
Shuffle Sort Merge Join, como su nombre indica, implica una operación de clasificación. La unión de la clasificación barajada tiene 3 fases.
Fase de barajado – ambos conjuntos de datos están mezclados
Fase de clasificación – los registros están ordenados por clave en ambos lados
Fase de fusión – iterar sobre ambos lados y unirse en base a la clave de unión.
La unión de ordenación aleatoria es preferible cuando ambos conjuntos de datos son grandes y no caben en la memoria, con o sin aleación.
Ejemplo
chispa.sql.unirse a.preferSortMergeJoin por defecto se establece como verdadero, ya que esto se prefiere cuando los conjuntos de datos son grandes en ambos lados.
Spark elegirá «Broadcast Hash Join» si un conjunto de datos es pequeño. En nuestro caso ambos conjuntos de datos son pequeños, así que para forzar una unión de clasificación estamos estableciendo
chispa.sql.autoBroadcastJoinThreshold a -1 y esto deshabilitará la transmisión de Hash Join.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
scala> chispa.conf.consigue(«chispa.sql.join.preferSortMergeJoin») res1: Cuerda = verdadero scala> chispa.conf.consigue(«spark.sql.autoBroadcastJoinThreshold») res2: Cuerda = –1 scala> val datos1 = Seq(10, 20, 20, 30, 40, 10, 40, 20, 20, 20, 20, 50) datos1: Seq[[Int] = Lista(10, 20, 20, 30, 40, 10, 40, 20, 20, 20, 20, 50) scala> val df1 = datos1.toDF(«id1») df1: org.apache.chispa.sql.DataFrame = [[id1: int] scala> val datos2 = Seq(30, 20, 40, 50) datos2: Seq[[Int] = Lista(30, 20, 40, 50) scala> val df2 = datos2.toDF(«id2») df2: org.apache.chispa.sql.DataFrame = [[id2: int] scala> val dfJoined = df1.unirse a(df2, $«id1» === $«id2») dfJoined: org.apache.chispa.sql.DataFrame = [[id1: int, id2: int] |
Cuando vemos el plan que se ejecutará, podemos ver que se utiliza SortMergeJoin.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
scala> dfJoined.queryExecution.executedPlan res3: org.apache.chispa.sql.ejecución.SparkPlan = *(3) SortMergeJoin [[id1#3], [id2#8], Interior :– *(1) Ordenar [[id1#3 ASC NULOS PRIMERO], falso, 0 : +– Intercambio hashpartitioning(id1#3, 200) : +– LocalTableScan [[id1#3] +– *(2) Ordenar [[id2#8 ASC NULOS PRIMERO], falso, 0 +– Intercambio hashpartitioning(id2#8, 200) +– LocalTableScan [[id2#8] scala> dfJoined.mostrar +—–+—–+ |id1|id2| +—–+—–+ | 20| 20| | 20| 20| | 20| 20| | 20| 20| | 20| 20| | 20| 20| | 40| 40| | 40| 40| | 50| 50| | 30| 30| +—–+—–+ |
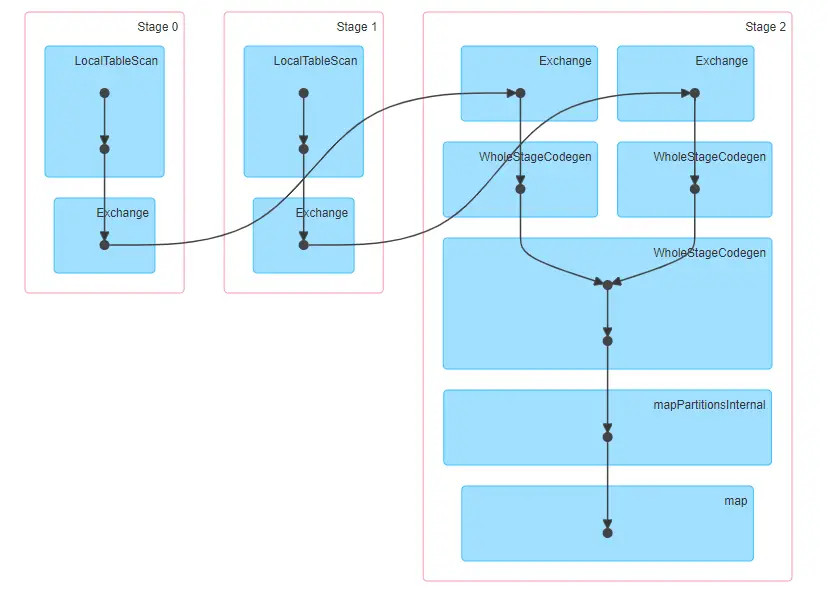
Las etapas involucradas en la fusión de la mezcla se unen
Como podemos ver a continuación, se necesita una barajadura con Shuffle Hash Join. El primer conjunto de datos se lee en la Etapa 0 y el segundo conjunto de datos se lee en la Etapa 1. La etapa 2 de abajo representa la barajadura.
