
Conclusiones clave
- Los científicos de datos pasan la mayor parte de su tiempo construyendo arquitectura y preparando datos, NO construyendo modelos
- Las tiendas de características permiten que las características se registren, descubran, utilicen y compartan para las canalizaciones de ML en toda la empresa.
- Un RDBMS OLTP / OLAP combinado supera la latencia y la complejidad en la arquitectura tradicional del almacén de características en línea (NoSQL en tiempo real) y fuera de línea (almacén de datos SQL por lotes)
- Al optimizar el proceso de puesta en funcionamiento del aprendizaje automático, los modelos de aprendizaje automático se vuelven mucho más fáciles de administrar, implementar y operar.
El aprendizaje automático ahora ha entrado en su apogeo empresarial. Se pronosticó que casi la mitad de los CIOs habrán implementado IA para 2020, un número que se espera que crezca significativamente en los próximos cinco años. A pesar de ello, siete de cada diez ejecutivos cuyas empresas habían realizado inversiones en
La inteligencia artificial informó un impacto mínimo o nulo de ellos, según un informe de investigación de 2019 del MIT. ¿Por qué? Porque crear un modelo de aprendizaje automático y ponerlo en funcionamiento en un entorno empresarial son dos cosas muy diferentes. El mayor desafío para las empresas que buscan utilizar IA es operacionalizando aprendizaje automático, de la misma manera que DevOps operacionalizó el desarrollo de software en la década de 2000. Simplificar el flujo de trabajo de la ciencia de datos al proporcionar la arquitectura necesaria y automatizar el servicio de funciones con almacenes de funciones son dos de las formas más importantes de hacer que el aprendizaje automático sea fácil, preciso y rápido a escala.
Flujo de trabajo de ciencia de datos
En un silo típico de ciencia de datos, un nuevo proyecto sigue una canalización:
- recopilar datos relevantes de fuentes de datos,
- limpiar y organizar los datos,
- transformar los datos en funciones útiles,
- construir la arquitectura para ejecutar un modelo,
- entrenar un modelo en las características, y
- desplegando un modelo.
Aunque el entrenamiento y la implementación del modelo de aprendizaje automático puede parecer la parte más importante de este trabajo, solo el 20% del tiempo de un científico de datos se dedica a entrenar e implementar modelos; el 80% restante se gasta en la preparación de datos.
Teniendo en cuenta lo raros y costosos que son los científicos de datos para emplear, esta ineficiencia está lejos de ser ideal. La buena noticia es que existen muchos enfoques de MLOps que optimizan la arquitectura de ML y los datos para el proceso de características.
Arquitectura de ciencia de datos
Los días de los modelos simples cuyos datos de entrenamiento pueden caber en la hoja de cálculo de una computadora portátil se acabaron. Ahora, los datos tienen un tamaño mínimo de decenas de terabytes y, a menudo, a escala de petabytes. La construcción de la infraestructura informática distribuida que necesita para ejecutar las canalizaciones de funciones y el entrenamiento de modelos a esta escala es un gran dolor de cabeza para los científicos de datos.
