

Imagen de Adobe Firefly
Hace poco inicié un boletín educativo centrado en la IA, que ya tiene más de 160 000 suscriptores. TheSequence es un boletín sin BS (es decir, sin exageraciones, sin noticias, etc.) orientado a ML que tarda 5 minutos en leerse. El objetivo es mantenerlo actualizado con proyectos de aprendizaje automático, trabajos de investigación y conceptos. Pruébalo suscribiéndote a continuación:
Los avances recientes en los modelos de lenguaje extenso (LLM) han revolucionado el campo, equipándolos con nuevas capacidades como el diálogo natural, el razonamiento matemático y la síntesis de programas. Sin embargo, los LLM todavía enfrentan limitaciones inherentes. Su capacidad para almacenar información está restringida por pesos fijos y sus capacidades de cálculo están limitadas a un gráfico estático y un contexto estrecho. Además, a medida que el mundo evoluciona, los LLM necesitan volver a capacitarse para actualizar sus conocimientos y habilidades de razonamiento. Para superar estas limitaciones, los investigadores han comenzado a empoderar a los LLM con herramientas. Al otorgar acceso a bases de conocimiento extensas y dinámicas y permitir tareas computacionales complejas, los LLM pueden aprovechar las tecnologías de búsqueda, las bases de datos y las herramientas computacionales. Los principales proveedores de LLM han comenzado a integrar complementos que permiten a los LLM invocar herramientas externas a través de API. Esta transición de un conjunto limitado de herramientas codificadas a mano para acceder a una amplia gama de API en la nube tiene el potencial de transformar los LLM en la interfaz principal para la infraestructura informática y la web. Tareas como reservar vacaciones u organizar conferencias pueden ser tan simples como conversar con un LLM que tiene acceso a API web de vuelos, alquiler de automóviles, hoteles, catering y entretenimiento.
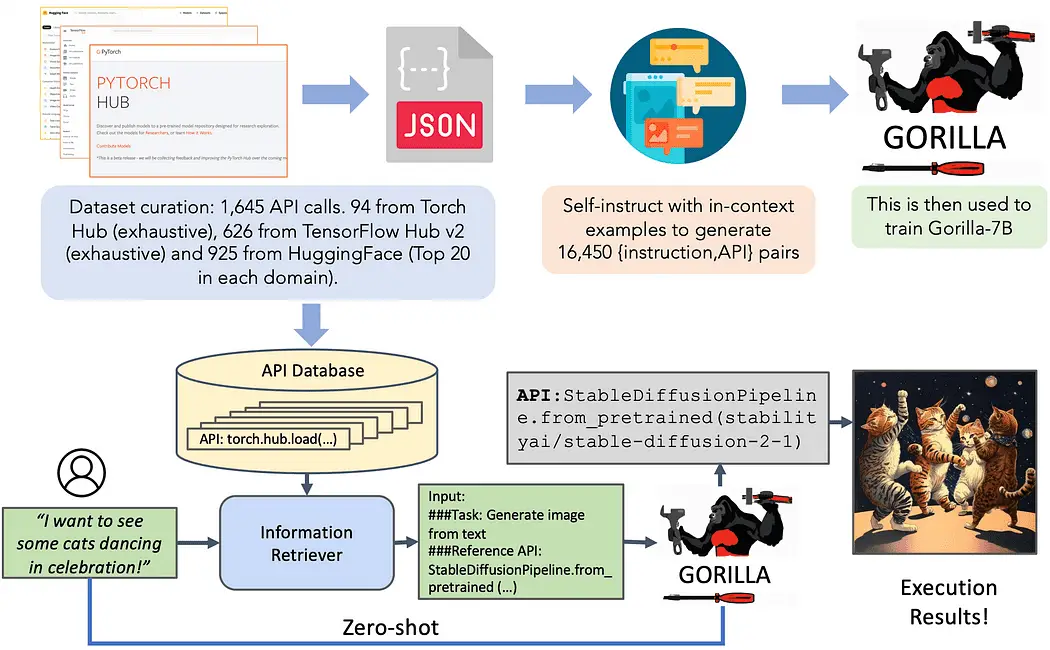
Recientemente, investigadores de UC Berkeley y Microsoft dieron a conocer Gorilla, un modelo LLaMA-7B diseñado específicamente para llamadas API. Gorilla se basa en técnicas de ajuste y recuperación autodidactas para permitir que los LLM seleccionen con precisión de un conjunto grande y en evolución de herramientas expresadas a través de sus API y documentación. Los autores construyen un gran corpus de API, llamado APIBench, extrayendo API de aprendizaje automático de los principales centros de modelos como TorchHub, TensorHub y HuggingFace. Al usar autoinstrucciones, generan pares de instrucciones y las API correspondientes. El proceso de ajuste fino implica convertir los datos a un formato de conversación de estilo de chat de usuario-agente y realizar el ajuste fino de instrucciones estándar en el modelo base LLaMA-7B.

Crédito de la imagen: Universidad de California en Berkeley
Las llamadas API a menudo vienen con restricciones, lo que agrega complejidad a la comprensión y categorización de las llamadas por parte del LLM. Por ejemplo, una solicitud puede requerir la invocación de un modelo de clasificación de imágenes con restricciones de tamaño y precisión de parámetros específicos. Estos desafíos resaltan la necesidad de que los LLM comprendan no solo la descripción funcional de una llamada API, sino también el razonamiento sobre las restricciones integradas.
