
La emisión de Hash Join en Spark funciona transmitiendo el pequeño conjunto de datos a todos los ejecutores y una vez que los datos son emitidos se realiza una unión de hash estándar en todos los ejecutores. El Broadcast Hash Join se realiza en 2 fases.
Fase de emisión – se transmite un pequeño conjunto de datos a todos los ejecutores
Fase de unión de Hash – …el pequeño conjunto de datos está metido en todos los ejecutores y unido al gran conjunto de datos dividido.
Emitir Hash Join no implica una operación de clasificación y es una de las razones por las que es el algoritmo de unión más rápido. Veremos en detalle cómo funciona con un ejemplo.
Ejemplo
chispa.sql.autoBroadcastJoinThreshold – tamaño máximo de la trama de datos que puede ser emitida. El valor por defecto es de 10 MB. Lo que significa que sólo se pueden emitir conjuntos de datos inferiores a 10 MB.
Tenemos 2 DataFrames df1 y df2 con una columna en cada uno – id1 y id2 respectivamente. Estamos haciendo una simple unión en id1 y id2.
|
scala> chispa.conf.consigue(«spark.sql.autoBroadcastJoinThreshold») res1: Cuerda = 10485760 scala> val datos1 = Seq(10, 20, 20, 30, 40, 10, 40, 20, 20, 20, 20, 50) datos1: Seq[[Int] = Lista(10, 20, 20, 30, 40, 10, 40, 20, 20, 20, 20, 50) scala> val df1 = datos1.toDF(«id1») df1: org.apache.chispa.sql.DataFrame = [[id1: int] scala> val datos2 = Seq(30, 20, 40, 50) datos2: Seq[[Int] = Lista(30, 20, 40, 50) scala> val df2 = datos2.toDF(«id2») df2: org.apache.chispa.sql.DataFrame = [[id2: int] |
Tenga en cuenta que también puede utilizar la función de emisión para especificar el fotograma de datos que desea emitir. Y la sintaxis se vería como…
df1.unirse a(difusión(df2), $«id1» === $«id2»)
|
scala> val dfJoined = df1.unirse a(df2, $«id1» === $«id2») dfJoined: org.apache.chispa.sql.DataFrame = [[id1: int, id2: int] |
Cuando vemos el plan que se ejecutará, podemos ver que se utiliza BroadcastHashJoin.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
scala> dfJoined.queryExecution.executedPlan res2: org.apache.chispa.sql.ejecución.SparkPlan = *(1) BroadcastHashJoin [[id1#3], [id2#8]Interior, BuildRight… :– LocalTableScan [[id1#3] +– BroadcastExchange HashedRelationBroadcastMode(Lista(el elenco(entrada[[0, int, falso] como bigint))) +– LocalTableScan [[id2#8] scala> dfJoined.mostrar +—–+—–+ |id1|id2| +—–+—–+ | 20| 20| | 20| 20| | 30| 30| | 40| 40| | 40| 40| | 20| 20| | 20| 20| | 20| 20| | 20| 20| | 50| 50| +—–+—–+ |
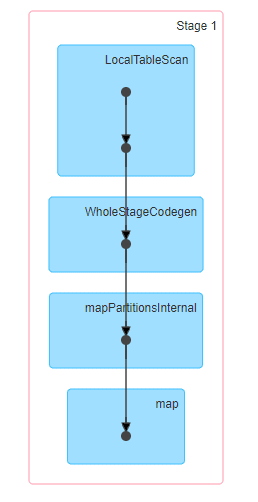
Las etapas involucradas en el Broadcast Hash se unen
Como pueden ver abajo, la totalidad de la emisión de Hash Join se realiza en una sola etapa. Lo que significa que no hay que barajar.