Los contenedores se han vuelto necesarios para estas implementaciones a gran escala de aprendizaje automático. Sin embargo, para implementar un modelo, un científico de datos tiene que trabajar con ingenieros de aprendizaje automático para construir cada contenedor y envolverlo manualmente en una API RESTful para que el modelo pueda ser llamado desde aplicaciones. Esta es una codificación innecesaria y frustrantemente requiere la creación de nuevos contenedores para escalar un modelo. La integración de la arquitectura de Kubernetes automatiza la orquestación de contenedores para que los científicos de datos puedan escalar automáticamente sus modelos y se ha convertido en un estándar de la industria. Pero ejecutar una integración de Kubernetes requiere que los científicos de datos se conviertan en expertos de Kubernetes o colaboren con un ingeniero de aprendizaje automático para que lo haga por ellos.
La nueva implementación de la base de datos hace que sea lo más fácil posible implementar un modelo. Tradicionalmente, los modelos de punto final basados en contenedores, como se discutió anteriormente, requieren una ingeniería de software excesiva. Con la implementación de la base de datos, solo se necesita una línea de código para implementar un modelo. El sistema de implementación de la base de datos genera automáticamente una tabla y un activador que incorporan el entorno de ejecución del modelo. No más líos con los contenedores. Todo lo que un científico de datos tiene que hacer es ingresar registros de características en la tabla de la base de datos de predicciones generadas por el sistema para hacer inferencias sobre estas características. El sistema ejecutará automáticamente un disparador que ejecuta el modelo en los nuevos registros. Esto también ahorra tiempo para el reentrenamiento futuro, ya que la tabla de predicción contiene todos los ejemplos nuevos para agregar al conjunto de entrenamiento. Esto permite que las predicciones se mantengan continuamente actualizadas, fácilmente, con poco o ningún código manual.
Tiendas de características
El otro cuello de botella importante en la canalización de ML ocurre durante el proceso de transformación de datos: transformar manualmente los datos en funciones y entregar esas funciones al modelo de ML es un trabajo monótono y que requiere mucho tiempo.
A Tienda de características es un repositorio compartible de funciones creado para automatizar la entrada, el seguimiento y la gobernanza de los datos en modelos de aprendizaje automático. Las funciones almacenan funciones de cálculo y almacenamiento, lo que permite registrarlas, descubrirlas, utilizarlas y compartirlas en una empresa. Una tienda de características se asegura de que las características estén siempre actualizadas para las predicciones y mantiene el historial de los valores de cada característica de manera coherente, de modo que los modelos se puedan entrenar y volver a entrenar.
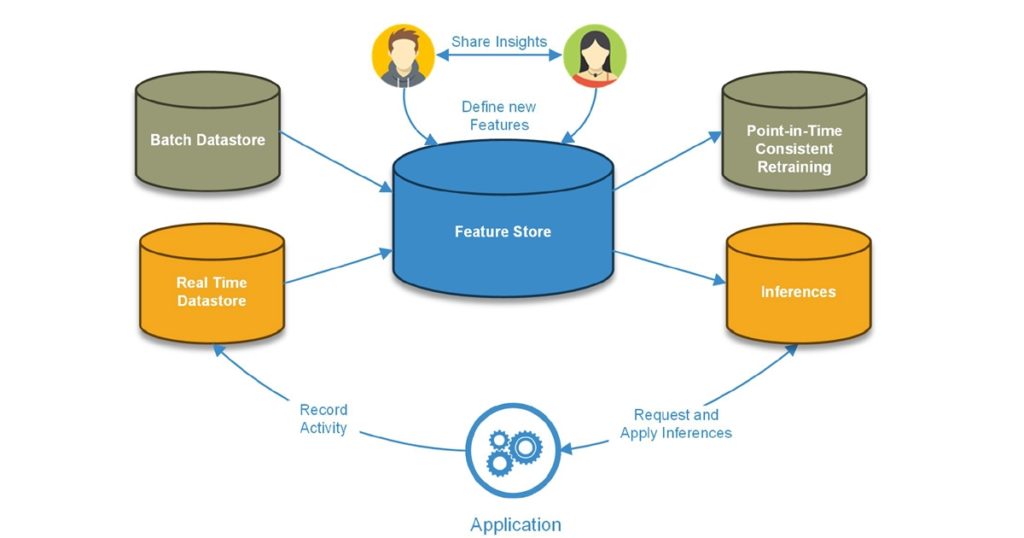
Arquitectura de la tienda de características

