
Subir la colina de la prueba es un enfoque para lograr buenas o perfectas predicciones en una máquina de aprendizaje de la competencia sin tocar el conjunto de entrenamiento o incluso desarrollar un modelo de predicción.
Como enfoque de las competiciones de aprendizaje de máquinas, está legítimamente mal visto, y la mayoría de las plataformas de competición imponen limitaciones para evitarlo, lo cual es importante.
Sin embargo, subir la colina del conjunto de pruebas es algo que un practicante de aprendizaje de máquinas hace accidentalmente como parte de la participación en una competición. Al desarrollar una implementación explícita para escalar una colina en un conjunto de pruebas, ayuda a comprender mejor lo fácil que puede ser sobreajustar un conjunto de datos de prueba utilizándolo en exceso para evaluar los conductos de modelado.
En este tutorial, descubrirá cómo escalar el conjunto de pruebas para el aprendizaje de la máquina.
Después de completar este tutorial, lo sabrás:
- Se pueden hacer predicciones perfectas subiendo la colina del conjunto de pruebas sin siquiera mirar el conjunto de datos de entrenamiento.
- Cómo escalar el conjunto de pruebas para las tareas de clasificación y regresión.
- Implícitamente escalamos el conjunto de pruebas cuando lo utilizamos en exceso para evaluar nuestros conductos de modelización.
Ponga en marcha su proyecto con mi nuevo libro «Data Preparation for Machine Learning», que incluye tutoriales paso a paso y el El código fuente de Python archivos para todos los ejemplos.
Empecemos.
Cómo escalar el conjunto de pruebas para el aprendizaje automático
Foto de Stig Nygaard, algunos derechos reservados.
Resumen del Tutorial
Este tutorial está dividido en cinco partes; son:
- Subir a la colina el conjunto de pruebas
- Algoritmo de escalada de colinas
- Cómo implementar la escalada de colinas
- Conjunto de datos de clasificación de la diabetes de Hill Climblage
- Conjunto de datos sobre la regresión de la vivienda en Hill Climbimblage
Subir a la colina el conjunto de pruebas
Las competiciones de aprendizaje de máquinas, como las de Kaggle, proporcionan un completo conjunto de datos de entrenamiento, así como sólo la entrada para el conjunto de pruebas.
El objetivo de una competición determinada es predecir los valores objetivo, como las etiquetas o los valores numéricos del conjunto de pruebas. Las soluciones se evalúan contra los valores objetivo del conjunto de pruebas ocultos y se puntúan adecuadamente. La presentación con la mejor puntuación contra el conjunto de pruebas gana la competencia.
El reto de una competición de aprendizaje de máquinas puede enmarcarse como un problema de optimización. Tradicionalmente, el participante en la competición actúa como el algoritmo de optimización, explorando diferentes conductos de modelización que dan lugar a diferentes conjuntos de predicciones, puntuando las predicciones, y luego realizando cambios en el conducto que se espera que den lugar a una mejora de la puntuación.
Este proceso también puede ser modelado directamente con un algoritmo de optimización en el que se generan y evalúan las predicciones de los candidatos sin tener que mirar nunca el conjunto de pruebas.
Generalmente, esto se conoce como el conjunto de pruebas de escalada de colinas, ya que uno de los algoritmos de optimización más simples de implementar para resolver este problema es el algoritmo de escalada de colinas.
Aunque escalar la colina del conjunto de pruebas está justamente mal visto en las competiciones de aprendizaje de máquinas reales, puede ser un ejercicio interesante para aplicar el enfoque con el fin de aprender sobre las limitaciones del mismo y los peligros de sobreajustar el conjunto de pruebas. Además, el hecho de que el conjunto de pruebas pueda predecirse perfectamente sin tocar nunca el conjunto de datos de entrenamiento a menudo sorprende a muchos practicantes principiantes de aprendizaje automático.
Lo más importante es que implícitamente escalamos el conjunto de pruebas cuando evaluamos repetidamente diferentes tuberías de modelado. El riesgo es que la puntuación se mejore en el conjunto de pruebas a costa de un mayor error de generalización, es decir, un peor rendimiento en el problema más amplio.
