
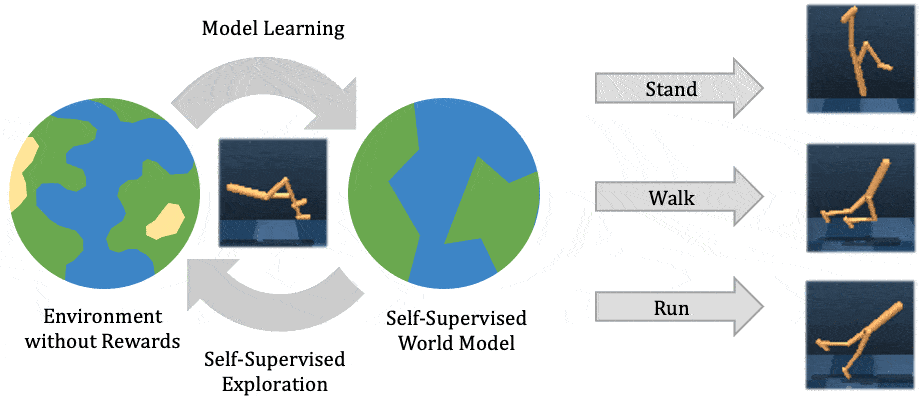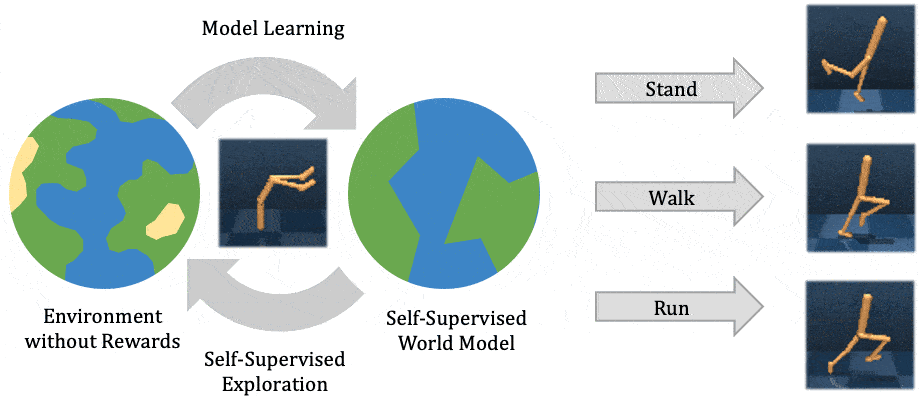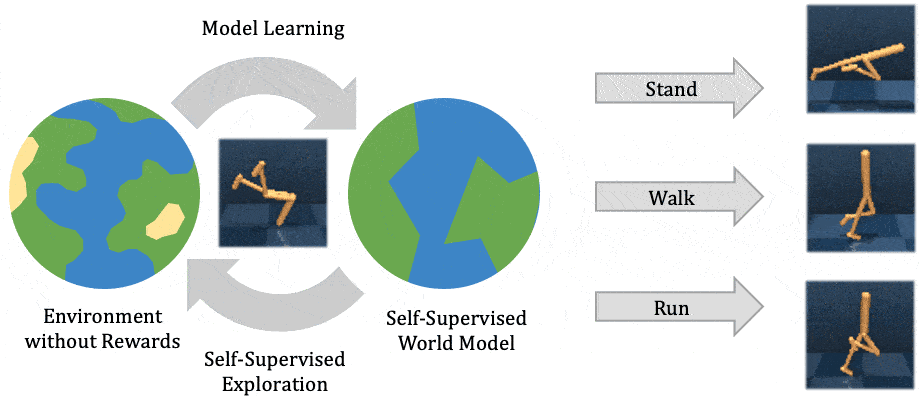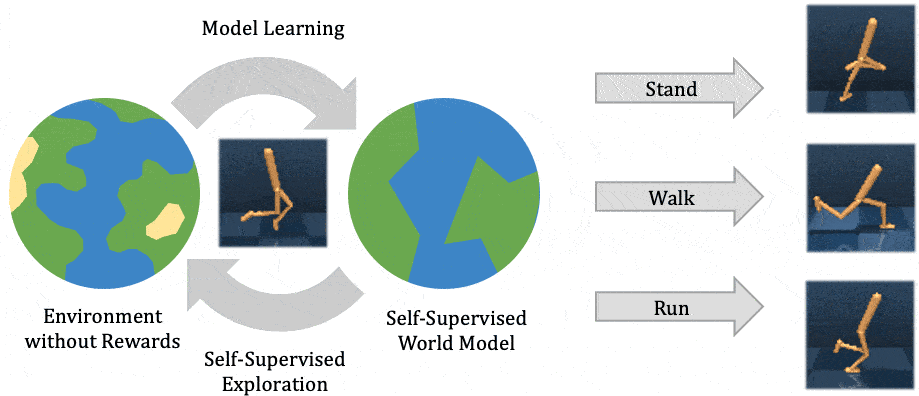
Esta entrada está en la lista cruzada del blog de la CMU ML.