Figura 1: Arquitectura del almacén de características
Los almacenes de características se alimentan de canalizaciones que transforman los datos sin procesar en características. Estas características se pueden definir, declarar en grupos y asignar metadatos que faciliten su búsqueda. Una vez que las características están en la tienda, se utilizan para crear:
1. Vistas de entrenamiento. Se trata de declaraciones SQL arbitrarias que unen etiquetas con conjuntos de características, lo que permite a los científicos de datos asegurarse de que las características y las etiquetas sean coherentes en un momento determinado. Las vistas de entrenamiento se pueden utilizar para crear muchos conjuntos de entrenamiento diferentes, que pueden variar en el tiempo y en qué subconjunto de funciones se incluyen.
Crear una vista de entrenamiento es:

2. Conjuntos de entrenamiento. Se trata de una colección de características designadas durante una ventana de tiempo específica, a veces combinadas con etiquetas (en aprendizaje supervisado) que se utilizan para entrenar modelos. Es una simple llamada para recuperar un conjunto de entrenamiento con valores de características históricos predeterminados de la tienda de características.

Figura 2: Modelos de entrenamiento en Feature Store
La creación de un marco de datos Spark a partir de un conjunto de entrenamiento se ve así:

3. Servicio de funciones. Las funciones se ofrecen a los modelos directamente desde la tienda de funciones. Es muy sencillo recuperar el vector de características de una entidad como entrada a un modelo de predicciones.

Figura 3: Servicio de funciones en soluciones de AA basadas en Feature Store
Obtener las funciones más actualizadas se ve así:

Estos mecanismos permiten que las tiendas de características habiliten:
- Transformación de datos automatizada. Las tiendas de características administran las canalizaciones de datos que transforman los datos sin procesar en valores de características. Estos pueden ser pipelines programados que agregan petabytes de datos a la vez (como calcular los montos de gasto promedio de 30, 60 y 90 días de cada cliente de un gran minorista), o pipelines en tiempo real que se activan por eventos y actualizan los valores de las características. instantáneamente (como actualizar la suma total de los gastos de hoy para un cliente en particular cada vez que pasa su tarjeta de crédito).
- Servicio de funciones en tiempo real. Las tiendas de características sirven un solo vector de características compuesto por los valores de características más recientes para los modelos de aprendizaje automático. Por ejemplo, si una aplicación desea recomendar un producto en particular a un usuario, es posible que el modelo necesite saber la cantidad promedio que el usuario ha gastado en una categoría de gasto en particular, así como el tiempo total que pasó comprando en las últimas 48 horas. La tienda de características tendrá la valores más actualizados para esas métricas Inmediatamente disponible para el modelo, en lugar de tener que ejecutar la canalización de datos para calcularlos y poder ofrecer esas funciones en milisegundos.
- Registro de funciones. Un registro de características es una interfaz central para catalogar las definiciones de características dentro de una organización. Un registro de características contiene definiciones de características estandarizadas y metadatos asociados para actuar como una fuente única de información para una organización. Feature Store hace que la búsqueda a través de las características disponibles y las definiciones de características sea simple y directa. Expone las API y las IU al científico de datos para ver las características, las canalizaciones y los conjuntos de datos de entrenamiento disponibles actualmente que se están utilizando en modelos de producción o en desarrollo. Los científicos de datos pueden elegir las características necesarias para su caso de uso e incorporarlas en modelos sin ningún código adicional.
- Entrenamiento y reentrenamiento de modelos. Una tienda de características organiza las características más antiguas en una base de datos de series de tiempo para que cuando se entrenan los modelos, todos los ejemplos tengan características alineadas al mismo tiempo. Debido a que todos los valores históricos de las características se almacenan junto con sus marcas de tiempo, Feature Store puede generar conjuntos de datos de entrenamiento completos para las características y alinearlos correctamente con las etiquetas para el entrenamiento. A medida que se actualizan esas funciones, Feature Store puede generar conjuntos de datos de entrenamiento actualizados para el reentrenamiento de modelos exactamente de la misma manera.
- Monitoreo de modelos. Cuando todas las predicciones anteriores de los modelos se almacenan junto con las entradas al modelo en ese momento, monitorear el modelo es tan simple como ejecutar consultas SQL. Esto permite a los usuarios monitorear el rendimiento del modelo y realizar un seguimiento de cualquier variación de Característica, deriva de predicción del modelo y precisión del modelo (cuando las etiquetas están disponibles). Debido a que Feature Store mantiene actualizados todos los valores de las características y mantiene todos los valores históricos de manera constante en el tiempo, es fácil monitorear los modelos con Feature Store.
Beneficios de una tienda de características

