
A pesar de los recientes avances en la investigación de la inteligencia artificial, los humanos
los niños siguen siendo, con mucho, los mejores alumnos que conocemos, aprendiendo impresionantemente
habilidades como el lenguaje y el razonamiento de alto nivel a partir de muy pocos datos. Los niños
el aprendizaje se apoya en una exploración altamente eficiente, impulsada por hipótesis: en
De hecho, exploran tan bien que muchos investigadores de aprendizaje de máquinas han sido
inspirados en poner videos como el que sigue en sus charlas para motivar la investigación
en los métodos de exploración. Sin embargo, debido a que la aplicación de los resultados de los estudios en
la psicología del desarrollo puede ser difícil, este vídeo es a menudo el grado de
que tal investigación realmente conecta con la cognición humana.

Un lapso de tiempo de un bebé jugando con juguetes. Fuente.
¿Por qué se aplica directamente la investigación de la psicología del desarrollo a los problemas en
¿Tan difícil es la IA? Para empezar, inspirarse en los estudios sobre el desarrollo puede ser
difícil porque los entornos que los niños humanos y los agentes artificiales
son típicamente estudiadas en puede ser muy diferente. Tradicionalmente, el refuerzo
La investigación de aprendizaje (RL) se lleva a cabo en un entorno similar a la red o en otro 2D
juegos, mientras que los niños actúan en el mundo real que es rico y tridimensional.
Además, las comparaciones entre los niños y los agentes de la IA son difíciles de hacer
porque los experimentos no están controlados y a menudo tienen un objetivo
desajuste; gran parte de la investigación en psicología del desarrollo con niños toma
con los niños que participan en la libre exploración, mientras que la mayoría de las investigaciones
en la IA es impulsada por objetivos. Finalmente, puede ser difícil «cerrar el círculo», y no sólo
construyen agentes inspirados en los niños, pero aprenden sobre la cognición humana de
resultados en la investigación de la IA. Al estudiar a los niños y los agentes artificiales en el
mismo, controlado, entorno 3D podemos potencialmente aliviar muchos de estos
problemas anteriores y, en última instancia, el progreso de la investigación tanto en la IA como en la cognición
ciencia.
En colaboración con Jessica Hamrick y Sandy Huang de DeepMind, y Deepak
Pathak, Pulkit Agrawal, John Canny, Alexei A. Efros, Jeffrey Liu, y Alison Gopnik de la UC Berkeley, que es
exactamente lo que este trabajo pretende hacer. Hemos desarrollado una plataforma y un marco
para contrastar directamente el agente y la exploración del niño basado en DeepMind Lab – un
navegación en 3D en primera persona y un entorno de resolución de puzzles originalmente construido para
…probando agentes en laberintos con ricas imágenes.

Lo principal que sabemos sobre la exploración infantil es que los niños forman
hipótesis sobre cómo funciona el mundo, y se dedican a la exploración para probar
esas hipótesis. Por ejemplo, estudios como el de Liz Bonawitz y
al., 2007 nos mostró que el juego exploratorio de los niños de preescolar se ve afectado por la
pruebas que observan. Concluyen que si parece que hay múltiples
formas en que un juguete podría funcionar pero no está claro cuál es la correcta (en otras
palabras, las pruebas son causalmente confusas) entonces los niños se involucran en
la exploración impulsada por hipótesis y explorará el juguete durante mucho más tiempo
que cuando la dinámica y el resultado son sencillos (en cuyo caso rápidamente
pasar a un nuevo juguete).
Stahl y Feigneson y otros, 2015 nos mostraron que cuando los bebés tan jóvenes como
A los 11 meses se les presentan objetos que violan las leyes físicas en su
los explorarán más e incluso se involucrarán en la prueba de hipótesis
comportamientos que reflejan el tipo particular de violación que se ha visto. Por ejemplo, si
ven un coche flotando en el aire (como en el vídeo de la izquierda), encuentran
esto es sorprendente; posteriormente, los niños golpean el juguete sobre la mesa para
explorar cómo funciona. En otras palabras, estas violaciones guían a los niños
exploración de una manera significativa.


El trabajo clásico en informática y en la IA se centró en el desarrollo de métodos de búsqueda
que tratan de buscar un objetivo. Por ejemplo, una estrategia de búsqueda de profundidad primero
continuar explorando por un camino particular hasta que el objetivo o un callejón sin salida
se alcanza. Si se llega a un callejón sin salida, retrocederá hasta el próximo
se encuentra un camino inexplorado y luego se procede por ese camino. Sin embargo, a diferencia de
la exploración de los niños, métodos como estos no tienen una noción de exploración
más dada la sorprendente evidencia, la recolección de información o la prueba de hipótesis.
