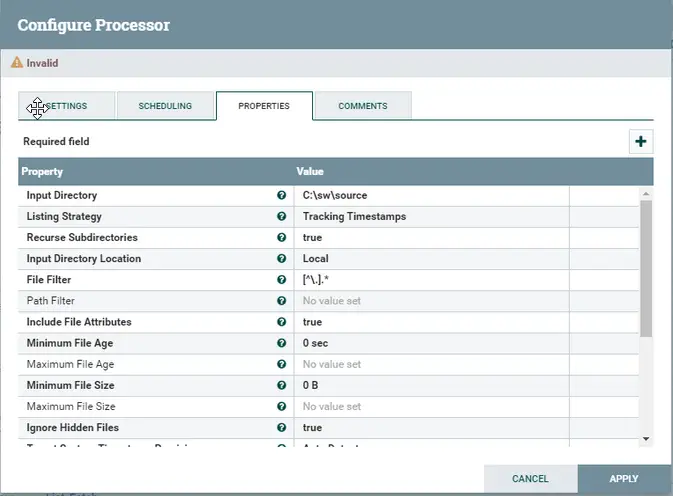
De manera similar, agregue otro procesador «FetchFile». Mueve el cursor en el procesador «ListFile» y arrastra la flecha de «ListFile» a «FetchFile». Esto te dará un pop up que te informará que la relación de ListFile a FetchFile está en la ejecución exitosa de ListFile. Una vez que se establece la conexión. Las advertencias de ListFile se resolverán ahora y List File está listo para su ejecución. Esto puede ser confirmado por un grueso cuadro rojo en el procesador.
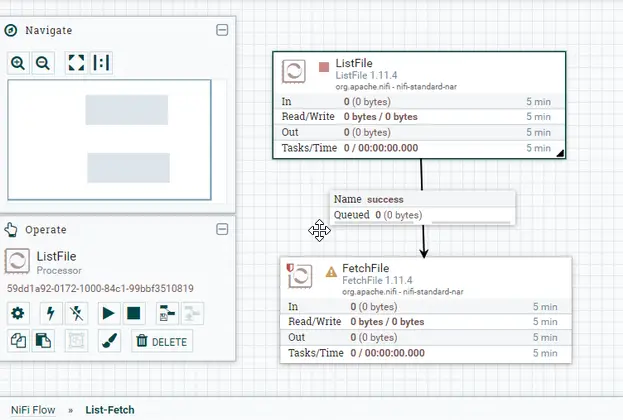
Del mismo modo, abre FetchFile para configurar. En la configuración, seleccione las cuatro opciones de «Terminación automática de relaciones». Esto asegura que el oleoducto saldrá una vez que se encuentre cualquiera de estas relaciones.
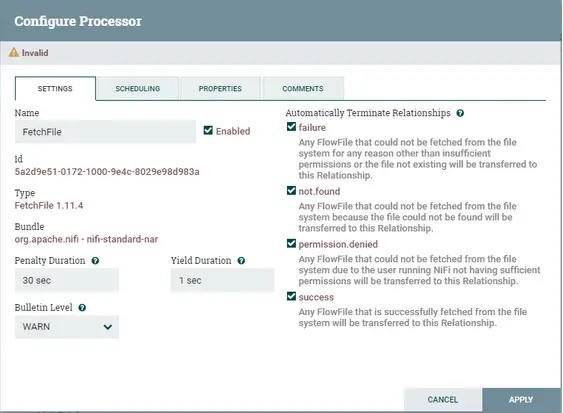
A continuación, en la pestaña de Propiedades deje Archivo a buscar porque está acoplado en una relación de éxito con ListFile. Cambiar la estrategia de finalización a Mover archivo e introducir el directorio de destino en consecuencia. Elija las otras opciones según el caso de uso. Aplicar y cerrar.
El oleoducto está listo con las advertencias. Vamos a ejecutarlo.