Figura 4: Componentes de la arquitectura de Feature Store
- Productividad mejorada de la ciencia de datos. Las tiendas de características eliminan de la ecuación las tareas de datos mundanas, tediosas y que requieren mucho tiempo para que los científicos de datos puedan cambiar su enfoque de la plomería de datos memorísticos a la creación y experimentación de modelos.
- Precisión de modelo mejorada. Los almacenes de características permiten modelos más precisos al llevar la actualización y la coherencia de los datos a un nivel completamente nuevo. Al separar la canalización de datos del modelo de AA, las grandes funciones basadas en agregaciones que pueden tardar horas en calcularse se pueden recuperar inmediatamente cuando sea necesario. Esto le da a los modelos en tiempo real acceso a valores de características que no tendrían de otra manera. Al tener acceso a datos en tiempo real, los modelos pueden predecir con mayor precisión en función de lo que sucede en el mundo real, en lugar de quedarse estancados en los datos de ayer. Además, mantener características históricas en una serie temporal garantiza automáticamente un entrenamiento constante, lo que a menudo es difícil con los conjuntos de entrenamiento personalizados.
- Transparencia del modelo. Cuando un regulador está auditando las prácticas de una empresa que funcionan con modelos de ML, una tienda de características ofrece transparencia al linaje de las predicciones. Sabes qué características se incluyeron en el modelo. Sabes qué datos llenaron esas funciones en un conjunto de entrenamiento. Y en algunas tiendas de características, incluso puede volver al estado de la base de datos cuando se entrenó el modelo. A esto lo llamamos viaje en el tiempo.

Figura 5: Flujo de datos en una solución basada en Feature Store
Tipos de datos
Actualmente, todas las tiendas de características del mercado sirven dos tipos diferentes de datos por separado. Los datos «en línea» incluyen valores clave de transmisión que se actualizan en tiempo real. Los datos «sin conexión» incluyen grandes volúmenes de datos analíticos que a menudo se procesan en lotes. En las tiendas de características tradicionales, estos se procesan en canalizaciones de datos independientes.
- Canalizaciones de datos en tiempo real son necesarios para impulsar modelos de AA que se utilizan para reaccionar directamente a las interacciones del usuario final en tiempo real. En tales casos, la fuente de la característica debe estar conectada en tiempo real al almacén de características, ya sea mediante transmisión, inserción directa de la base de datos o operaciones de actualización. A medida que se procesan estas transacciones, generan nuevos valores de características justo a tiempo para una inferencia posterior que los lea. Este tipo de operación normalmente afecta a una pequeña cantidad de filas a la vez, pero tiene potencial para una simultaneidad muy alta. Este procesamiento de baja latencia y alta concurrencia suele ser característico de las bases de datos OLTP.
- Canalizaciones de datos por lotes ocurren periódicamente (típicamente una vez al día o semanalmente). Procesan grandes cantidades de datos de origen extrayendo, cargando, limpiando, agregando y curando datos en funciones utilizables. La transformación de grandes cantidades de datos generalmente requiere un procesamiento paralelo que se pueda escalar. Este procesamiento de datos de alto volumen que se encuentra en los motores de bases de datos de procesamiento masivo en paralelo se denomina generalmente OLAP.
Sin embargo, tener canales de datos separados para los dos tipos de datos tiene inconvenientes importantes, el más obvio de los cuales es tener que pagar y administrar dos motores de datos separados. Además, mover datos entre dos canalizaciones diferentes aumenta la latencia, ya que es difícil mantener sincronizadas dos canalizaciones separadas.
Hay otra forma. El uso de una base de datos combinada OLTP / OLAP le permite almacenar ambos tipos de datos en la misma plataforma, lo que:
- Disminuir la latencia entre las dos canalizaciones
- Elimina la necesidad de pagar y administrar dos motores de datos
- Simplifique la complejidad de mantener sincronizadas dos tuberías independientes, lo que hace que los datos estén altamente disponibles
Pocas bases de datos admiten ambos tipos de cargas de trabajo y también proporcionan escalabilidad horizontal, pero un OLTP compatible con ACID y El motor OLAP que puede escalar de forma independiente entregaría sin problemas inferencias en tiempo real y por lotes directamente en Feature Store.
Ejemplo: motor de recomendaciones
Para ayudar a conceptualizar cómo una tienda de características puede realmente revolucionar el flujo de trabajo de la ciencia de datos, tomemos el ejemplo de una empresa de comercio electrónico. Esta empresa desea crear un modelo de aprendizaje automático que proporcione a los clientes recomendaciones de artículos personalizadas.
Para sugerir qué producto debería mirar un cliente a continuación, el modelo debe recibir datos que puedan ayudarlo a predecir el comportamiento de compra del cliente. Esto podría incluir el último elemento que el cliente miró en el sitio, una función en línea, que vendría de una base de datos operativa o transaccional como MongoDB, DB2 u Oracle. Otra entrada para el modelo podría ser el gasto mensual promedio de un cliente, una función precalculada fuera de línea o por lotes, que vendría de un almacén de datos como Redshift o Snowflake.