Para operar con éxito en entornos de mundo abierto no estructurados, los agentes inteligentes autónomos necesitan resolver muchas tareas diferentes y aprender nuevas tareas rápidamente. El aprendizaje de refuerzo ha permitido a los agentes artificiales resolver tareas complejas tanto en la simulación como en el mundo real. Sin embargo, requiere reunir grandes cantidades de experiencia en el entorno, y el agente aprende sólo esa tarea en particular, de forma muy parecida a como un estudiante memoriza una conferencia sin comprenderla. El aprendizaje de refuerzo auto-supervisado ha surgido como una alternativa, en la que el agente sólo sigue un objetivo intrínseco independiente de cualquier tarea individual, de forma análoga al aprendizaje de representación no supervisado. Después de experimentar con el entorno sin supervisión, el agente construye una comprensión del entorno, que le permite adaptarse a tareas específicas posteriores de manera más eficiente.
En este post, explicamos nuestra reciente publicación que desarrolla Plan2Explore. Mientras que muchos trabajos recientes sobre el aprendizaje de refuerzo auto-supervisado se han centrado en agentes sin modelo que sólo pueden capturar el conocimiento recordando comportamientos practicados durante la auto-supervisión, nuestro agente aprende un modelo interno del mundo que le permite extrapolar más allá de los hechos memorizados, prediciendo lo que sucederá como consecuencia de diferentes acciones potenciales. El modelo mundial captura el conocimiento general, permitiendo a Plan2Explore resolver rápidamente nuevas tareas a través de la planificación en su propia imaginación. En contraste con el trabajo previo sin modelo, el modelo mundial permite al agente explorar lo que espera que sea novedoso, en lugar de repetir lo que encontró novedoso en el pasado. Plan2Explore obtiene un rendimiento de vanguardia de cero y pocos disparos en puntos de referencia de control continuo con imágenes de entrada de alta dimensión. Para facilitar la experimentación con nuestro agente, estamos abriendo el código fuente completo.
A un alto nivel, Plan2Explore trabaja entrenando a un modelo mundial, explorando para
maximizar la ganancia de información para el modelo mundial, y usando el modelo mundial en
tiempo de prueba para resolver nuevas tareas (ver figura arriba). Gracias a la eficaz
exploración, el modelo del mundo aprendido es general y captura información que
puede ser usado para resolver múltiples tareas nuevas sin o con poco entorno adicional
interacciones. Discutimos cada parte del algoritmo de Plan2Explore individualmente
abajo. Asumimos una comprensión básica del refuerzo
aprendizaje en este puesto.
Plan2Explore aprende un modelo mundial que predice los resultados futuros dado el pasado
observaciones $o_{1:t}$ y acciones $a_{1:t}$. Para manejar la imagen de alta dimensión
las observaciones, las codificamos en características de dimensiones inferiores $h$ y usamos un RSSM
modelo que predice hacia adelante en un espacio compacto de estado latente $s$. La latente
El estado agrega la información de observaciones pasadas y se capacita para el futuro
predicción, utilizando un objetivo variacional que reconstruye el futuro
observaciones. Ya que el estado latente aprende a representar las observaciones,
durante la planificación podemos predecir completamente en estado latente sin decodificar
las imágenes en sí mismas. La siguiente figura muestra nuestra predicción latente
arquitectura.