Las personas que organizan competiciones de aprendizaje de máquinas son muy conscientes de este problema e imponen limitaciones a la evaluación de la predicción para contrarrestarlo, como la limitación de la evaluación a una o unas pocas por día y la presentación de los resultados en un subconjunto oculto del conjunto de pruebas en lugar de todo el conjunto de pruebas. Para más información sobre esto, véanse los documentos enumerados en la sección de lecturas adicionales.
A continuación, veamos cómo podemos implementar el algoritmo de escalada de colinas para optimizar las predicciones para un conjunto de pruebas.
¿Quieres empezar a preparar los datos?
Toma mi curso intensivo gratuito de 7 días por correo electrónico ahora (con código de muestra).
Haga clic para inscribirse y también para obtener una versión gratuita del curso en formato PDF.
Descargue su minicurso GRATUITO
Algoritmo de escalada de colinas
El algoritmo de escalada de colinas es un algoritmo de optimización muy simple.
Implica generar una solución candidata y evaluarla. Este es el punto de partida que luego se mejora gradualmente hasta que, o bien no se puede lograr ninguna mejora adicional, o nos quedamos sin tiempo, recursos o interés.
Las nuevas soluciones candidatas se generan a partir de la solución candidata existente. Típicamente, esto implica hacer un solo cambio en la solución candidata, evaluarla y aceptar la solución candidata como la nueva «actual«si es tan bueno o mejor que la solución actual anterior. De lo contrario, se descarta.
Podríamos pensar que es una buena idea aceptar sólo a los candidatos que tienen una mejor puntuación. Este es un enfoque razonable para muchos problemas sencillos, aunque, en problemas más complejos, es deseable aceptar diferentes candidatos con la misma puntuación para ayudar al proceso de búsqueda a escalar áreas planas (mesetas) en el espacio de los rasgos.
Al subir la colina del conjunto de pruebas, una solución candidata es una lista de predicciones. Para una tarea de clasificación binaria, es una lista de valores 0 y 1 para las dos clases. Para una tarea de regresión, esta es una lista de números en el rango de la variable objetivo.
Una modificación de una solución candidata para la clasificación sería seleccionar una predicción y voltearla de 0 a 1 o de 1 a 0. Una modificación de una solución candidata para la regresión sería añadir el ruido gaussiano a un valor de la lista o sustituir un valor de la lista por un nuevo valor.
La puntuación de las soluciones implica el cálculo de una métrica de puntuación, como la precisión de la clasificación en las tareas de clasificación o el error absoluto medio para una tarea de regresión.
Ahora que estamos familiarizados con el algoritmo, vamos a implementarlo.
Cómo implementar la escalada de colinas
Desarrollaremos nuestro algoritmo de escalada en una tarea de clasificación sintética.
Primero, creemos una tarea de clasificación binaria con muchas variables de entrada y 5.000 filas de ejemplos. Luego podemos dividir el conjunto de datos en trenes y conjuntos de pruebas.
El ejemplo completo figura a continuación.
|
# ejemplo de un conjunto de datos sintéticos. de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación prueba_de_trenes_split # Definir el conjunto de datos X, y = make_classification(n_muestras=5000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=1) imprimir(X.forma, y.forma) # Split dataset X_tren, X_test, y_tren, y_test = prueba_de_trenes_split(X, y, tamaño_de_prueba=0.33, estado_aleatorio=1) imprimir(X_tren.forma, X_test.forma, y_tren.forma, y_test.forma) |
Ejecutando el ejemplo primero reporta la forma del conjunto de datos creados, mostrando 5.000 filas y 20 variables de entrada.
El conjunto de datos se divide entonces en trenes y conjuntos de pruebas con unos 3.300 para el entrenamiento y unos 1.600 para las pruebas.
|
(5000, 20) (5000,) (3350, 20) (1650, 20) (3350,) (1650,) |
Ahora podemos desarrollar un escalador de colinas.
Primero, podemos crear una función que se cargue, o en este caso, definir el conjunto de datos. Podemos actualizar esta función más tarde cuando queramos cambiar el conjunto de datos.
|
# Cargar o preparar el conjunto de datos de clasificación def load_dataset(): volver make_classification(n_muestras=5000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=1) |
A continuación, necesitamos una función para evaluar las soluciones candidatas, es decir, listas de predicciones.
Usaremos la precisión de la clasificación donde las puntuaciones van desde 0 para la peor solución posible hasta 1 para un conjunto perfecto de predicciones.
|
# Evaluar un conjunto de predicciones def evaluate_predictions(y_test, yhat): volver accuracy_score(y_test, yhat) |
A continuación, necesitamos una función para crear una solución candidata inicial.