Figura 6: Modelo de datos del motor de recomendaciones
Sin una tienda de características, un ingeniero de datos tiene que crear manualmente canalizaciones ETL a medida para alimentar datos al modelo ML. Tienen que escribir el código que mueve los datos desde el almacén a los conjuntos de entrenamiento, desde la base de datos a la implementación del modelo de cuadernos de Jupyter, y diseñar manualmente los datos en funciones utilizables.

Figura 7: Canalizaciones ETL tradicionales en modelos ML
Esto no es fácil de escalar, ya que se debe crear una nueva tubería ETL para cada fuente de datos para cada modelo diferente. Aunque esto funciona, las canalizaciones no siempre se usan de manera consistente y escalar una operación de ML de esta manera requiere mucho tiempo.
Con una tienda de características, los ingenieros de datos solo tienen que construir una canalización de datos desde cada fuente de datos hasta la tienda de características, y tantos modelos de aprendizaje automático como sean necesarios pueden extraer sus características de un lugar central. Esto significa que será la misma cantidad de trabajo en cuanto a arquitectura para construir dos modelos de aprendizaje automático que veinte, lo que hace que la canalización del modelo sea increíblemente escalable.

Figura 8: canalización ETL en modelos ML basados en Feature Store
Para esta empresa, crear una tienda de características es tan simple como:

Tiendas de funciones en línea / fuera de línea
Como se explicó anteriormente, la mayoría de las tiendas de características tienen dos bases de datos separadas para características en línea y fuera de línea. En este caso, el usuario tiene que administrar manualmente estos dos tipos de funciones, que pueden volverse inconsistentes. Hay una gran cantidad de tiempo y energía dedicados a mantener sincronizadas dos bases de datos diferentes, lo que se puede deshacer tan pronto como una se interrumpa por alguna razón u otra.

Figura 9: Bases de datos de Feature Store en línea y fuera de línea
La paridad de datos es mucho más fácil de lograr cuando las funciones en línea y fuera de línea se almacenan en un solo sistema. Vincular la tienda de características a una base de datos híbrida compatible con ACID hace que sea imposible tener una discrepancia entre las dos tiendas; si se introduce algo nuevo, los activadores de la base de datos garantizan la coherencia de los valores de las funciones en vivo en línea y los historiales de las funciones fuera de línea. Esto es más eficiente, requiere menos código y es menos propenso a problemas de coherencia.

