
En la última década, uno de los mayores impulsores del éxito en el aprendizaje de las máquinas ha sido, sin duda, el surgimiento de modelos de gran capacidad como las redes neuronales junto con grandes conjuntos de datos como ImageNet para producir modelos precisos. Si bien hemos visto cómo las redes neuronales profundas se han aplicado con éxito en el aprendizaje de refuerzo (RL) en dominios como la robótica, el póquer, los juegos de mesa y los videojuegos en equipo, una barrera significativa para que estos métodos funcionen en problemas del mundo real es la dificultad de la recopilación de datos en línea a gran escala. La recopilación de datos en línea no sólo es lenta y costosa, sino que también puede ser peligrosa en dominios críticos para la seguridad, como la conducción o la atención sanitaria. Por ejemplo, no sería razonable permitir que los agentes de aprendizaje de refuerzo exploren, cometan errores y aprendan mientras controlan un vehículo autónomo o tratan a pacientes en un hospital. Esto hace que el aprendizaje de la experiencia precolectada sea tentador, y somos afortunados en que muchos de estos dominios, ya existen grandes conjuntos de datos para aplicaciones como la conducción autónoma de coches, la atención sanitaria, o la robótica. Por lo tanto, la capacidad de los algoritmos de RL para aprender fuera de línea a partir de estos conjuntos de datos (un entorno denominado offline o RL por lotes) tiene un enorme impacto potencial en la configuración de la forma en que construimos los sistemas de aprendizaje de las máquinas para el futuro.
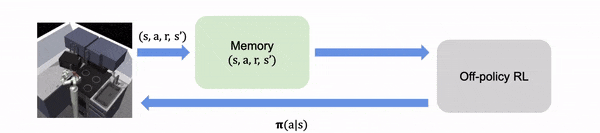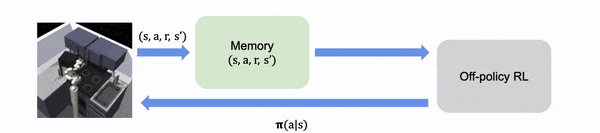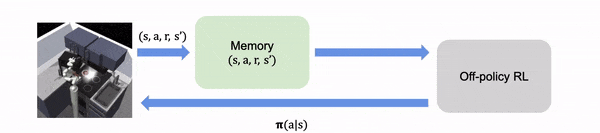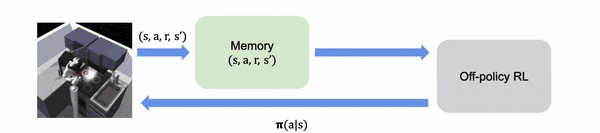
En la RL fuera de la política, el algoritmo aprende de la experiencia recogida en línea de un
la política de exploración o de comportamiento.
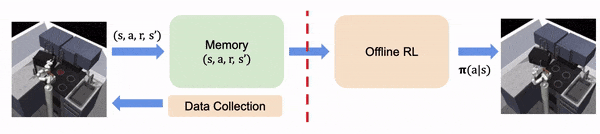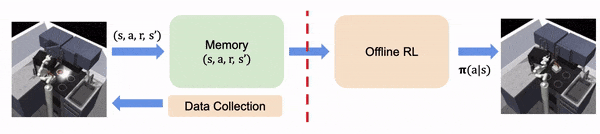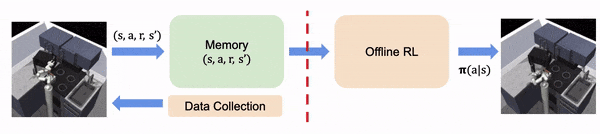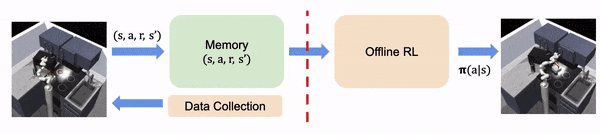
En la RL fuera de línea, asumimos que toda la experiencia se recoge fuera de línea, fija y no
se pueden reunir datos adicionales.
El método predominante para la evaluación comparativa de la LR profunda fuera de línea se ha limitado a un solo escenario: el conjunto de datos se genera a partir de alguna política aleatoria o previamente entrenada, y el objetivo del algoritmo es mejorar el rendimiento con respecto a la política original [i.e., 1,2,3,4,5,6]. El problema de este enfoque es que es improbable que los conjuntos de datos del mundo real se generen por una sola política capacitada de RL, y las muchas situaciones no cubiertas por este método de evaluación son desafortunadamente conocidas por ser problemáticas para los algoritmos de RL. Esto hace difícil saber qué tan bien se desempeñarán nuestros algoritmos cuando se utilicen realmente fuera de estas tareas de referencia.
A fin de desarrollar algoritmos eficaces para la LR fuera de línea, necesitamos puntos de referencia ampliamente disponibles que sean fáciles de usar y que puedan medir con precisión el progreso de este problema. El uso de datos del mundo real, como en la conducción autónoma, sería un gran indicador de progreso, pero la evaluación del algoritmo se convierte en un desafío. La mayoría de los laboratorios de investigación no tienen los recursos para desplegar su algoritmo en un vehículo real con el fin de probar si su método realmente funciona. Para llenar el vacío entre las tareas realistas pero inviables en el mundo real, y las tareas simuladas algo ausentes pero fáciles de usar, recientemente introdujimos el punto de referencia D4RL (Datasets for Deep Data-Driven Reinforcement Learning) para RL fuera de línea. El objetivo de D4RL es simple: proponemos tareas diseñadas para ejercitar las dimensiones del problema de RL fuera de línea que pueden dificultar la aplicación en el mundo real, mientras se mantiene todo el benchmark en dominios simulados que permiten a cualquier investigador del mundo evaluar eficientemente su método. En total, el punto de referencia de D4RL incluye más de 40 tareas a través de 7 dominios cualitativamente distintos que cubren áreas de aplicación como la manipulación robótica, la navegación y la conducción autónoma.
¿Qué propiedades hacen difícil la RL fuera de línea?