Es una lista de predicciones para las etiquetas de clase 0 y 1, lo suficientemente larga como para coincidir con el número de ejemplos del conjunto de pruebas, en este caso, 1650.
Podemos usar la función randint() para generar valores aleatorios de 0 y 1.
|
# crear un conjunto aleatorio de predicciones def random_predictions(n_ejemplos): volver [[randint(0, 1) para _ en rango(n_ejemplos)] |
A continuación, necesitamos una función para crear una versión modificada de una solución candidata.
En este caso, se trata de seleccionar un valor en la solución y voltearlo de 0 a 1 o de 1 a 0.
Típicamente, hacemos un solo cambio para cada nueva solución candidata durante la escalada de la colina, pero he parametrizado la función para que puedas explorar la posibilidad de hacer más de un cambio si quieres.
|
# Modificar el conjunto actual de predicciones def modify_predictions(actual, n_cambios=1): # Copiar la solución actual actualizado = actual.copia() para i en rango(n_cambios): # Selecciona un punto a cambiar ix = randint(0, len(actualizado)–1) # Voltea la etiqueta de la clase actualizado[[ix] = 1 – actualizado[[ix] volver actualizado |
Hasta ahora, todo bien.
A continuación, podemos desarrollar la función que realiza la búsqueda.
En primer lugar, se crea y evalúa una solución inicial llamando a la random_predictions() seguido de la función evaluate_predictions() función.
Luego hacemos un bucle para un número fijo de iteraciones y generamos un nuevo candidato llamando modify_predictions()…evaluarla, y si el resultado es tan bueno o mejor que la solución actual, reemplácela.
El bucle termina cuando terminamos el número preestablecido de iteraciones (elegido arbitrariamente) o cuando se alcanza una puntuación perfecta, que sabemos que en este caso es una precisión de 1,0 (100 por ciento).
La función hill_climb_testset() abajo implementa esto, tomando el conjunto de pruebas como entrada y devolviendo el mejor conjunto de predicciones encontradas durante la escalada de la colina.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# Correr una subida de colina para un conjunto de predicciones def hill_climb_testset(X_test, y_test, max_iteraciones): resultados = lista() # Generar la solución inicial solución = random_predictions(X_test.forma[[0]) # Evaluar la solución inicial puntuación = evaluate_predictions(y_test, solución) resultados.anexar(puntuación) # Subir la colina a una solución para i en rango(max_iteraciones): # Grabar las puntuaciones resultados.anexar(puntuación) # Detente una vez que logremos la mejor puntuación si puntuación == 1.0: break # Generar un nuevo candidato candidato = modify_predictions(solución) # Evaluar el candidato valor = evaluate_predictions(y_test, candidato) # Comprueba si es tan bueno o mejor si valor >= puntuación: solución, puntuación = candidato, valor imprimir(‘>%d, score=%.3f’ % (i, puntuación)) volver solución, resultados |