Figura 10: Base de datos única para casos de uso en línea y fuera de línea de Feature Store
Tiendas de características en el mercado
Si bien hay varias empresas de tecnología que han creado sus propias tiendas de funciones para uso exclusivo (incluidas Uber, Airbnb y Netflix), también hay algunas opciones de código abierto en el mercado para empresas que desean utilizar una tienda de funciones pero no quiero construirlo ellos mismos. Feast, Splice Machine y Hopsworks son las tres principales soluciones de código abierto.
Feast es una tienda de características de código abierto con una comunidad muy activa. Feast tiene una excelente documentación y ofrece un buen soporte de SDK para Python, línea de comandos, Go, Java y algunos otros, y actualmente está agregando integraciones con Kubeflow. Feast agregó recientemente compatibilidad con Spark y Kubernetes para soluciones más escalables. Actualmente, la única tienda en línea de Feast es Redis.
La mayor debilidad de Feast es que no ofrece una tienda fuera de línea, aunque planean hacerlo pronto. Esto significa que no automatizará la entrada de valores históricos de características, que es una gran parte de lo que hace una tienda de características. Si usara Feast ahora mismo, necesitaría proporcionar los valores históricos de las características usted mismo, y sería su responsabilidad garantizar el linaje completo de sus datos.
Hopsworks de Logical Clocks es otra opción de código abierto. Su tienda de funciones es un componente modular de la oferta de Logical Clocks, por lo que no está obligado a utilizar todo el sistema. También tienen una interfaz de usuario completamente unificada que cubre MLOps de un extremo a otro. La interfaz de usuario de Feature Store es bastante sofisticada, lo que permite al usuario buscar funciones, grupos de funciones, conjuntos de entrenamiento, etc. Puede vincular funciones y grupos a las canalizaciones que los crearon, utilizando Apache Airflow para la integración de canalizaciones. La seguridad también está integrada en el sistema.
Hopsworks está trabajando para crear unidad en toda la tubería. Actualmente, los usuarios necesitan escribir scripts fuera del entorno de trabajo para implementar modelos y crear canalizaciones. Además, Hopsworks depende de sistemas externos para su tienda, ya que su tienda de características fuera de línea necesita Hive.
Splice Machine Feature Store contiene toda la funcionalidad de las otras tiendas, con una diferencia clave: su función de un solo motor almacena datos en línea / fuera de línea en el mismo lugar, lo que le permite ser compatible con ACID y singularmente consistente. Incluso después de que Feast agregue una tienda fuera de línea, no pueden garantizar la coherencia entre esas dos tiendas, porque son motores distintos. Splice Machine ofrece la única tienda de funciones que puede garantizar al 100% que sus datos en línea y fuera de línea serán consistentes, porque es la única que contiene todos los datos en la misma tienda.
Conclusión
En la gran mayoría de los silos de ciencia de datos, los científicos de datos no pueden concentrarse en lo que hacen mejor. Pasan la mayor parte de su tiempo y energía construyendo arquitectura ML y preparando datos para modelos. Al proporcionar la arquitectura necesaria para la implementación sencilla del modelo y optimizar el proceso de características, la creación de un almacén de características sobre una base de datos combinada OLTP / OLAP puede aumentar la productividad de la ciencia de datos cien veces.
Sobre el Autor
 Monte Zweben es cofundador y director ejecutivo de Splice Machine, una base de datos SQL escalable que facilita la ciencia de datos y el aprendizaje automático. Veterano de la industria de la tecnología, Monte pasó sus inicios en el Centro de Investigación Ames de la NASA como subdirector de la rama de inteligencia artificial, donde ganó el prestigioso Premio de la Ley Espacial por su trabajo en el programa del Transbordador Espacial. Monte luego hizo la transición al mundo empresarial, fundando las startups líderes en la industria Blue Martini y Red Pepper Software. Monte ha publicado artículos en Harvard Business Review, varias revistas de informática y actas de congresos. Fue presidente de Rocket Fuel Inc. y es miembro del consejo asesor del decano de la Facultad de Ciencias de la Computación de la Universidad Carnegie Mellon.
Monte Zweben es cofundador y director ejecutivo de Splice Machine, una base de datos SQL escalable que facilita la ciencia de datos y el aprendizaje automático. Veterano de la industria de la tecnología, Monte pasó sus inicios en el Centro de Investigación Ames de la NASA como subdirector de la rama de inteligencia artificial, donde ganó el prestigioso Premio de la Ley Espacial por su trabajo en el programa del Transbordador Espacial. Monte luego hizo la transición al mundo empresarial, fundando las startups líderes en la industria Blue Martini y Red Pepper Software. Monte ha publicado artículos en Harvard Business Review, varias revistas de informática y actas de congresos. Fue presidente de Rocket Fuel Inc. y es miembro del consejo asesor del decano de la Facultad de Ciencias de la Computación de la Universidad Carnegie Mellon.