Trabajos más recientes en RL han visto el desarrollo de otros tipos de exploración
algoritmos. Por ejemplo, los métodos de motivación intrínseca proporcionan una ventaja para
explorando regiones interesantes, como las que no han sido tan visitadas
previamente o las que son sorprendentes. Mientras que estos parecen en principio más
similar a la exploración de los niños, se utilizan típicamente más para exponer
agentes a un conjunto diverso de experiencias durante el entrenamiento, en lugar de apoyar
aprendizaje y exploración rápida en el momento de la decisión.
Para aliviar algunas de las dificultades mencionadas anteriormente en relación con la aplicación
resultados de la psicología del desarrollo a la investigación de la IA, desarrollamos un sistema en
que tenemos una comparación exacta entre los niños y el comportamiento de los agentes en el
exactamente el mismo ambiente con exactamente las mismas observaciones y mapas. Hacemos esto
usando DeepMind Lab, una plataforma existente para entrenar y evaluar agentes de RL.
Además, podemos restringir el espacio de acción en DeepMind Lab a cuatro simples
acciones (avanzar, retroceder, girar a la izquierda y a la derecha) usando controladores personalizados
construidas en el laboratorio, que facilitan a los niños la navegación por el
el medio ambiente. Por último, en el laboratorio de DeepMind podemos generar por procedimiento un enorme
cantidad de datos de entrenamiento que podemos usar para poner a los agentes al día en la
conceptos como «muro» y «meta».
En la imagen de abajo puedes ver una visión general de las partes de nuestro experimento
La configuración. A la izquierda, vemos cómo se ve cuando un niño está explorando la
laberinto usando el controlador y las 4 posibles acciones que pueden tomar. En el
en el medio, vemos lo que el niño está viendo mientras navega por el laberinto, y
a la derecha hay una vista aérea de la trayectoria general del niño en el
laberinto.
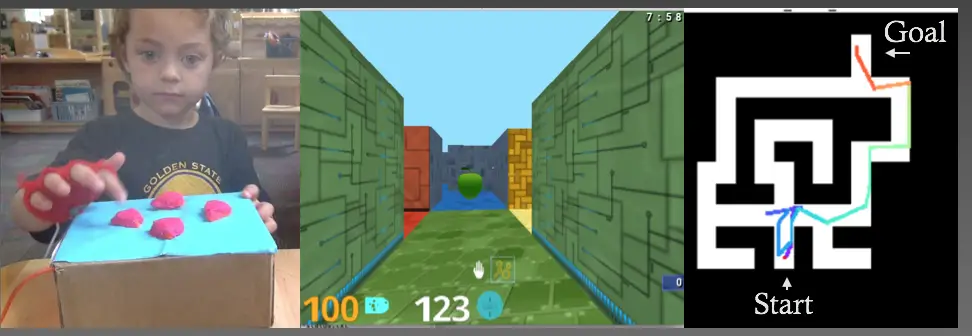
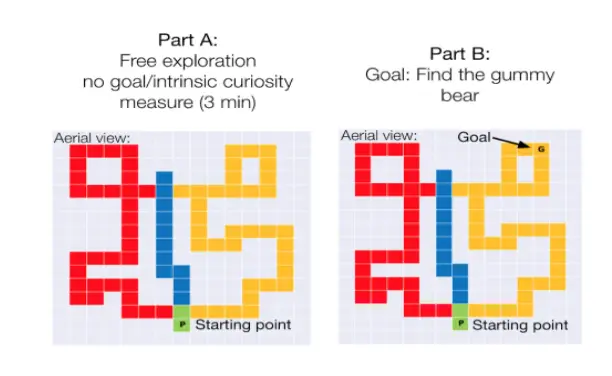
Primero investigamos si los niños (de 4 a 5 años) que son naturalmente
más curiosos/exploradores en un laberinto son más capaces de tener éxito en la búsqueda de un objetivo
más tarde introducidos en un lugar al azar. Para probar esto, hacemos que los niños exploren
el laberinto durante 3 minutos sin instrucciones específicas o metas, y luego
introducir un objetivo (representado como una gomita) en el mismo laberinto y luego preguntarle al
los niños para encontrar la gomita. Medimos ambos 1) el porcentaje del laberinto
exploró en la parte de la tarea de libre exploración y 2) cuánto tiempo, en términos de
número de pasos, se necesita que los niños encuentren la gomita después de que sea
introducidos.