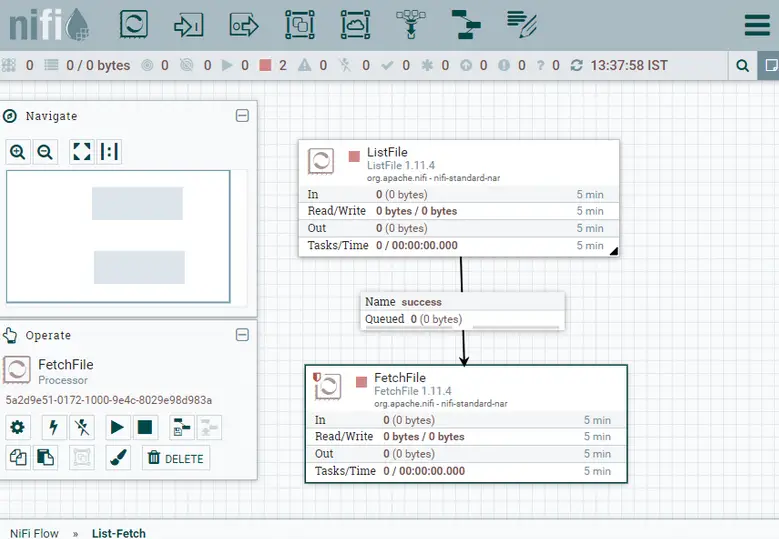
Si queremos ejecutar un solo procesador, sólo hay que hacer clic con el botón derecho del ratón y empezar. Para completar la tubería en un grupo de procesadores. Ir al grupo de procesadores haciendo clic en el nombre del grupo de procesadores en la barra de navegación inferior izquierda. Luego, haz clic con el botón derecho del ratón y comienza.
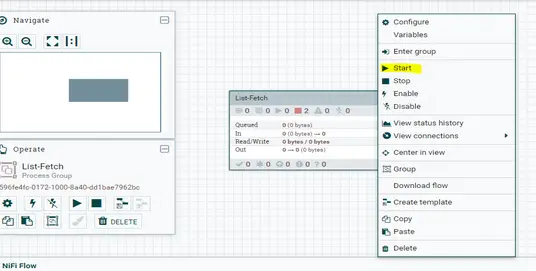
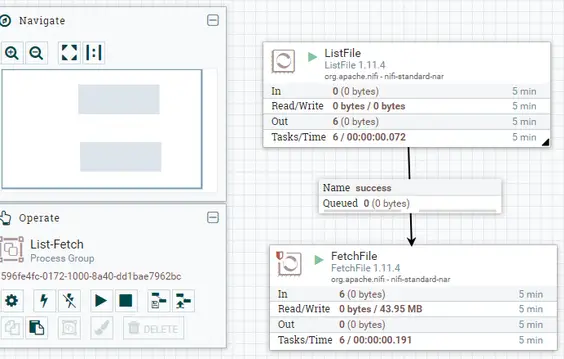
El botón verde indica que el oleoducto está en estado de funcionamiento y el rojo para detenido. Aquí, archivo movido de un procesador a otro a través de una cola. Si uno de los procesadores se completa y el sucesor se atasca/para/falla, los datos procesados se atascarán en la cola. Se puede acceder a otros detalles sobre el historial de ejecución, resumen, procedencia de los datos, historial de configuración del flujo, etc., haciendo clic con el botón derecho del ratón en el grupo de procesadores/procesadores o haciendo clic en el botón de las tres líneas horizontales de la parte superior derecha.
Este es un ejemplo del mundo real de la construcción y el despliegue de un gasoducto de NiFi.
Componentes de NiFi
Internamente, la tubería de NiFi consta de los siguientes componentes.
