
El Cartesian Product Join (también conocido como Shuffle-and-Replication Nested Loop) funciona de forma muy similar a un Broadcast Nested Loop join, excepto que el conjunto de datos no se transmite.
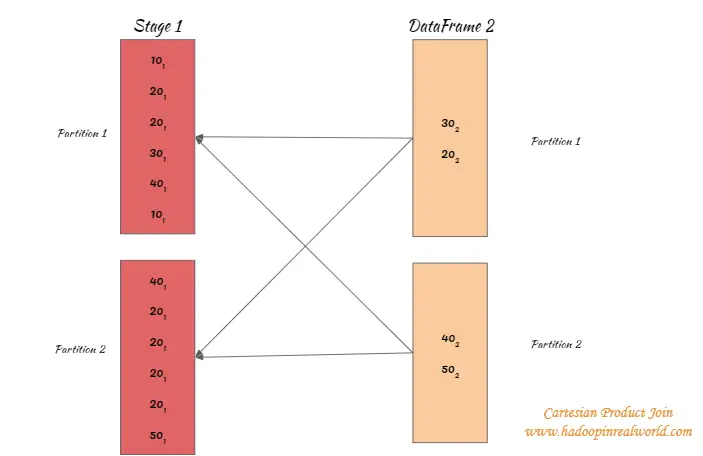
Barajar y replicar no significa una «verdadera» barajada, es decir, los registros con las mismas claves se envían a la misma partición. En su lugar, toda la partición del conjunto de datos se envía o se replica a todas las particiones para una unión completa cruzada o de bucle anidado.
¿Quiere que le enviemos una guía definitiva de 47 páginas sobre los algoritmos de join de Spark? ===>
Ejemplo
Estamos configurando
chispa.sql.autoBroadcastJoinThreshold a -1 para desactivar la difusión.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
scala> chispa.conf.obtener(«spark.sql.join.preferSortMergeJoin») res1: Cadena = true scala> chispa.conf.obtener(«spark.sql.autoBroadcastJoinThreshold») res2: Cadena = –1 scala> val datos1 = Seq(10, 20, 20, 30, 40, 10, 40, 20, 20, 20, 20, 50) datos1: Seq[[Int] = Lista(10, 20, 20, 30, 40, 10, 40, 20, 20, 20, 20, 50) scala> val df1 = datos1.toDF(«id1») df1: org.apache.chispa.sql.DataFrame = [[id1: int] scala> val datos2 = Seq(30, 20, 40, 50) datos2: Seq[[Int] = Lista(30, 20, 40, 50) scala> val df2 = datos2.toDF(«id2») df2: org.apache.chispa.sql.DataFrame = [[id2: int] |
Tenga en cuenta que aquí estamos intentando realizar una operación de unión no equitativa.
|
scala> val dfJoined = df1.únase a(df2, $«id1» >= $«id2») dfJoined: org.apache.chispa.sql.DataFrame = [[id1: int, id2: int] |
Cuando vemos el plan que se ejecutará, podemos ver que se utiliza CartesianProduct.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
scala> dfJoined.queryExecution.plan ejecutado res3: org.apache.chispa.sql.ejecución.SparkPlan = Producto cartesiano (id1#3 >= id2#8) :– LocalTableScan [[id1#3] +– LocalTableScan [[id2#8] scala> dfJoined.mostrar +—–+—–+ |id1|id2| +—–+—–+ | 20| 20| | 20| 20| | 30| 30| | 30| 20| | 40| 30| | 40| 20| | 40| 40| | 40| 30| | 40| 20| | 40| 40| | 20| 20| | 20| 20| | 20| 20| | 20| 20| | 50| 30| | 50| 20| | 50| 40| | 50| 50| +—–+—–+ |
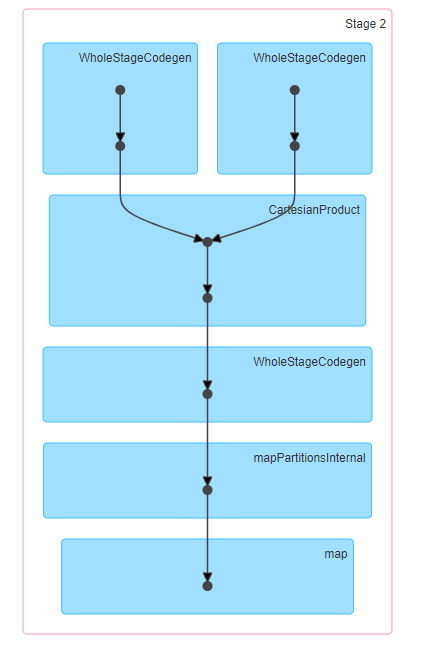
Etapas de la unión del producto cartesiano
Esta unión se ejecuta en una sola etapa. Aunque esta unión también se denomina barajar y replicar, no significa una «verdadera» barajada, ya que los registros con las mismas claves se envían a la misma partición. En su lugar, toda la partición del conjunto de datos es enviada o replicada a todas las particiones para una unión completa cruzada o de bucle anidado.
Funcionamiento interno de un producto cartesiano Join
- Se leen ambos conjuntos de datos. Todas las particiones de uno de los conjuntos de datos se envían a todas las particiones del otro conjunto de datos.
- Una vez que las particiones de ambos conjuntos de datos están disponibles en un lado, se realiza una unión de bucle anidado.
- Si hay N registros en un conjunto de datos y M registros en el otro conjunto de datos, se realiza un bucle anidado en N * M registros.
¿Cuándo funciona la unión de productos cartesianos?
- Funciona tanto en uniones equis como no equis
- Funciona sólo en uniones equis internas
¿Cuándo no funciona la unión de productos cartesianos?
- No funciona en uniones no internas
- Este es un algoritmo de unión muy caro. Excepto la carga en la red y las particiones se mueven a través de la red.
- Alta posibilidad de excepción por falta de memoria.
¿Interesado en aprender sobre Shuffle Sort Merge join en Spark? – Haga clic aquí.