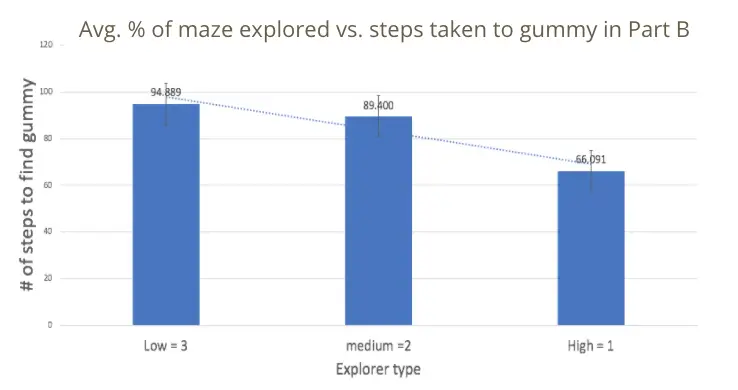
Desglosamos el porcentaje de laberinto explorado en 3 grupos: bajo, medio y
altos exploradores. Los exploradores bajos exploraron alrededor del 22% del laberinto en promedio,
los exploradores medianos exploraron alrededor del 44% del laberinto en promedio, y los altos
los exploradores exploraron alrededor del 71% del laberinto en promedio. Lo que encontramos es que el
menos exploración hizo el niño en la primera parte del laberinto, más pasos dio
los llevó a alcanzar la gomita. Este resultado se puede visualizar en el gráfico de barras de
la izquierda, donde el eje Y representa el número de pasos que les llevó encontrar
la gomita, y el eje X representa el tipo de explorador. Estos datos sugieren un
La tendencia de que los exploradores superiores son más eficientes para encontrar un objetivo en este laberinto
…el ajuste.
Ahora que tenemos datos de los niños en los laberintos, ¿cómo medimos la
diferencia entre un agente y una trayectoria humana? Un método es medir
si las acciones del niño son «consistentes» con las de una exploración específica
técnica. Dado un estado u observación específico, un humano o agente tiene un conjunto de
acciones que pueden ser tomadas desde este estado. Si el niño toma la misma acción
que un agente tomaría, llamamos a la elección de la acción «consistente». De lo contrario, la
la acción no sería coherente. Medimos el porcentaje de estados en un
la trayectoria del niño cuando la acción tomada por el niño es consistente con una
enfoque algorítmico. Llamamos a este porcentaje «coherencia de elección».
Una de las técnicas de exploración algorítmica más sencillas es hacer una sistemática
método de búsqueda llamado búsqueda en profundidad (DFS). De nuestra tarea, recuerde que
los niños tenían un laberinto en el que primero se dedicaban a la exploración libre, y luego a
búsqueda dirigida a un objetivo. Cuando comparamos la consistencia de la
trayectorias en esos 2 ajustes con los del algoritmo DFS, encontramos que
los niños en el escenario de la libre exploración toman acciones que son consistentes con el DFS
sólo el 90% de las veces, mientras que en el entorno orientado a la meta coinciden con el 96% de DFS
de la época.

Una forma de interpretar este resultado es que los niños en el entorno orientado a objetivos son
tomando acciones que son más sistemáticas que en la exploración libre. En otras
palabras, los niños se parecen más a un algoritmo de búsqueda cuando se les da una
gol.
En conclusión, este trabajo sólo comienza a tocar una serie de preguntas profundas
sobre cómo los niños y los agentes exploran. Los experimentos presentados aquí sólo
comenzar a abordar las cuestiones relativas a cuánto están dispuestos los niños y los agentes
para explorar; si las estrategias de exploración libre versus las dirigidas por objetivos difieren;
y cómo la creación de recompensas afecta a la exploración. Sin embargo, nuestra configuración nos permite preguntarnos
muchas más preguntas, y tenemos planes concretos para hacerlo.
Mientras que el DFS es una gran primera línea de base para la búsqueda no informada, para permitir una mejor
comparación, el siguiente paso es comparar las trayectorias de los niños con otras
algoritmos de búsqueda clásicos y a los de los agentes RL de la literatura.
Además, incluso los métodos más sofisticados de exploración en RL tienden a
exploran sólo al servicio de un objetivo específico, y suelen estar impulsados por el error
en lugar de buscar información. Alinear adecuadamente los objetivos de RL
algoritmos con los de un niño explorador es una pregunta abierta.
Creemos que para construir agentes inteligentes de verdad, deben hacer como los niños:
explorar activamente sus entornos, realizar experimentos y reunir
información para tejer juntos en un rico modelo del mundo. En este
dirección, seremos capaces de obtener una comprensión más profunda de la forma en que
los niños y los agentes exploran ambientes novedosos, y cómo cerrar la brecha
entre ellos.