Para aprender un modelo mundial preciso y general necesitamos una estrategia de exploración
que recoge datos nuevos e informativos. Para lograrlo, Plan2Explore utiliza un
métrica novedosa derivada del propio modelo. La métrica de novedad mide la
esperaban la información obtenida sobre el medio ambiente al observar los nuevos datos.
Como muestra la figura siguiente, esto se aproxima por el desacuerdo de
un conjunto de modelos latentes de $K$.
Intuitivamente, un gran desacuerdo latente refleja una alta incertidumbre en los modelos, y
La obtención del punto de datos reduciría esta incertidumbre. Al maximizar la latencia
desacuerdo, Plan2Explore selecciona las acciones que conducen a la mayor información
ganancia, por lo tanto mejorando el modelo lo más rápido posible.
Para maximizar efectivamente la novedad, necesitamos saber qué partes del entorno
siguen sin ser explorados. La mayoría de los trabajos anteriores de exploración auto-supervisada utilizaron
métodos sin modelos que refuerzan el comportamiento pasado que resultó en novedosos
experiencia. Esto hace que estos métodos sean lentos para explorar: ya que sólo pueden
repetir el comportamiento de exploración que tuvo éxito en el pasado, son poco probables
para tropezar con algo novedoso. Por el contrario, Plan2Explore planea para la esperada
novedad al medir la incertidumbre del modelo de los resultados futuros imaginados. Al buscar
trayectorias que tienen la mayor incertidumbre, Plan2Explore explora exactamente
las partes de los ambientes que antes eran desconocidas.
