

Última actualización el 4 de octubre de 2022
Ya nos hemos familiarizado con la teoría detrás del modelo de Transformador y su mecanismo de atención, y ya hemos comenzado nuestro viaje de implementación de un modelo completo al ver cómo implementar la atención del producto de puntos escalados. Ahora avanzaremos un paso más en nuestro viaje al encapsular la atención del producto de puntos escalados en un mecanismo de atención de múltiples cabezas, del cual es un componente central. Nuestro objetivo final sigue siendo la aplicación del modelo completo al procesamiento del lenguaje natural (NLP).
En este tutorial, descubrirá cómo implementar la atención multicabezal desde cero en TensorFlow y Keras.
Después de completar este tutorial, sabrás:
- Las capas que forman parte del mecanismo de atención multicabezal.
- Cómo implementar el mecanismo de atención multicabezal desde cero.
Empecemos.
Cómo implementar la atención de múltiples cabezas desde cero en TensorFlow y Keras
Foto de Everaldo Coelho, algunos derechos reservados.
Descripción general del tutorial
Este tutorial se divide en tres partes; están:
- Resumen de la arquitectura del transformador
- La atención de varios cabezales del transformador
- Implementando la atención de múltiples cabezas desde cero
- Probando el código
requisitos previos
Para este tutorial, asumimos que ya está familiarizado con:
- El concepto de atención.
- El mecanismo de atención del transformador.
- El modelo del transformador
- La atención del producto punto escalado
Resumen de la arquitectura del transformador
Recuerde haber visto que la arquitectura de Transformer sigue una estructura de codificador-decodificador: el codificador, en el lado izquierdo, tiene la tarea de mapear una secuencia de entrada a una secuencia de representaciones continuas; el decodificador, en el lado derecho, recibe la salida del codificador junto con la salida del decodificador en el paso de tiempo anterior, para generar una secuencia de salida.
La estructura del codificador-decodificador de la arquitectura del transformador
Tomado de “La atención es todo lo que necesitas“
Al generar una secuencia de salida, el Transformador no se basa en recurrencias ni circunvoluciones.
Habíamos visto que la parte del decodificador del Transformador comparte muchas similitudes en su arquitectura con el codificador. Uno de los mecanismos principales que comparten tanto el codificador como el decodificador es el atención de múltiples cabezas mecanismo.
La atención de varios cabezales del transformador
Cada bloque de atención de múltiples cabezas se compone de cuatro niveles consecutivos:
- En el primer nivel, tres capas lineales (densas) que reciben cada una las consultas, claves o valores.
- En el segundo nivel, una función de atención de producto punto a escala. Se repiten las operaciones realizadas tanto en el primer como en el segundo nivel. h veces y realizadas en paralelo, según el número de cabezas que componen el bloque de atención multicabezal.
- En el tercer nivel, una operación de concatenación que une las salidas de los diferentes cabezales.
- En el cuarto nivel, una capa final lineal (densa) que produce la salida.
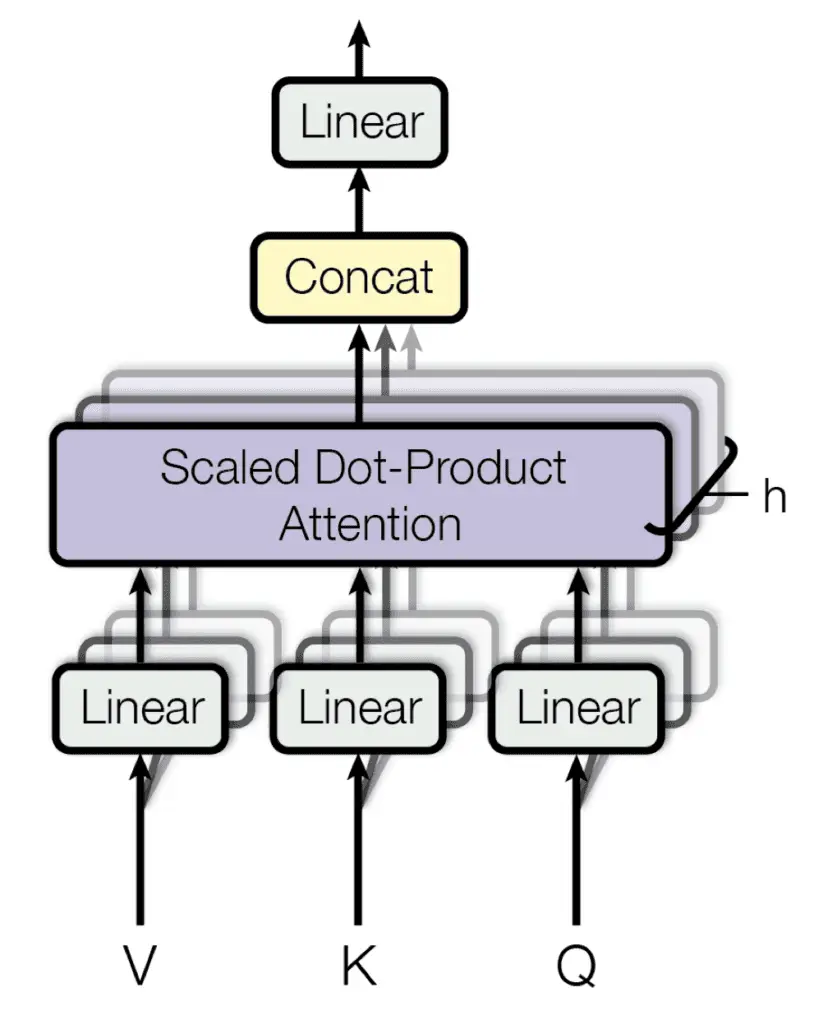
Atención de múltiples cabezas
Tomado de “La atención es todo lo que necesitas“
Recuerde también los componentes importantes que servirán como bloques de construcción para nuestra implementación de la atención de múltiples cabezas:
- los consultas, llaves y valores: Estas son las entradas para cada bloque de atención de varios cabezales. En la etapa del codificador, cada uno lleva la misma secuencia de entrada después de que esta haya sido integrada y aumentada con información posicional. De manera similar, en el lado del decodificador, las consultas, claves y valores introducidos en el primer bloque de atención representan la misma secuencia de destino, después de que esto también se haya incorporado y aumentado con información posicional. El segundo bloque de atención del decodificador recibe la salida del codificador en forma de claves y valores, y la salida normalizada del primer bloque de atención del decodificador como consultas. La dimensionalidad de las consultas y claves se indica con $d_k$, mientras que la dimensionalidad de los valores se indica con $d_v$.
- los matrices de proyección: Cuando se aplican a las consultas, claves y valores, estas matrices de proyección generan diferentes representaciones subespaciales de cada uno. Cada atención cabeza luego trabaja en una de estas versiones proyectadas de las consultas, claves y valores. También se aplica una matriz de proyección adicional a la salida del bloque de atención de múltiples cabezas, después de que las salidas de cada cabeza individual se hayan concatenado juntas. Las matrices de proyección se aprenden durante el entrenamiento.
Veamos ahora cómo implementar la atención multicabezal desde cero en TensorFlow y Keras.
Implementando la atención de múltiples cabezas desde cero
Comencemos por crear la clase, MultiHeadAttentionque hereda de la Layer clase base en Keras e inicialice varios atributos de instancia con los que trabajaremos (las descripciones de los atributos se pueden encontrar en los comentarios):
class MultiHeadAttention(Layer):
def __init__(self, h, d_k, d_v, d_model, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.attention = DotProductAttention() # Scaled dot product attention
self.heads = h # Number of attention heads to use
self.d_k = d_k # Dimensionality of the linearly projected queries and keys
self.d_v = d_v # Dimensionality of the linearly projected values
self.W_q = Dense(d_k) # Learned projection matrix for the queries
self.W_k = Dense(d_k) # Learned projection matrix for the keys
self.W_v = Dense(d_v) # Learned projection matrix for the values
self.W_o = Dense(d_model) # Learned projection matrix for the multi-head output
…
Aquí tenga en cuenta que también hemos creado una instancia de la DotProductAttention clase que habíamos implementado anteriormente, y asignó su salida a la variable attention. Recuerde que habíamos implementado el DotProductAttention clase de la siguiente manera:
from tensorflow import matmul, math, cast, float32
from tensorflow.keras.layers import Layer
from keras.backend import softmax
# Implementing the Scaled-Dot Product Attention
class DotProductAttention(Layer):
def __init__(self, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
def call(self, queries, keys, values, d_k, mask=None):
# Scoring the queries against the keys after transposing the latter, and scaling
scores = matmul(queries, keys, transpose_b=True) / math.sqrt(cast(d_k, float32))
# Apply mask to the attention scores
if mask is not None:
scores += -1e9 * mask
# Computing the weights by a softmax operation
weights = softmax(scores)
# Computing the attention by a weighted sum of the value vectors
return matmul(weights, values)
A continuación, remodelaremos el proyectado linealmente consultas, claves y valores de tal manera que permita calcular los cabezales de atención en paralelo.