El funcionamiento interno de Broadcast Hash Join
Hay 2 fases en una fase de emisión Hash Join – Fase de emisión y fase de Hash Join
Fase de emisión
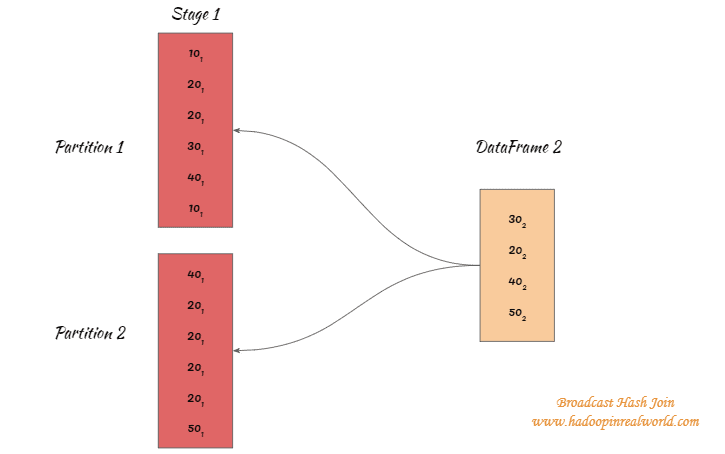
Digamos que el gran conjunto de datos se divide en 2 particiones y esto significa que tendremos 2 tareas separadas asignadas para procesar las particiones.
El marco de datos más pequeño entre los dos marcos de datos será transmitido a los ejecutores que procesan ambas tareas.
20(1) significa que es del DataFrame 1 y 20(2) significa que es del DataFrame 2.
Fase de unión de Hash
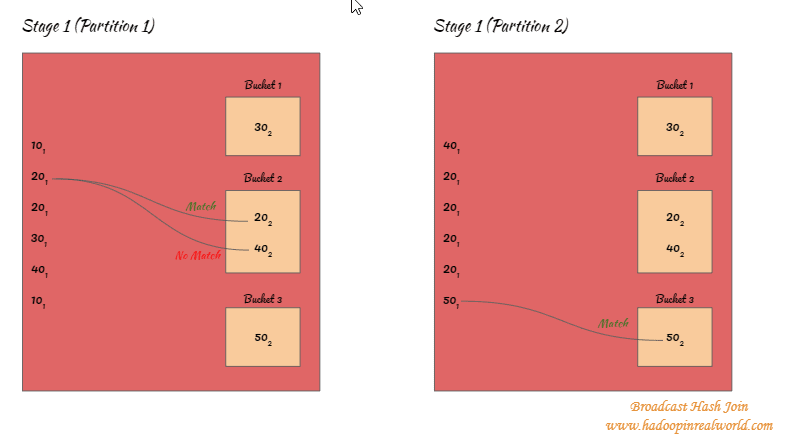
- El pequeño conjunto de datos que fue transmitido a los ejecutores será guardado con llave en los cubos…
- En el siguiente ejemplo la llave 30 está asignada al cubo 1, así que cada vez que nos encontremos con un disco con la llave 30 se asignará al cubo 1. La 20 y la 40 se asignan al cubo 2. La 50 se asigna al cubo 3.
- Una vez que el pequeño conjunto de datos se haya triturado y abombado, las claves del gran conjunto de datos se intentarán hacer coincidir SOLAMENTE con los respectivos cubos. Por ejemplo, 20(1) de un gran conjunto de datos se precipitará y será cartografiado a la cubeta 2. Así que con la unión de Hash, sólo intentaremos hacer coincidir las claves para 20(1) con todas las llaves dentro del cubo 2 y no en ningún otro cubo.
- Los pasos 2 y 3 se ejecutan en todas las particiones del escenario para todos los registros del gran conjunto de datos.
Como hemos visto, Broadcast Hash Join no implica una operación de tipo.
¿Cuándo funciona Broadcast Hash Join?
- Broadcast Hash Join es el algoritmo de unión más rápido cuando se cumplen los siguientes criterios.
- Funciona sólo para las uniones de equi.
- Funciona para todas las uniones excepto para las uniones externas completas.
- Broadcast Hash Join funciona cuando un conjunto de datos es lo suficientemente pequeño como para poder ser emitido y «hash».
¿Cuando la transmisión de Hash Join no funciona?
- La unión de la radiodifusión no funciona para las uniones no ecológicas.
- La unión de la transmisión no funciona para las uniones externas completas
La emisión de Hash Join no funciona bien si el conjunto de datos que se está emitiendo es grande.
- Si el tamaño del conjunto de datos transmitidos es grande, podría convertirse en una operación de red intensiva y hacer que la ejecución de su trabajo se ralentice.
- Si el tamaño del conjunto de datos transmitidos es grande, obtendrías una excepción de OutOfMemory cuando Spark construya la tabla de Hash sobre los datos. Porque la tabla de Hash se mantendrá en la memoria.
¿Interesado en aprender acerca de Broadcast Nested Loop Únete a Spark? – Haz clic aquí.