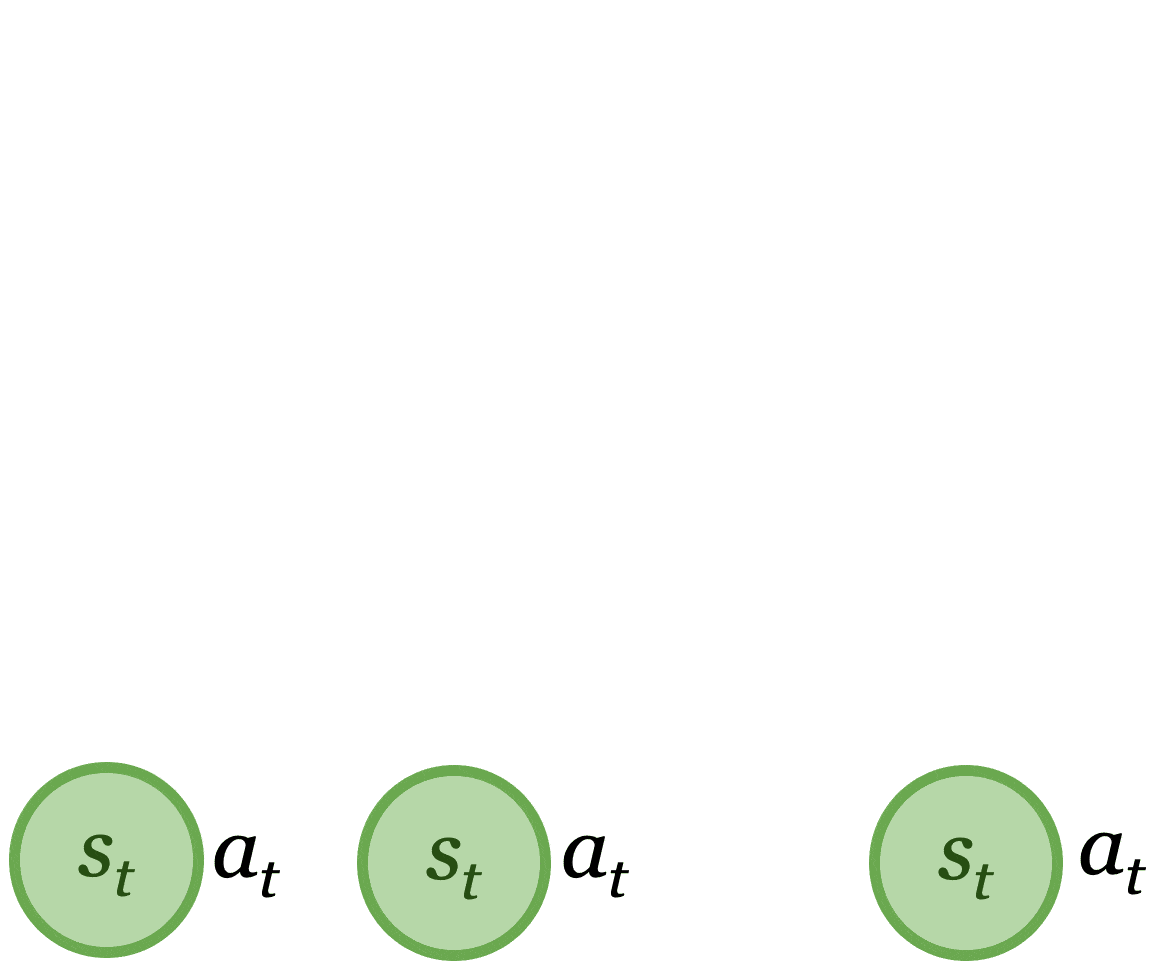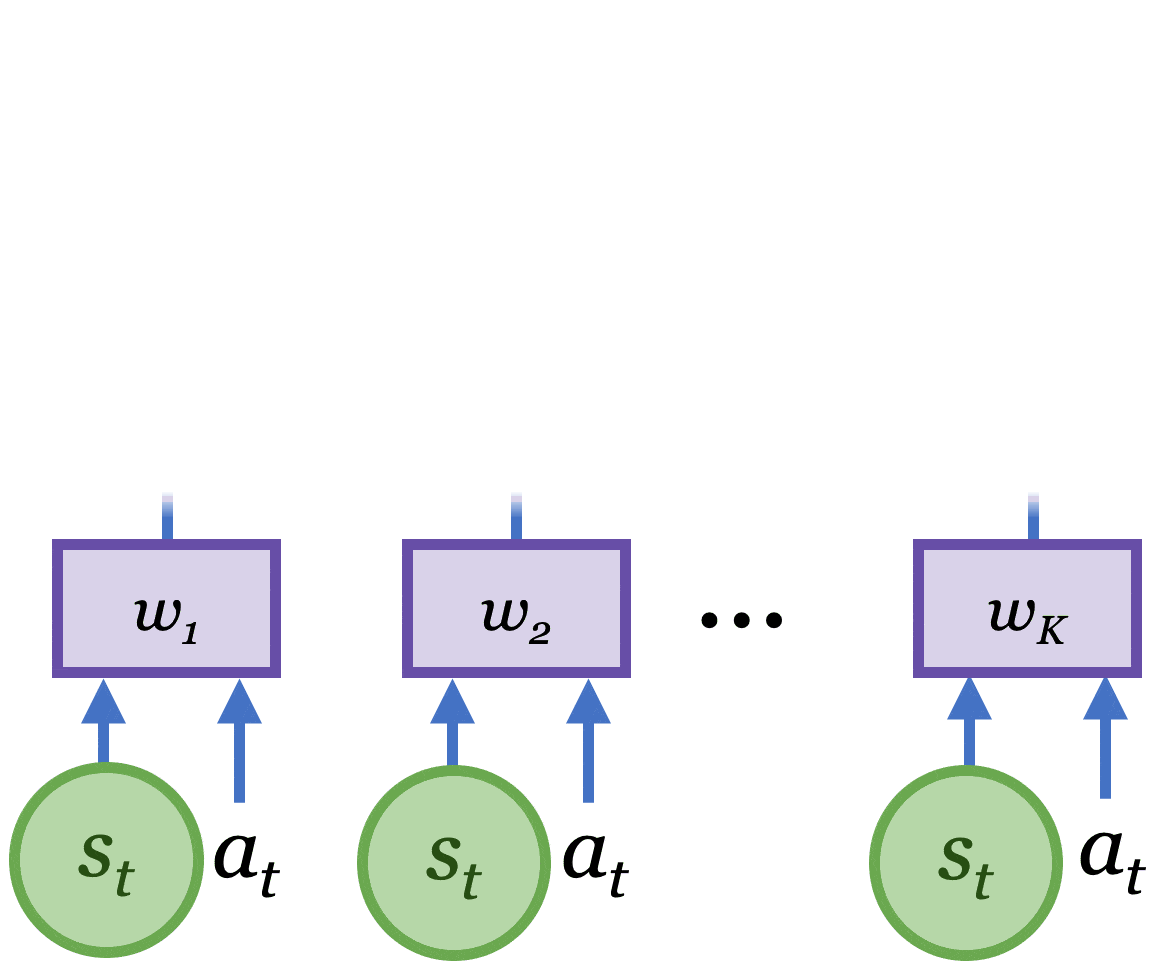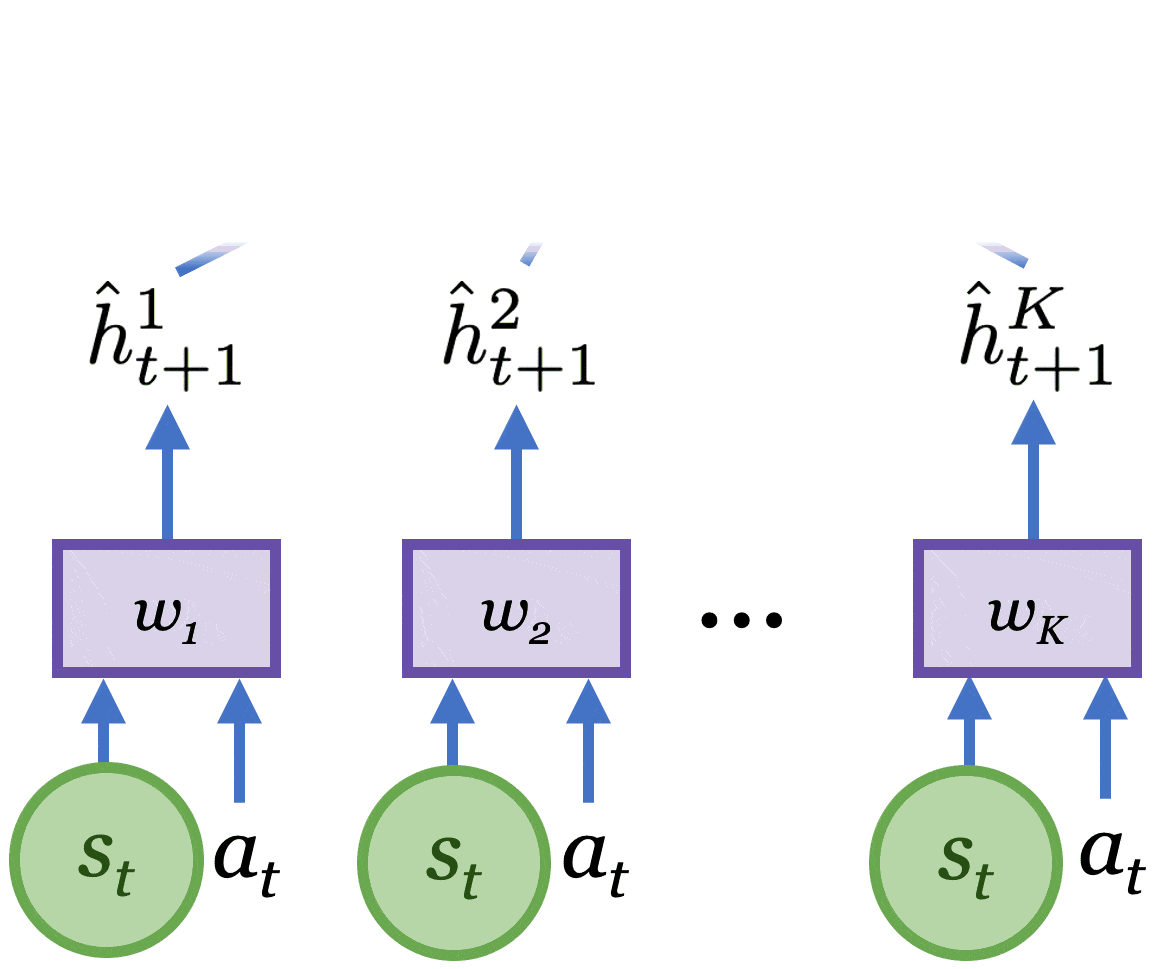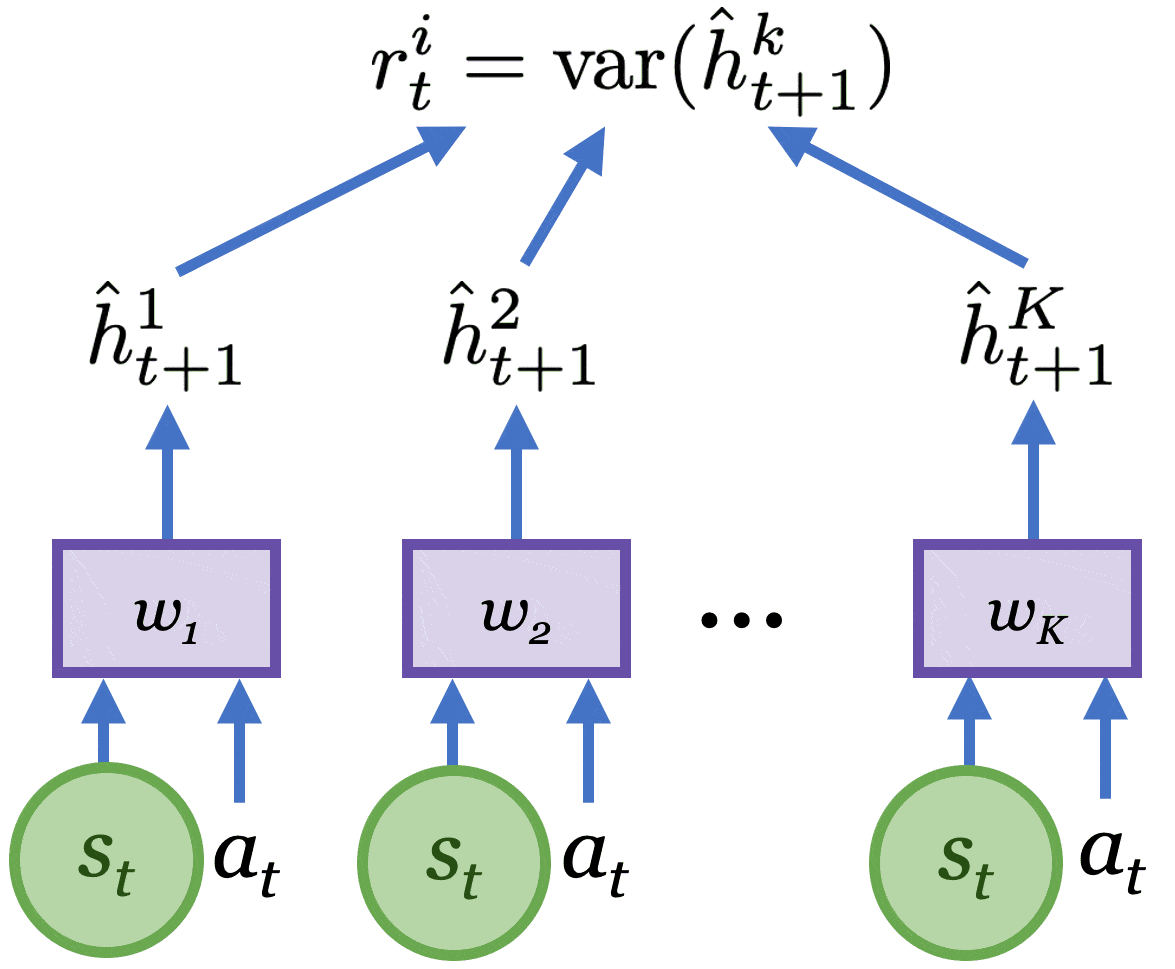
Para elegir las acciones $a$ que optimicen el objetivo de exploración, Plan2Explore
aprovecha el modelo de mundo aprendido como se muestra en la figura a continuación. Las acciones son
seleccionado para maximizar la esperada novedad de toda la secuencia futura
usando despliegues imaginarios del modelo mundial para estimar la novedad.