En una entrada anterior del blog, discutimos que simplemente ejecutar un algoritmo RL ordinario fuera de la política en el problema fuera de línea es típicamente insuficiente, y en el peor de los casos puede causar que el algoritmo difiera. De hecho, hay muchos factores que pueden causar un mal rendimiento de los algoritmos RL, que usamos para guiar el diseño de D4RL.
Distribuciones de datos estrechas y sesgadas son una propiedad común en los conjuntos de datos del mundo real que pueden crear problemas para los algoritmos de RL fuera de línea. Por distribuciones de datos estrechas, queremos decir que el conjunto de datos carece de una cobertura significativa en el espacio de acción de estado del problema. Una distribución de datos estrecha no significa por sí misma que la tarea sea irresoluble – por ejemplo, las demostraciones de los expertos a menudo producen distribuciones estrechas que pueden dificultar el aprendizaje. Una razón intuitiva de por qué es difícil aprender de las distribuciones estrechas de datos es que a menudo carecen de los errores necesarios para que un algoritmo aprenda. Por ejemplo, en la atención sanitaria, los conjuntos de datos suelen estar sesgados hacia los casos graves. Es posible que sólo veamos a pacientes muy enfermos ser tratados con medicamentos (con un pequeño porcentaje de ellos viviendo), y a pacientes levemente enfermos ser enviados a casa sin tratamiento (con casi todos ellos viviendo). Un algoritmo ingenuo podría aprender que el tratamiento causa la muerte, pero esto se debe simplemente a que nunca vemos pacientes enfermos sin tratamiento, sobre lo cual aprenderíamos que la tasa de supervivencia para el tratamiento es mucho más alta.
Datos generados a partir de políticas no representativas pueden surgir de varias situaciones reales. Por ejemplo, los demostradores humanos pueden utilizar pistas no observables para un agente de RL, lo que conduce a problemas de observabilidad parcial. Algunos controladores pueden utilizar el estado o la memoria para crear datos que no pueden ser representados por ninguna política markoviana. Estas situaciones pueden causar varios problemas para los algoritmos de RL fuera de línea. En primer lugar, se ha demostrado que el hecho de no poder representar la clase de política crea un sesgo en el algoritmo Q-learning. En segundo lugar, un paso crucial en muchos algoritmos de RL fuera de línea, como los basados en la ponderación de la importancia, es estimar las probabilidades de acción en el conjunto de datos. El hecho de no poder representar la política que generó los datos puede crear una fuente de error adicional.
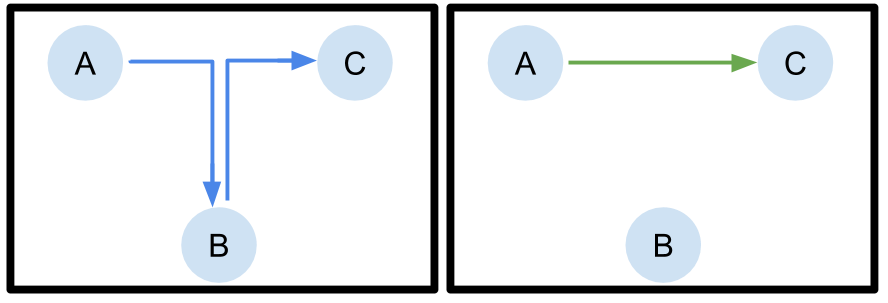
Datos multitarea y no dirigidos es una propiedad que creemos que prevalecerá entre los grandes conjuntos de datos baratos. Imagine que usted fuera un practicante de RL y deseara adquirir un gran conjunto de datos para entrenar agentes de diálogo y asistentes personales. El método más simple para hacerlo sería simplemente registrar las conversaciones entre humanos reales, o raspar las conversaciones reales de Internet. En estas situaciones, las conversaciones grabadas pueden no tener nada que ver con una tarea particular que se esté tratando de realizar, como reservar un vuelo. Sin embargo, muchas piezas del flujo de la conversación podrían ser útiles y aplicables a algo más que la conversación en la que se observó. Una forma de visualizar este efecto es con el siguiente ejemplo. Imagina si un agente estuviera tratando de ir del punto A al C, pero sólo observa los caminos de A a B y de B a C. Un agente puede «coser» las mitades correspondientes de los caminos observados para formar el camino más corto de A a C.
Datos subóptimos es otra propiedad que esperamos observar en conjuntos de datos realistas porque no siempre es factible tener demostraciones de expertos para cada tarea que queramos resolver. En muchos dominios, como en la robótica, proporcionar demostraciones de expertos es tedioso y consume mucho tiempo. Una ventaja clave de utilizar RL en lugar de un método como el aprendizaje por imitación es que RL nos da una clara señal de cómo mejorar una política, lo que significa que podemos aprender y mejorar desde un ámbito mucho más amplio de conjuntos de datos.
Tareas del D4RL
Para capturar las propiedades que hemos descrito anteriormente, introducimos tareas que abarcan una amplia variedad de dominios cualitativamente diferentes. Todos los dominios, aparte de Maze2D y AntMaze, fueron propuestos originalmente por otros investigadores de ML, y hemos adaptado su trabajo y generado conjuntos de datos para su uso en el entorno de RL fuera de línea.