Las consultas, claves y valores se introducirán como entrada en el bloque de atención de varios cabezales que tiene la forma de (tamaño del lote, longitud de la secuencia, dimensionalidad del modelo), donde el tamaño del lote es un hiperparámetro del proceso de entrenamiento, el longitud de la secuencia define la longitud máxima de las frases de entrada/salida, y la dimensionalidad del modelo es la dimensionalidad de los resultados producidos por todas las subcapas del modelo. Luego se pasan a través de la capa densa respectiva para ser proyectados linealmente a una forma de (tamaño del lote, longitud de la secuencia, consultas/llaves/valores dimensionalidad).
Las consultas, claves y valores proyectados linealmente se reorganizarán en (tamaño del lote, número de cabezas, longitud de la secuencia, profundidad), transformándolos primero en (tamaño del lote, longitud de la secuencia, número de cabezas, profundidad) y luego transponiendo la segunda y tercera dimensión. Para ello, crearemos el método de clase, reshape_tensorcomo sigue:
def reshape_tensor(self, x, heads, flag):
if flag:
# Tensor shape after reshaping and transposing: (batch_size, heads, seq_length, -1)
x = reshape(x, shape=(shape(x)[0], shape(x)[1], heads, -1))
x = transpose(x, perm=(0, 2, 1, 3))
else:
# Reverting the reshaping and transposing operations: (batch_size, seq_length, d_model)
x = transpose(x, perm=(0, 2, 1, 3))
x = reshape(x, shape=(shape(x)[0], shape(x)[1], -1))
return x
los reshape_tensor El método recibe las consultas, claves o valores proyectados linealmente como entrada (mientras establece la bandera en True) para ser reorganizado como se explicó anteriormente. Una vez que se ha generado la salida de atención de múltiples cabezas, también se alimenta a la misma función (esta vez configurando la bandera en False) para realizar una operación inversa, concatenando efectivamente los resultados de todas las cabezas juntas.
Por lo tanto, el siguiente paso es alimentar las consultas, claves y valores proyectados linealmente en el reshape_tensor método que se va a reorganizar y, a continuación, proceda a introducirlos en la función de atención del producto punto escalado. Para hacerlo, crearemos otro método de clase, callcomo sigue:
def call(self, queries, keys, values, mask=None):
# Rearrange the queries to be able to compute all heads in parallel
q_reshaped = self.reshape_tensor(self.W_q(queries), self.heads, True)
# Resulting tensor shape: (batch_size, heads, input_seq_length, -1)
# Rearrange the keys to be able to compute all heads in parallel
k_reshaped = self.reshape_tensor(self.W_k(keys), self.heads, True)
# Resulting tensor shape: (batch_size, heads, input_seq_length, -1)
# Rearrange the values to be able to compute all heads in parallel
v_reshaped = self.reshape_tensor(self.W_v(values), self.heads, True)
# Resulting tensor shape: (batch_size, heads, input_seq_length, -1)
# Compute the multi-head attention output using the reshaped queries, keys and values
o_reshaped = self.attention(q_reshaped, k_reshaped, v_reshaped, self.d_k, mask)
# Resulting tensor shape: (batch_size, heads, input_seq_length, -1)
…
Tenga en cuenta que el reshape_tensor El método también puede recibir una máscara (cuyo valor predeterminado es None) como entrada, además de las consultas, claves y valores.
Recuerde que el modelo Transformador introduce un máscara de anticipación para evitar que el decodificador preste atención a las palabras sucesivas, de modo que la predicción de una palabra en particular solo puede depender de los resultados conocidos de las palabras que le preceden. Además, dado que las incrustaciones de palabras se rellenan con ceros hasta una longitud de secuencia específica, un máscara de relleno también debe introducirse para evitar que los valores cero se procesen junto con la entrada. Estas máscaras de anticipación y de relleno se pueden pasar a la atención del producto de puntos escalados a través del mask argumento.