Eso es todo lo que hay.
El ejemplo completo de la escalada de la colina del conjunto de pruebas se enumera a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
# Ejemplo de escalada de la colina el conjunto de pruebas para una tarea de clasificación de al azar importación randint de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación prueba_de_trenes_split de sklearn.métrica importación accuracy_score de matplotlib importación pyplot # Cargar o preparar el conjunto de datos de clasificación def load_dataset(): volver make_classification(n_muestras=5000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=1) # Evaluar un conjunto de predicciones def evaluate_predictions(y_test, yhat): volver accuracy_score(y_test, yhat) # crear un conjunto aleatorio de predicciones def random_predictions(n_ejemplos): volver [[randint(0, 1) para _ en rango(n_ejemplos)] # Modificar el conjunto actual de predicciones def modify_predictions(actual, n_cambios=1): # Copiar la solución actual actualizado = actual.copia() para i en rango(n_cambios): # Selecciona un punto a cambiar ix = randint(0, len(actualizado)–1) # Voltea la etiqueta de la clase actualizado[[ix] = 1 – actualizado[[ix] volver actualizado # Correr una subida de colina para un conjunto de predicciones def hill_climb_testset(X_test, y_test, max_iteraciones): resultados = lista() # Generar la solución inicial solución = random_predictions(X_test.forma[[0]) # Evaluar la solución inicial puntuación = evaluate_predictions(y_test, solución) resultados.anexar(puntuación) # Subir la colina a una solución para i en rango(max_iteraciones): # Grabar las puntuaciones resultados.anexar(puntuación) # Detente una vez que logremos la mejor puntuación si puntuación == 1.0: break # Generar un nuevo candidato candidato = modify_predictions(solución) # Evaluar el candidato valor = evaluate_predictions(y_test, candidato) # Comprueba si es tan bueno o mejor si valor >= puntuación: solución, puntuación = candidato, valor imprimir(‘>%d, score=%.3f’ % (i, puntuación)) volver solución, resultados # Cargar el conjunto de datos X, y = load_dataset() imprimir(X.forma, y.forma) # Dividir el conjunto de datos en trenes y conjuntos de pruebas X_tren, X_test, y_tren, y_test = prueba_de_trenes_split(X, y, tamaño_de_prueba=0.33, estado_aleatorio=1) imprimir(X_tren.forma, X_test.forma, y_tren.forma, y_test.forma) # Corre, sube la colina yhat, resultados = hill_climb_testset(X_test, y_test, 20000) # Trazar las puntuaciones vs iteraciones pyplot.parcela(resultados) pyplot.mostrar() |
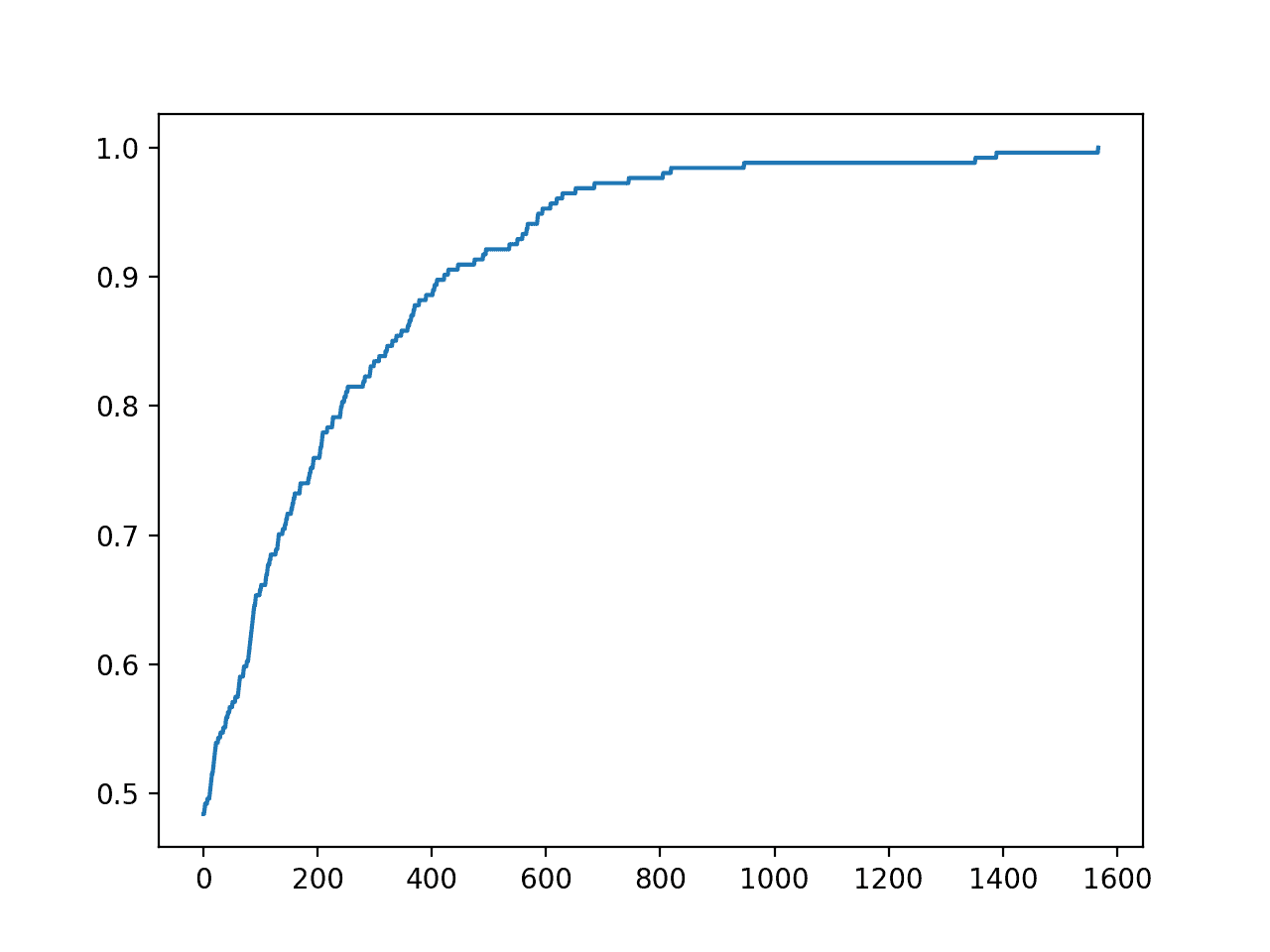
Ejecutando el ejemplo se ejecutará la búsqueda de 20.000 iteraciones o se detendrá si se logra una precisión perfecta.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
En este caso, encontramos un conjunto perfecto de predicciones para el conjunto de pruebas en unas 12.900 iteraciones.