FlowFile
FlowFile representa la abstracción real que proporciona el NiFi, es decir, los datos estructurados o no estructurados que se procesan. Datos estructurados como el JSON o el mensaje XML y datos no estructurados como imágenes, videos, audios. FlowFile contiene dos partes – contenido y atributo.
El contenido mantiene la información real del flujo de datos que puede ser leída usando GetFile, GetHTTP etc. mientras que el atributo está en la forma de par llave-valor y contiene toda la información básica sobre el contenido.
Procesador
El procesador actúa como un bloque de construcción del flujo de datos del NiFi. Realiza varias tareas como crear archivos de flujo, leer los contenidos de los archivos de flujo, escribir los contenidos de los archivos de flujo, encaminar los datos, extraer los datos, modificar los datos y muchas más. A día de hoy tenemos más de 280 procesadores integrados en NiFi. Recuerde que también podemos construir procesadores personalizados en NiFi según nuestros requerimientos.
Tarea de informe
La tarea de presentación de informes es capaz de analizar y supervisar la información interna del NiFi y luego envía esta información a los recursos externos.
Grupo de Procesadores
Es un conjunto de varios procesadores y sus conexiones que pueden ser conectados a través de sus puertos.
Cola
Cola, como el nombre sugiere, contiene datos procesados de un procesador después de ser procesados.
Priorizador de archivos de flujo
Da la posibilidad de priorizar los datos, lo que significa que los datos que se necesitan urgentemente son enviados primero por el usuario y los datos restantes están en la cola.
Controlador de flujo
El Controlador de Flujo actúa como el cerebro de las operaciones. Mantiene el seguimiento del flujo de datos, lo que significa la inicialización del flujo, la creación de componentes en el flujo, la coordinación entre los componentes. Es responsable de la gestión de los hilos y las asignaciones que todos los procesos utilizan. El controlador de flujo tiene dos componentes principales: Procesadores y Extensiones.
Arquitectura NiFi
Considere un host/sistema operativo (su pc), Instale Java encima para iniciar un entorno de ejecución de Java (JVM). Considere un servidor web (como localhost en el caso de una PC local), este servidor web trabajaría principalmente para alojar comandos basados en HTTP o API de control.
Ahora vamos a añadir un motor operativo central a este marco llamado controlador de flujo. Actúa como el cerebro de la operación. Los procesadores y las extensiones son sus componentes principales. El punto importante a considerar aquí es que las extensiones operan y se ejecutan dentro de la JVM (como se explicó anteriormente).
Son los Controladores de Flujo los que proporcionan hilos para que las Extensiones se ejecuten y gestionan el calendario de cuándo las Extensiones reciben recursos para ejecutarse.
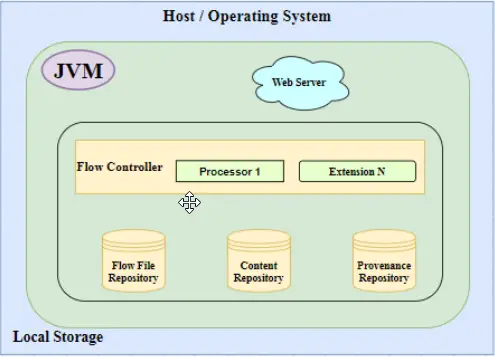
Por último, pero no menos importante, agreguemos tres repositorios: el Repositorio de Archivos de Flujo, el Repositorio de Contenido y el Repositorio de Procedencia.
Depósito de archivos de flujo
El repositorio de FlowFile es un repositorio enchufable que lleva un registro del estado de FlowFile activo.
Repositorio de contenidos
El Repositorio de Contenido es un repositorio enchufable que almacena el contenido real de un determinado Archivo de Flujo. Almacena datos con un mecanismo simple de almacenamiento de contenido en un Sistema de Archivos. También se puede especificar más de uno para reducir la contención en un solo volumen.