Una vez que hemos generado la salida de atención de múltiples cabezas de todas las cabezas de atención, los pasos finales son volver a concatenar todas las salidas en un tensor de forma, (tamaño del lote, longitud de la secuencia, valores dimensionalidad), y pasando el resultado a través de una última capa densa. Para este propósito, agregaremos las próximas dos líneas de código al call método.
…
# Rearrange back the output into concatenated form
output = self.reshape_tensor(o_reshaped, self.heads, False)
# Resulting tensor shape: (batch_size, input_seq_length, d_v)
# Apply one final linear projection to the output to generate the multi-head attention
# Resulting tensor shape: (batch_size, input_seq_length, d_model)
return self.W_o(output)
Poniendo todo junto, tenemos la siguiente implementación de la atención de múltiples cabezas:
from tensorflow import math, matmul, reshape, shape, transpose, cast, float32
from tensorflow.keras.layers import Dense, Layer
from keras.backend import softmax
# Implementing the Scaled-Dot Product Attention
class DotProductAttention(Layer):
def __init__(self, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
def call(self, queries, keys, values, d_k, mask=None):
# Scoring the queries against the keys after transposing the latter, and scaling
scores = matmul(queries, keys, transpose_b=True) / math.sqrt(cast(d_k, float32))
# Apply mask to the attention scores
if mask is not None:
scores += -1e9 * mask
# Computing the weights by a softmax operation
weights = softmax(scores)
# Computing the attention by a weighted sum of the value vectors
return matmul(weights, values)
# Implementing the Multi-Head Attention
class MultiHeadAttention(Layer):
def __init__(self, h, d_k, d_v, d_model, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.attention = DotProductAttention() # Scaled dot product attention
self.heads = h # Number of attention heads to use
self.d_k = d_k # Dimensionality of the linearly projected queries and keys
self.d_v = d_v # Dimensionality of the linearly projected values
self.d_model = d_model # Dimensionality of the model
self.W_q = Dense(d_k) # Learned projection matrix for the queries
self.W_k = Dense(d_k) # Learned projection matrix for the keys
self.W_v = Dense(d_v) # Learned projection matrix for the values
self.W_o = Dense(d_model) # Learned projection matrix for the multi-head output
def reshape_tensor(self, x, heads, flag):
if flag:
# Tensor shape after reshaping and transposing: (batch_size, heads, seq_length, -1)
x = reshape(x, shape=(shape(x)[0], shape(x)[1], heads, -1))
x = transpose(x, perm=(0, 2, 1, 3))
else:
# Reverting the reshaping and transposing operations: (batch_size, seq_length, d_k)
x = transpose(x, perm=(0, 2, 1, 3))
x = reshape(x, shape=(shape(x)[0], shape(x)[1], self.d_k))
return x
def call(self, queries, keys, values, mask=None):
# Rearrange the queries to be able to compute all heads in parallel
q_reshaped = self.reshape_tensor(self.W_q(queries), self.heads, True)
# Resulting tensor shape: (batch_size, heads, input_seq_length, -1)
# Rearrange the keys to be able to compute all heads in parallel
k_reshaped = self.reshape_tensor(self.W_k(keys), self.heads, True)
# Resulting tensor shape: (batch_size, heads, input_seq_length, -1)
# Rearrange the values to be able to compute all heads in parallel
v_reshaped = self.reshape_tensor(self.W_v(values), self.heads, True)
# Resulting tensor shape: (batch_size, heads, input_seq_length, -1)
# Compute the multi-head attention output using the reshaped queries, keys and values
o_reshaped = self.attention(q_reshaped, k_reshaped, v_reshaped, self.d_k, mask)
# Resulting tensor shape: (batch_size, heads, input_seq_length, -1)
# Rearrange back the output into concatenated form
output = self.reshape_tensor(o_reshaped, self.heads, False)
# Resulting tensor shape: (batch_size, input_seq_length, d_v)
# Apply one final linear projection to the output to generate the multi-head attention
# Resulting tensor shape: (batch_size, input_seq_length, d_model)
return self.W_o(output)
Probando el código
Trabajaremos con los valores de los parámetros especificados en el artículo Attention Is All You Need, de Vaswani et al. (2017):
h = 8 # Number of self-attention heads
d_k = 64 # Dimensionality of the linearly projected queries and keys
d_v = 64 # Dimensionality of the linearly projected values
d_model = 512 # Dimensionality of the model sub-layers’ outputs
batch_size = 64 # Batch size from the training process
…
En cuanto a la longitud de la secuencia y las consultas, claves y valores, trabajaremos con datos ficticios por el momento hasta que lleguemos a la etapa de entrenamiento del modelo completo de Transformer en un tutorial separado, momento en el cual usaremos datos reales. oraciones:
…
input_seq_length = 5 # Maximum length of the input sequence
queries = random.random((batch_size, input_seq_length, d_k))
keys = random.random((batch_size, input_seq_length, d_k))
values = random.random((batch_size, input_seq_length, d_v))
…
En el modelo completo de Transformer, los valores para la longitud de la secuencia y las consultas, claves y valores se obtendrán mediante un proceso de tokenización e incrustación de palabras. Cubriremos esto en un tutorial separado.