Recordemos que esto se logró sin tocar el conjunto de datos de entrenamiento y sin hacer trampas mirando los valores objetivo del test. En lugar de eso, simplemente optimizamos un conjunto de números.
La lección aquí es que la evaluación repetida de un oleoducto de modelación contra un equipo de prueba hará lo mismo, usándolo como el algoritmo de optimización de escalada de colinas. La solución se adaptará al conjunto de pruebas.
|
… >8092, puntuación=0.996 >8886, puntuación=0.997 >9202, puntuación=0.998 >9322, puntuación=0.998 >9521, puntuación=0.999 >11046, puntuación=0.999 >12932, puntuación=1.000 |
También se crea una trama del progreso de la optimización.
Esto puede ser útil para ver cómo los cambios en el algoritmo de optimización, como la elección de lo que se debe cambiar y cómo se cambia durante la subida de la colina, impactan en la convergencia de la búsqueda.
Trazado de líneas de precisión vs. Iteración de optimización de escalada de colinas para una tarea de clasificación
Ahora que estamos familiarizados con la escalada de colinas del conjunto de pruebas, probemos el enfoque en un conjunto de datos reales.
Conjunto de datos de clasificación de la diabetes de Hill Climblage
Usaremos el conjunto de datos de la diabetes como base para explorar la subida de la colina el conjunto de pruebas para un problema de clasificación.
Cada registro describe los detalles médicos de una mujer, y la predicción es la aparición de la diabetes en los próximos cinco años.
El conjunto de datos tiene ocho variables de entrada y 768 filas de datos; las variables de entrada son todas numéricas y el objetivo tiene dos etiquetas de clase, por ejemplo, es una tarea de clasificación binaria.
A continuación se presenta una muestra de las cinco primeras filas del conjunto de datos.
|
6,148,72,35,0,33.6,0.627,50,1 1,85,66,29,0,26.6,0.351,31,0 8,183,64,0,0,23.3,0.672,32,1 1,89,66,23,94,28.1,0.167,21,0 0,137,40,35,168,43.1,2.288,33,1 … |
Podemos cargar el conjunto de datos directamente usando Pandas, de la siguiente manera.
|
# Cargar o preparar el conjunto de datos de clasificación def load_dataset(): url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv’ df = read_csv(url, encabezado=Ninguno) datos = df.valores volver datos[[:, :–1], datos[[:, –1] |
El resto del código permanece sin cambios.
Esto está creado para que puedas dejar tu propia tarea de clasificación binaria y probarla.
