
El rápido aumento del poder computacional y la accesibilidad de los cálculos han permitido una amplia gama de aplicaciones en gráficos y visión por computadora. Como resultado, ahora es posible realizar tareas complejas como detección de objetos, reconocimiento facial y reconstrucción 3D en poco tiempo. Especialmente en el dominio 3D, los avances en la visión por computadora y los gráficos han permitido el desarrollo de juegos basados en computadora, películas y animaciones 3D de prueba de concepto, y opciones para experiencias de realidad virtual y aumentada. Además, muchas aplicaciones en visión por computadora y gráficos están a punto de abordarse o ya se han abordado con la ayuda del aprendizaje profundo y la inteligencia artificial.
Estos métodos se basan en redes neuronales artificiales, que se utilizan para aprender patrones complejos en los datos. Las redes de aprendizaje profundo son jerárquicas, lo que significa que están compuestas de múltiples capas, y cada capa aprende un patrón determinado. El proceso de aprendizaje puede ser supervisado, lo que significa que se utilizan datos etiquetados para entrenar el modelo, o no supervisado, lo que significa que no se proporcionan datos etiquetados para el proceso de entrenamiento. Una vez entrenado, el modelo puede hacer predicciones sobre datos que no ha visto antes. En este sentido, la predicción no se limita estrictamente a la definición de su término. Se relaciona con una gran cantidad de operaciones como detección de objetos, clasificación de objetos/entidades, generación multimedia, compresión de nubes de puntos y mucho más.
El uso de estas redes neuronales para abordar problemas en el dominio 3D puede ser complicado, ya que requiere más poder computacional y atención que en el dominio 2D. Una tarea importante está relacionada con la edición 3D y la interpretación humana de los parámetros geométricos.
Facilitar el proceso de edición o personalización en 3D puede ser importante para las aplicaciones de juegos o gráficos por computadora. Las personas interesadas en los juegos probablemente conozcan los detalles de la personalización que algunos editores pueden proporcionar al crear un avatar personalizado en los juegos, desde el deporte hasta la acción. ¿Alguna vez te has preguntado cuánto tiempo lleva configurar todas estas características por parte del desarrollador? Definir todas esas características puede llevar semanas o, en el peor de los casos, meses.
Las buenas noticias provienen del trabajo de investigación presentado en este artículo que arroja luz sobre este problema y propone una solución para automatizar este proceso.
El marco propuesto se representa en la siguiente figura.
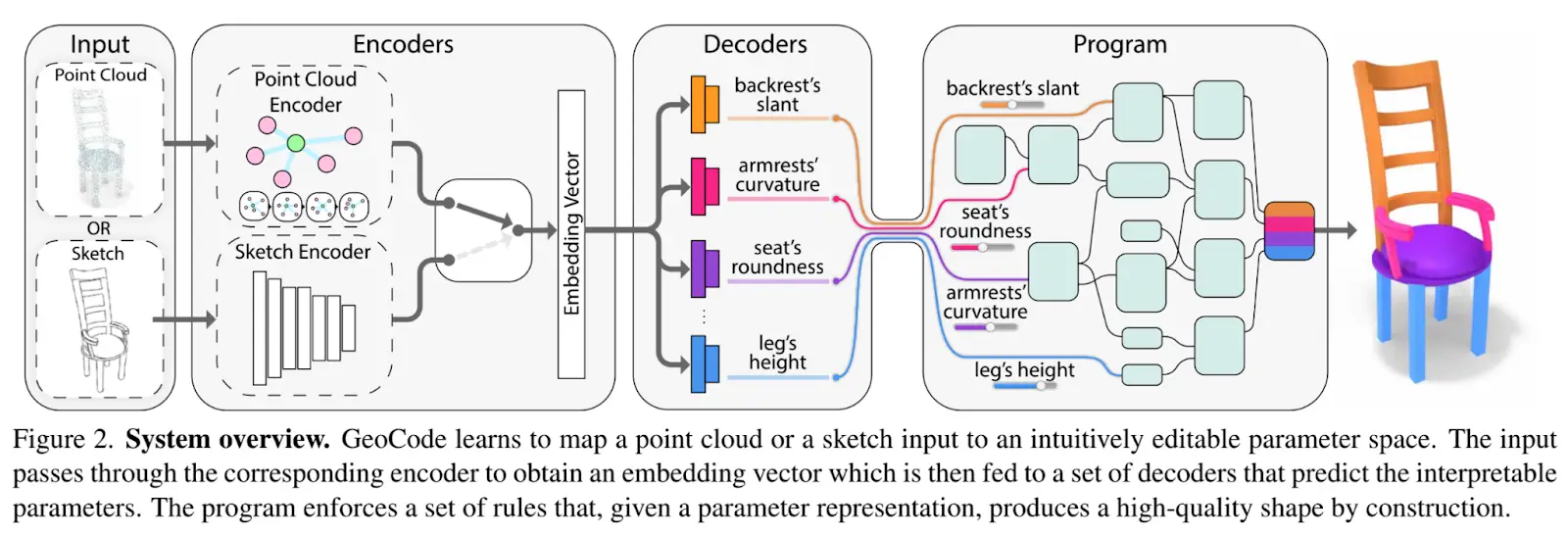