Para resolver este problema de optimización, usamos el Dreamer
agente, que aprende una política $pi_phi$ usando una función de valor y analítica
gradientes a través del modelo. La política se aprende completamente dentro de la
la imaginación del modelo mundial. Durante la exploración, este entrenamiento de la imaginación
asegura que nuestra política de exploración está siempre al día con el mundo actual
y recoge datos que aún son novedosos. La siguiente figura muestra el
proceso de entrenamiento de la imaginación.

Evaluamos Plan2Explore en la Suite de Control de Mente Profunda, que
presenta 20 tareas que requieren diferentes habilidades de control, como la locomoción,
balanceo, y simple manipulación de objetos. El agente sólo tiene acceso a la imagen
observaciones y ninguna información propioceptiva. En lugar de la exploración aleatoria,
que no lleva al agente lejos de la posición inicial, Plan2Explore lleva
a diversas estrategias de movimiento como saltar, correr y dar vueltas, como se muestra en
la figura de abajo. Más tarde, veremos que estos son episodios de práctica efectiva
que permiten al agente aprender rápidamente a resolver varios controles continuos
tareas.






Una vez que se aprende un modelo mundial preciso y general, probamos Plan2Explore en
tareas no vistas anteriormente. Dada una tarea especificada con una función de recompensa, usamos
el modelo para optimizar una política para esa tarea. Similar a nuestra exploración
procedimiento, optimizamos una nueva función de valor y una nueva cabeza de política para el
tarea de abajo. Esta optimización utiliza sólo las predicciones imaginadas por el modelo,
permitiendo que Plan2Explore resuelva nuevas tareas de abajo de una manera de cero.
sin ninguna interacción adicional con el mundo.
La siguiente gráfica muestra el desempeño de Plan2Explore en tareas de DM
Suite de control. Antes de 1 millón de pasos de entorno, el agente no conoce el
y simplemente explora. El agente resuelve la tarea tan pronto como se le proporciona
en 1 millón de pasos, y sigue mejorando rápidamente en un régimen de pocos disparos después de eso.
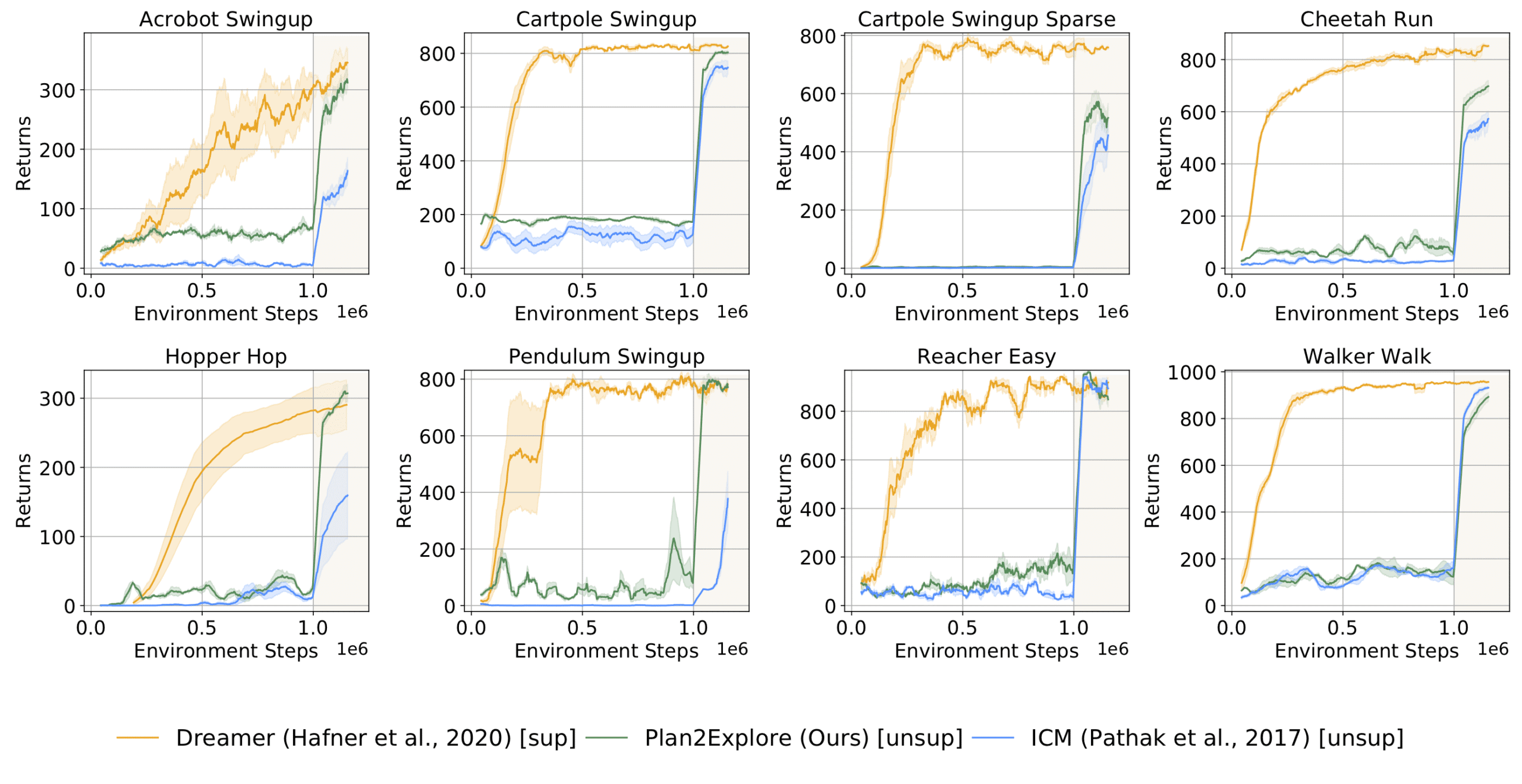
Plan2Explore (—) es capaz de resolver la mayoría de las tareas que hemos comparado. Desde antes
trabajar en el aprendizaje de refuerzo auto-supervisado usando agentes sin modelo que son
no es capaz de adaptarse de una manera de cero (ICM, —), o no usó