Volviendo a nuestro procedimiento de prueba, el siguiente paso es crear una nueva instancia del MultiHeadAttention clase, asignando su salida a la multihead_attention variable:
…
multihead_attention = MultiHeadAttention(h, d_k, d_v, d_model)
…
Desde el MultiHeadAttention clase hereda de la Layer clase base, la call() método del primero será automáticamente invocado por la magia __call()__ método de este último. El paso final es pasar los argumentos de entrada e imprimir el resultado:
…
print(multihead_attention(queries, keys, values))
Unir todo produce la siguiente lista de códigos:
from numpy import random
input_seq_length = 5 # Maximum length of the input sequence
h = 8 # Number of self-attention heads
d_k = 64 # Dimensionality of the linearly projected queries and keys
d_v = 64 # Dimensionality of the linearly projected values
d_model = 512 # Dimensionality of the model sub-layers’ outputs
batch_size = 64 # Batch size from the training process
queries = random.random((batch_size, input_seq_length, d_k))
keys = random.random((batch_size, input_seq_length, d_k))
values = random.random((batch_size, input_seq_length, d_v))
multihead_attention = MultiHeadAttention(h, d_k, d_v, d_model)
print(multihead_attention(queries, keys, values))
Ejecutar este código produce una salida de forma, (tamaño del lote, longitud de la secuencia, dimensionalidad del modelo). Tenga en cuenta que probablemente verá un resultado diferente debido a la inicialización aleatoria de las consultas, claves y valores, y los valores de los parámetros de las capas densas.
tf.Tensor(
[[[-0.02185373 0.32784638 0.15958631 … -0.0353895 0.6645204
-0.2588266 ]
[-0.02272229 0.32292002 0.16208754 … -0.03644213 0.66478664
-0.26139447]
[-0.01876744 0.32900316 0.16190802 … -0.03548665 0.6645842
-0.26155376]
[-0.02193783 0.32687354 0.15801215 … -0.03232524 0.6642926
-0.25795174]
[-0.02224652 0.32437912 0.1596448 … -0.0340827 0.6617497
-0.26065096]]
…
[[ 0.05414441 0.27019292 0.1845745 … 0.0809482 0.63738805
-0.34231138]
[ 0.05546578 0.27191412 0.18483458 … 0.08379208 0.6366671
-0.34372014]
[ 0.05190979 0.27185103 0.18378328 … 0.08341806 0.63851804
-0.3422392 ]
[ 0.05437043 0.27318984 0.18792395 … 0.08043509 0.6391771
-0.34357914]
[ 0.05406848 0.27073097 0.18579456 … 0.08388947 0.6376929
-0.34230167]]], shape=(64, 5, 512), dtype=float32)
Otras lecturas
Esta sección proporciona más recursos sobre el tema si desea profundizar más.
Libros
- Aprendizaje profundo avanzado con Python, 2019.
- Transformadores para el procesamiento del lenguaje natural, 2021.
Documentos
- La atención es todo lo que necesitas, 2017.
Resumen
En este tutorial, descubrió cómo implementar la atención de múltiples cabezas desde cero en TensorFlow y Keras.
Específicamente, aprendiste:
- Las capas que forman parte del mecanismo de atención multicabezal.
- Cómo implementar el mecanismo de atención multicabezal desde cero.
¿Tiene usted alguna pregunta?
Haga sus preguntas en los comentarios a continuación y haré todo lo posible para responder.
La publicación Cómo implementar la atención de múltiples cabezas desde cero en TensorFlow y Keras apareció primero en Machine Learning Mastery.