El ejemplo completo figura a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
# ejemplo de escalada de la colina el conjunto de pruebas para el conjunto de datos de la diabetes de al azar importación randint de pandas importación read_csv de sklearn.model_selection importación prueba_de_trenes_split de sklearn.métrica importación accuracy_score de matplotlib importación pyplot # Cargar o preparar el conjunto de datos de clasificación def load_dataset(): url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv’ df = read_csv(url, encabezado=Ninguno) datos = df.valores volver datos[[:, :–1], datos[[:, –1] # Evaluar un conjunto de predicciones def evaluate_predictions(y_test, yhat): volver accuracy_score(y_test, yhat) # Crear un conjunto aleatorio de predicciones def random_predictions(n_ejemplos): volver [[randint(0, 1) para _ en rango(n_ejemplos)] # Modificar el conjunto actual de predicciones def modify_predictions(actual, n_cambios=1): # Copiar la solución actual actualizado = actual.copia() para i en rango(n_cambios): # Selecciona un punto a cambiar ix = randint(0, len(actualizado)–1) # Voltea la etiqueta de la clase actualizado[[ix] = 1 – actualizado[[ix] volver actualizado # Correr una subida de colina para un conjunto de predicciones def hill_climb_testset(X_test, y_test, max_iteraciones): resultados = lista() # Generar la solución inicial solución = random_predictions(X_test.forma[[0]) # Evaluar la solución inicial puntuación = evaluate_predictions(y_test, solución) resultados.anexar(puntuación) # Subir la colina a una solución para i en rango(max_iteraciones): # Grabar las puntuaciones resultados.anexar(puntuación) # Detente una vez que logremos la mejor puntuación si puntuación == 1.0: break # Generar un nuevo candidato candidato = modify_predictions(solución) # Evaluar el candidato valor = evaluate_predictions(y_test, candidato) # Comprueba si es tan bueno o mejor si valor >= puntuación: solución, puntuación = candidato, valor imprimir(‘>%d, score=%.3f’ % (i, puntuación)) volver solución, resultados # Cargar el conjunto de datos X, y = load_dataset() imprimir(X.forma, y.forma) # Dividir el conjunto de datos en trenes y conjuntos de pruebas X_tren, X_test, y_tren, y_test = prueba_de_trenes_split(X, y, tamaño_de_prueba=0.33, estado_aleatorio=1) imprimir(X_tren.forma, X_test.forma, y_tren.forma, y_test.forma) # Corre, sube la colina yhat, resultados = hill_climb_testset(X_test, y_test, 5000) # Trazar las puntuaciones vs iteraciones pyplot.parcela(resultados) pyplot.mostrar() |
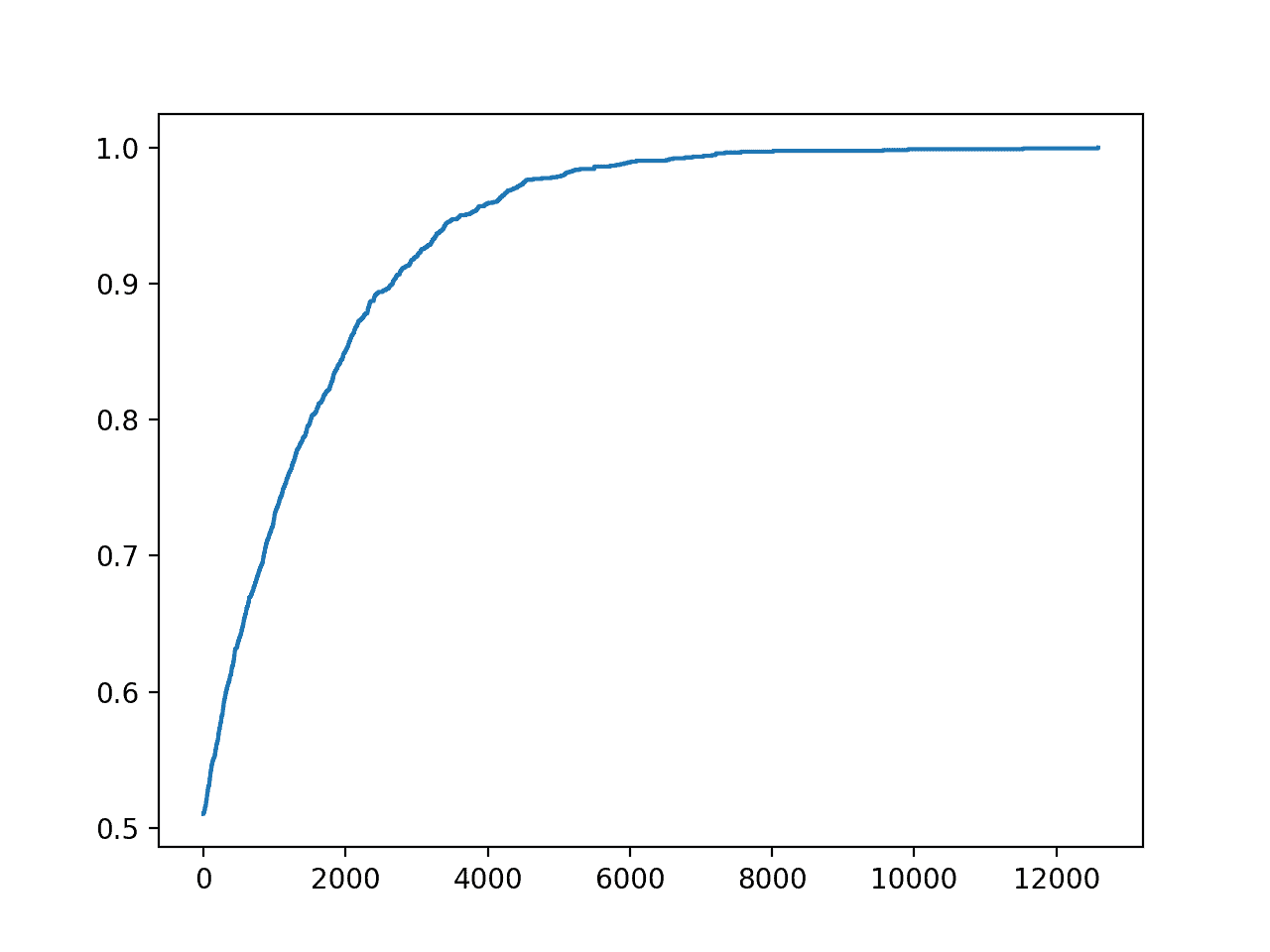