observaciones de imágenes, comparamos adaptando este trabajo previo a nuestro modelo basado en
Plan2Configuración de exploración. Nuestro objetivo de desacuerdo latente supera a otros
los objetivos propuestos anteriormente. Más interesante aún, la actuación final de
Plan2Explore es comparable al oráculo de última generación
que requiere recompensas por la tarea a lo largo de la formación (—). En nuestro documento, informamos además
la ejecución de Plan2Explore en el escenario de tiro cero donde el agente necesita
resolver la tarea antes de cualquier práctica orientada a la tarea.
Plan2Explore demuestra que el comportamiento efectivo puede ser aprendido a través de
sólo la exploración auto-supervisada. Esto abre múltiples vías para el futuro
investigación:
-
En primer lugar, para aplicar la auto-supervisión de RL a una variedad de entornos, el trabajo futuro
investigar diferentes formas de especificar la tarea y derivar el comportamiento de
el modelo mundial. Por ejemplo, la tarea podría especificarse con un
demostración, descripción del estado del objetivo deseado, o comunicado a la
agente en lenguaje natural. -
En segundo lugar, mientras que Plan2Explore está completamente auto-supervisado, en muchos casos un
hay una señal de supervisión débil, como en los juegos de exploración dura,
el aprendizaje humano en el bucle, o la vida real. En tal escenario semi-supervisado,
es interesante investigar cómo se puede utilizar una débil supervisión para dirigir
exploración hacia las partes pertinentes del medio ambiente. -
Por último, Plan2Explore tiene el potencial de mejorar la eficiencia de los datos de
sistemas robóticos del mundo real, donde la exploración es costosa y consume mucho tiempo,
y la tarea final es a menudo desconocida de antemano.
Diseñando una forma escalable de planificar la exploración en entornos no estructurados
con observaciones visuales, Plan2Explore proporciona un importante paso hacia
máquinas inteligentes auto-supervisadas.
Nos gustaría agradecer a Georgios Georgakis y a los editores de los blogs de CMU y BAIR por los útiles comentarios.
Este post está basado en el siguiente documento:
- Planeando explorar a través de modelos de mundo auto-supervisados
Ramanan Sekar*, Oleh Rybkin*, Kostas Daniilidis, Pieter Abbeel, Danijar Hafner, Deepak Pathak
37ª Conferencia Internacional de Aprendizaje Automático (ICML), 2020.
arXiv, sitio web del proyecto