Para una tarea de navegación realista basada en la visión, usamos el simulador CARLA. Esta tarea agrega una capa de desafío perceptivo sobre las dos tareas mencionadas de Maze2D y AntMaze.

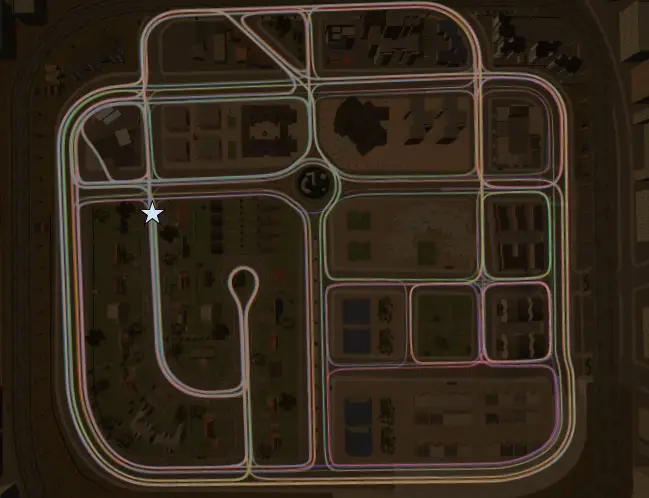
- También incluimos 2 tareas realistas de manipulación robótica, usando el Adroit (basado en el robot Mano de Sombra) y las plataformas Franka. El dominio Adroit contiene 4 tareas de manipulación separadas, así como demostraciones humanas grabadas mediante captura de movimiento. Esto proporciona una plataforma para estudiar el uso de datos generados por humanos dentro de una plataforma robótica simulada.




El entorno de la cocina Franka coloca a un robot en un entorno de cocina realista donde se puede interactuar libremente con los objetos. Estos incluyen abrir el microondas y varios armarios, mover la tetera, y encender las luces y los quemadores. La tarea es alcanzar una configuración de objetivos deseada de los objetos de la escena.



- Incluimos dos tareas del benchmark Flow (que ha sido cubierto en una entrada anterior del blog). El proyecto Flow propone utilizar vehículos autónomos para reducir la congestión del tráfico, lo que creemos que es un caso de uso convincente para la LR fuera de línea. Incluimos un diseño de anillo y un diseño de fusión de autopistas.

- Por último, también incluimos los conjuntos de datos de HalfCheetah, Hopper, y Walker2D del OpenAI Gym Mujoco. Estas tareas se han utilizado ampliamente en trabajos anteriores [1,2,3,4]y para asegurar que las evaluaciones sean comparables entre los documentos, hemos estandarizado los conjuntos de datos.



Direcciones futuras
En un futuro próximo, nos entusiasmaría ver que las aplicaciones de RL fuera de línea pasen de los dominios simulados a los dominios del mundo real, donde se pueden obtener fácilmente cantidades significativas de datos fuera de línea. Hay muchos problemas del mundo real en los que la RL fuera de línea podría tener un impacto significativo, incluyendo:
- Conducción autónoma
- Robótica
- Planes de atención médica y tratamiento
- Educación
- Sistemas de recomendación
- Agentes de diálogo
- ¡Y muchos más!
En muchos de estos dominios ya existen grandes conjuntos de datos de experiencia precolectados que esperan ser utilizados por un algoritmo de RL fuera de línea cuidadosamente diseñado. Creemos que el RL fuera de línea es muy prometedor como paradigma potencial para aprovechar las grandes cantidades de datos secuenciales existentes dentro del marco flexible de toma de decisiones del aprendizaje de refuerzo.
Si estás interesado en este benchmark, el código está disponible en código abierto en Github, y puedes ver nuestra página web para más detalles.