La ejecución del ejemplo informa del número de iteraciones y la precisión cada vez que se observa una mejora durante la búsqueda.
Utilizamos menos iteraciones en este caso porque es un problema más simple de optimizar ya que tenemos menos predicciones que hacer.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
En este caso, podemos ver que logramos una precisión perfecta en unas 1.500 iteraciones.
|
… >617, puntuación=0.961 >627, puntuación=0.965 >650, puntuación=0.969 >683, puntuación=0,972 >743, puntuación=0.976 >803, puntuación=0.980 >817, puntuación=0.984 >945, puntuación=0.988 >1350, puntuación=0.992 >1387, puntuación=0.996 >1565, puntuación=1.000 |
También se crea un gráfico de líneas del progreso de la búsqueda que muestra que la convergencia fue rápida.
Gráfica de líneas de precisión vs. Iteración de optimización de escalada para el conjunto de datos de la diabetes
Conjunto de datos sobre la regresión de la vivienda en Hill Climbimblage
Usaremos el conjunto de datos de la vivienda como base para explorar el problema de regresión del conjunto de pruebas.
El conjunto de datos de la vivienda implica la predicción del precio de una casa en miles de dólares dados los detalles de la casa y su vecindario.
Es un problema de regresión, lo que significa que estamos prediciendo un valor numérico. Hay 506 observaciones con 13 variables de entrada y una de salida.
A continuación figura una muestra de las cinco primeras filas.
|
0.00632,18.00,2.310,0,0.5380,6.5750,65.20,4.0900,1,296.0,15.30,396.90,4.98,24.00 0.02731,0.00,7.070,0,0.4690,6.4210,78.90,4.9671,2,242.0,17.80,396.90,9.14,21.60 0.02729,0.00,7.070,0,0.4690,7.1850,61.10,4.9671,2,242.0,17.80,392.83,4.03,34.70 0.03237,0.00,2.180,0,0.4580,6.9980,45.80,6.0622,3,222.0,18.70,394.63,2.94,33.40 0.06905,0.00,2.180,0,0.4580,7.1470,54.20,6.0622,3,222.0,18.70,396.90,5.33,36.20 … |
Primero, podemos actualizar el load_dataset() para cargar el conjunto de datos de la vivienda.
Como parte de la carga del conjunto de datos, normalizaremos el valor del objetivo. Esto hará que la escalada de las colinas sea más simple ya que podemos limitar los valores de punto flotante al rango de 0 a 1.