El conjunto de datos centrado en la tecnología en cuestión abarca tres dominios distintos: Torch Hub, Tensor Hub y HuggingFace. Cada dominio contribuye con una gran cantidad de información, lo que arroja luz sobre la naturaleza diversa del conjunto de datos. Torch Hub, por ejemplo, ofrece 95 API, lo que proporciona una base sólida. En comparación, Tensor Hub va un paso más allá con una amplia colección de 696 API. Por último, HuggingFace lidera el paquete con 925 API, lo que lo convierte en el dominio más completo.
Para amplificar el valor y la usabilidad del conjunto de datos, se ha emprendido un esfuerzo adicional. Cada API en el conjunto de datos va acompañada de un conjunto de 10 instrucciones meticulosamente diseñadas y adaptadas de forma única. Estas instrucciones sirven como guías indispensables tanto para fines de capacitación como de evaluación. Esta iniciativa garantiza que cada API vaya más allá de la mera representación, lo que permite una utilización y un análisis más sólidos.
Gorilla introduce la noción de entrenamiento consciente de los perros perdigueros, donde el conjunto de datos ajustado por instrucciones incluye un campo adicional con documentación API recuperada como referencia. Este enfoque tiene como objetivo enseñar al LLM a analizar y responder preguntas en función de la documentación proporcionada. Los autores demuestran que esta técnica permite que el LLM se adapte a los cambios en la documentación de la API, mejora el rendimiento y reduce los errores de alucinación.
Durante la inferencia, los usuarios proporcionan indicaciones en lenguaje natural. Gorilla puede operar en dos modos: tiro cero y recuperación. En el modo de disparo cero, el indicador se alimenta directamente al modelo Gorilla LLM, que devuelve la llamada a la API recomendada para lograr la tarea o el objetivo. En el modo de recuperación, el recuperador (ya sea BM25 o GPT-Index) recupera la documentación API más actualizada de la base de datos API. Esta documentación está concatenada con el indicador del usuario, junto con un mensaje que indica la referencia a la documentación de la API. La entrada concatenada luego se pasa a Gorilla, que genera la API que se invocará. La sintonización rápida no se realiza más allá del paso de concatenación en este sistema.
Crédito de la imagen: Universidad de California en Berkeley
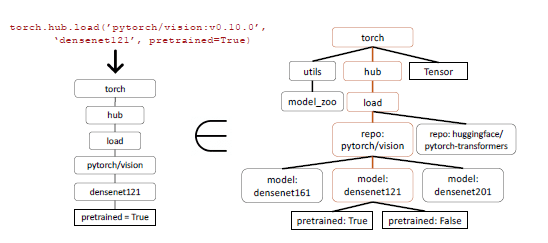
La síntesis de programas inductivos ha logrado el éxito en varios dominios mediante la síntesis de programas que cumplen con casos de prueba específicos. Sin embargo, cuando se trata de evaluar las llamadas a la API, depender únicamente de los casos de prueba se queda corto, ya que se vuelve un desafío verificar la corrección semántica del código. Consideremos el ejemplo de clasificación de imágenes, donde hay más de 40 modelos diferentes disponibles para la tarea. Incluso si lo reducimos a una familia específica, como Densenet, hay cuatro configuraciones posibles. En consecuencia, existen múltiples respuestas correctas, lo que dificulta determinar si la API que se utiliza es funcionalmente equivalente a la API de referencia a través de pruebas unitarias. Para evaluar el rendimiento del modelo, se realiza una comparación de su equivalencia funcional utilizando el conjunto de datos recopilados. Para identificar la API llamada por el LLM en el conjunto de datos, se emplea una estrategia de coincidencia de árboles AST (Abstract Syntax Tree). Al verificar si el AST de una llamada API candidata es un subárbol de la llamada API de referencia, es posible rastrear qué API se está utilizando.
Identificar y definir las alucinaciones plantea un desafío importante. El proceso de coincidencia de AST se aprovecha para identificar las alucinaciones directamente. En este contexto, una alucinación se refiere a una llamada de API que no es un subárbol de ninguna API en la base de datos, esencialmente invocando una herramienta completamente imaginada. Es importante tener en cuenta que esta definición de alucinación difiere de la invocación incorrecta de una API, que se define como un error.
La coincidencia del subárbol AST juega un papel crucial en la identificación de la API específica que se llama dentro del conjunto de datos. Dado que las llamadas a la API pueden tener múltiples argumentos, cada uno de estos argumentos debe coincidir. Además, teniendo en cuenta que Python permite argumentos predeterminados, es esencial definir qué argumentos coincidir para cada API en la base de datos.
Crédito de la imagen: Universidad de California en Berkeley
Junto con el artículo, los investigadores crearon una versión de código abierto de Gorilla. El lanzamiento incluye un cuaderno con muchos ejemplos. Además, el siguiente video muestra claramente algo de la magia de los gorilas.
gorilla_720p.mp4
Gorilla es uno de los enfoques más interesantes en el espacio LLM mejorado con herramientas. Con suerte, veremos el modelo distribuido en algunos de los principales centros de ML en el espacio.
Jesús Rodríguez Actualmente es CTO en Intotheblock. Es experto en tecnología, inversor ejecutivo y asesor de startups. Jesús fundó Tellago, una firma de desarrollo de software galardonada que se enfoca en ayudar a las empresas a convertirse en grandes organizaciones de software aprovechando las nuevas tendencias de software empresarial.
Original. Reposteado con permiso.