Depósito de procedencia
Provenance Repository es también un repositorio enchufable. Almacena los datos de procedencia de un Archivo de Flujo de manera indexada y con capacidad de búsqueda. Los datos de procedencia se refieren a los detalles del proceso y la metodología por la que se produjo el contenido del Archivo de Flujo. Actúa como un linaje para el oleoducto.
Este es el diseño y la arquitectura general del NiFi. Por favor, consulte el siguiente diagrama para una mejor comprensión y referencia.
El NiFi también funciona en clusters que utilizan el servidor Zookeeper.
Instalación de Apache NiFi en su PC
Ahora, ya que hemos adquirido algunos conceptos teóricos básicos sobre el NiFi, por qué no empezar con algo de práctica. Para hacerlo, necesitamos tener instalado el NiFi.
Por favor, proceda conmigo y complete los siguientes pasos independientemente de su sistema operativo:
Descargar
Ccrear un directorio de su elección.
Abre un navegador y navega a la url https://nifi.apache.org/download.html
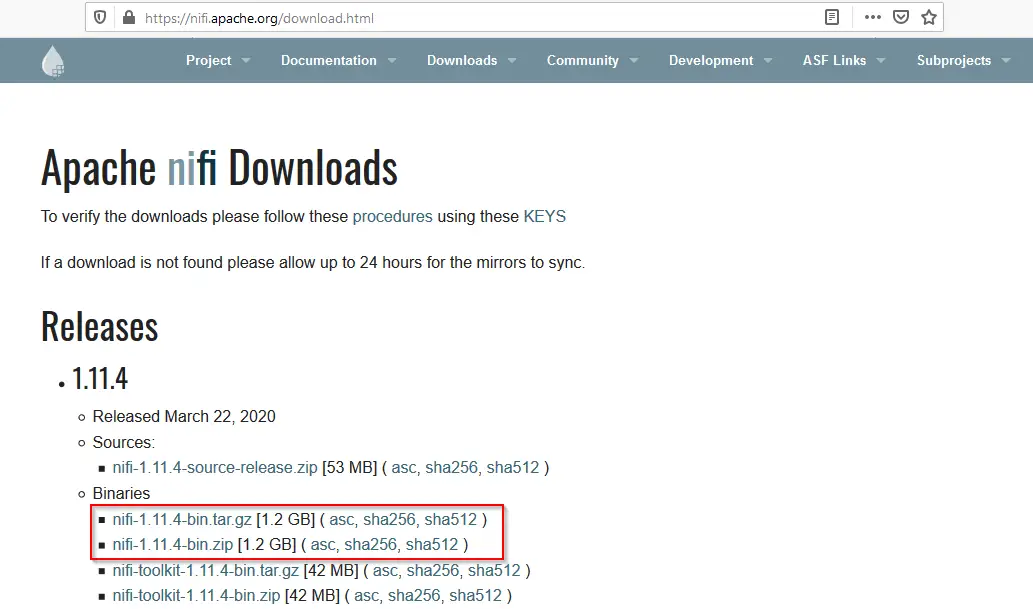
En el momento de escribir este artículo teníamos 1.11.4 como la última versión estable. Basado en la última versión, vaya a la sección «Binarios».
Somos libres de elegir cualquiera de los archivos disponibles, sin embargo, yo recomendaría «.tar.gz» para MAC/Linux y «.zip» para las ventanas.
Instalar
Mientras la descarga continúa, por favor asegúrate de tener java instalado en tu PC y el JDK asignado a la ruta JAVA_HOME.
Por favor, no pase al siguiente paso si no se instala o no se añade Java a la ruta JAVA_HOME en la variable de entorno.
Una vez descargado el archivo mencionado en el paso 2, extráigalo o descomprímalo en el directorio creado en el paso 1.