El objetivo es recuperar una malla 3D editable a partir de un elemento de entrada representado como una nube de puntos 3D o una imagen de croquis 2D. Para hacer esto, los autores crean un software de procedimiento que impone un conjunto de restricciones de forma y está parametrizado por controles que son fáciles de entender para los humanos. Después de enseñar a una red neuronal a inferir los parámetros del programa, pueden generar y recuperar una forma 3D editable ejecutando el programa. Esta aplicación tiene controles sencillos además de datos estructurales, lo que lleva a una segmentación de porción semántica consistente por edificio.
Específicamente, el programa admite tres parámetros: discreto, binario y continuo. El desenredo de los parámetros de forma garantiza un control preciso sobre las características del objeto. Por ejemplo, podemos aislar la forma del asiento de las otras partes de una silla. Por lo tanto, modificar el asiento no afectará a la geometría de los demás parámetros, como el respaldo o las piernas.
Para obtener flexibilidad de edición, las primitivas de malla, como esferas o planos, se crean y modifican según las necesidades del usuario. Dos curvas guían la generación de la forma final: una curva unidimensional que describe una ruta en el espacio 3D y una curva bidimensional que representa el perfil de la forma.
Definir curvas de esta manera permite una gran variedad de combinaciones, especificadas no solo por las propias curvas, sino también por los puntos de enlace, que son los puntos en los que dos curvas se conectan entre sí. Estos puntos se pueden definir mediante un valor flotante escalar de 0 a 1, donde 0 representa el comienzo y 1 es el final de la curva.
Antes de enviar los parámetros al programa para la recuperación final de la forma 3D, se explota una arquitectura de red de codificador-decodificador para mapear una nube de puntos o entrada de croquis a la representación de parámetros.
El codificador incrusta la entrada en un vector de características global. Luego, las incrustaciones de vectores se alimentan a un conjunto de decodificadores, cada uno con el alcance de traducir la entrada en un solo parámetro (desenredo).
GeoCode se puede utilizar para diversas tareas de edición, como la interpolación entre formas. Un ejemplo se muestra en la siguiente figura.

Este fue el resumen de GeoCode, un nuevo marco de IA para abordar el problema de la síntesis de formas 3D. Si estás interesado, puedes encontrar más información en los siguientes enlaces.
Revisar la Papel, Githuby Proyecto. Todo el crédito de esta investigación es para los investigadores de este proyecto. Además, no olvides unirte nuestra página de Reddit, Canal de discordiay Boletín electrónicodonde compartimos las últimas noticias de investigación de IA, interesantes proyectos de IA y más.
Daniele Lorenzi recibió su M.Sc. en TIC para Ingeniería de Internet y Multimedia en 2021 de la Universidad de Padua, Italia. Él es un Ph.D. candidato en el Instituto de Tecnología de la Información (ITEC) en la Alpen-Adria-Universität (AAU) Klagenfurt. Actualmente trabaja en el Laboratorio Christian Doppler ATHENA y sus intereses de investigación incluyen transmisión de video adaptable, medios inmersivos, aprendizaje automático y evaluación de QoS/QoE.