Dentro de la Etapa 2 los registros se clasifican por clave y luego se fusionan para producir la salida.
Funcionamiento interno de Shuffle Sort Merge Join
Hay 3 fases en una unión de clasificación: fase de barajar, fase de clasificación y fase de fusión.
Fase de barajado
Los datos de ambos conjuntos de datos se leen y se mezclan. Después de la operación de barajado, los registros con las mismas claves de ambos conjuntos de datos terminarán en la misma partición después del barajado. Tenga en cuenta que el conjunto de datos completo no se emite con esta unión. Esto significa que el conjunto de datos de cada partición tendrá un tamaño manejable después de la barajadura.
Fase de clasificación
Los registros de ambos lados están ordenados por clave. Hashing y bucketing no están involucrados en esta unión.
Fase de fusión
La unión se realiza mediante la iteración sobre los registros del conjunto de datos ordenados. Desde que se clasifica el conjunto de datos, la operación de fusión o unión se detiene para un elemento tan pronto como se encuentra un desajuste clave. Así que un intento de unión no se realiza en todas las claves.
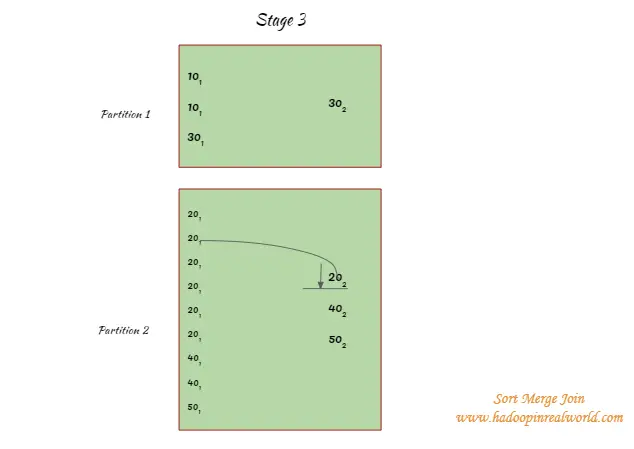
Por ejemplo, en la partición 2 cuando se intenta que las llaves coincidan con el 201 los registros se iteran a través del otro lado hasta el 402 se alcanza a medida que se clasifican los registros no hay necesidad de iterar a través de todos los registros del otro lado.
¿Cuándo funciona el sistema de fusión barajada?
- Funciona sólo en las uniones equi
- Trabaja en todos los tipos de unión
- Funciona en grandes conjuntos de datos
- Tanto el barajar y ordenar las llaves están involucrados en esta unión.
¿Cuando la unión de la clasificación barajada no funciona?
- No funciona en las uniones no equicionales.
- Tanto la barajadura como la clasificación son operaciones costosas. Use esta unión cuando no sea posible una transmisión de hachís y las uniones de hachís barajadas.
¿Interesado en aprender acerca de Broadcast Hash Únete a Spark? – Haz clic aquí.