Abra el directorio extraído y veremos los siguientes archivos y directorios
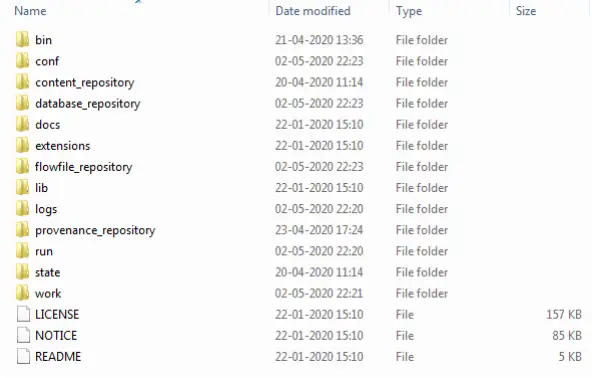
Abre el directorio de la papelera de arriba. Aparece la siguiente estructura.
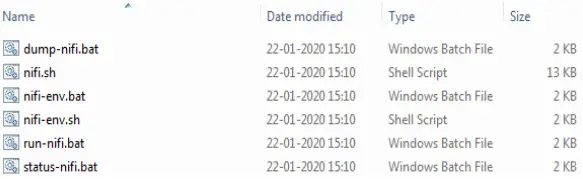
Aquí, podemos ver los ejecutables basados en el sistema operativo. Así que nuestros próximos pasos serán según nuestro sistema operativo:
Para el sistema operativo MAC/Linux abra un terminal y ejecute
bin/nifi.sh se ejecutan desde el directorio de instalación o
bin/nifi.sh empezar a ejecutarlo en segundo plano.
Para instalar el NiFi como un servicio (sólo para mac/linux) ejecute
bin/nifi.sh instalar desde el directorio de instalación. Esto instalará el nombre de servicio por defecto como nifi. Para el nombre de servicio personalizado agregue otro parámetro a este comando
bin/nifi.sh instalar dataflow
Para las ventanas abre el cmd y navega al directorio bin por ejemplo:
cd c:swnifi–1.11.4–binnifi–1.11.4bin
Entonces escribe… run-nifi.bat y presiona enter
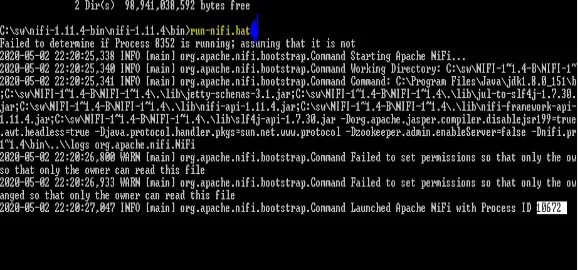
Ve al directorio de registros y abre nifi-app.log Desplácese hacia abajo hasta el final de la página.
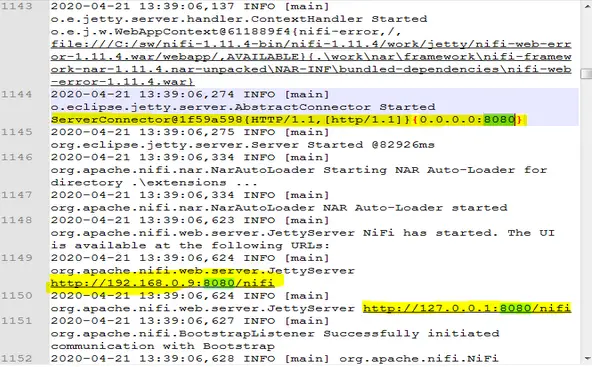
Aquí, en el registro, echemos un vistazo a la siguiente entrada:
|
ServerConnector@1f59a598{HTTP/1.1,[[http/1.1]}{0.0.0.0:8080} |
Verifique
Por defecto, el NiFi está alojado en el puerto 8080 del localhost. Abrir el navegador y abrir la url del localhost en el puerto 8080 http://localhost:8080/nifi/
Tenemos abierta nuestra página web de NiFi.
Esta página confirma que nuestro NiFi está en funcionamiento.