Esto no es necesario en general, sólo el enfoque adoptado aquí para simplificar el algoritmo de búsqueda.
|
# Cargar o preparar el conjunto de datos de clasificación def load_dataset(): url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/housing.csv’ df = read_csv(url, encabezado=Ninguno) datos = df.valores X, y = datos[[:, :–1], datos[[:, –1] # normalizar el objetivo scaler = MinMaxScaler() y = y.remodelar((len(y), 1)) y = scaler.fit_transform(y) volver X, y |
A continuación, podemos actualizar la función de puntuación para utilizar el error absoluto medio entre los valores esperados y los previstos.
|
# Evaluar un conjunto de predicciones def evaluate_predictions(y_test, yhat): volver error_absoluto_medio(y_test, yhat) |
También debemos actualizar la representación de una solución de las etiquetas 0 y 1 a valores de punto flotante entre 0 y 1.
La generación de la solución candidata inicial debe cambiarse para crear una lista de flotadores aleatorios.
|
# crear un conjunto aleatorio de predicciones def random_predictions(n_ejemplos): volver [[al azar() para _ en rango(n_ejemplos)] |
El único cambio que se hace a una solución para crear una nueva solución candidata, en este caso, implica simplemente reemplazar una predicción elegida al azar en la lista por un nuevo flotador aleatorio.
Elegí esto porque era simple.
|
# Modificar el conjunto actual de predicciones def modify_predictions(actual, n_cambios=1): # Copiar la solución actual actualizado = actual.copia() para i en rango(n_cambios): # Selecciona un punto a cambiar ix = randint(0, len(actualizado)–1) # Voltea la etiqueta de la clase actualizado[[ix] = al azar() volver actualizado |
Un mejor enfoque sería añadir el ruido gaussiano a un valor existente, y les dejo esto como una extensión. Si lo intentan, háganmelo saber en los comentarios de abajo.
Por ejemplo:
|
... # Agregar el ruido gaussiano actualizado[[ix] += gauss(0, 0.1) |
Finalmente, la búsqueda debe ser actualizada.
El mejor valor es ahora un error de 0.0, usado para detener la búsqueda si se encuentra.
|
... # Detente una vez que logremos la mejor puntuación si puntuación == 0.0: break |
También necesitamos cambiar la búsqueda de maximizar el puntaje a minimizarlo ahora.
|
... # Comprueba si es tan bueno o mejor si valor <= puntuación: solución, puntuación = candidato, valor imprimir(‘>%d, score=%.3f’ % (i, puntuación)) |
La función de búsqueda actualizada con estos dos cambios se enumera a continuación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# Correr una subida de colina para un conjunto de predicciones def hill_climb_testset(X_test, y_test, max_iteraciones): resultados = lista() # Generar la solución inicial solución = random_predictions(X_test.forma[[0]) # Evaluar la solución inicial puntuación = evaluate_predictions(y_test, solución) imprimir(‘>%.3f’ % puntuación) # Subir la colina a una solución para i en rango(max_iteraciones): # Grabar las puntuaciones resultados.anexar(puntuación) # Detente una vez que logremos la mejor puntuación si puntuación == 0.0: break # Generar un nuevo candidato candidato = modify_predictions(solución) # Evaluar el candidato valor = evaluate_predictions(y_test, candidato) # Comprueba si es tan bueno o mejor si valor <= puntuación: solución, puntuación = candidato, valor imprimir(‘>%d, score=%.3f’ % (i, puntuación)) volver solución, resultados |
A continuación se muestra el ejemplo completo de la escalada de la colina para una tarea de regresión.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 |
# ejemplo de escalada de la colina el conjunto de pruebas para el conjunto de datos de la vivienda de al azar importación al azar de al azar importación randint de pandas importación read_csv de sklearn.model_selection importación prueba_de_trenes_split de sklearn.métrica importación error_absoluto_medio de sklearn.preprocesamiento importación MinMaxScaler de matplotlib importación pyplot # Cargar o preparar el conjunto de datos de clasificación def load_dataset(): url = ‘https://raw.githubusercontent.com/jbrownlee/Datasets/master/housing.csv’ df = read_csv(url, encabezado=Ninguno) datos = df.valores X, y = datos[[:, :–1], datos[[:, –1] # normalizar el objetivo scaler = MinMaxScaler() y = y.remodelar((len(y), 1)) y = scaler.fit_transform(y) volver X, y # Evaluar un conjunto de predicciones def evaluate_predictions(y_test, yhat): volver error_absoluto_medio(y_test, yhat) # Crear un conjunto aleatorio de predicciones def random_predictions(n_ejemplos): volver [[al azar() para _ en rango(n_ejemplos)] # Modificar el conjunto actual de predicciones def modify_predictions(actual, n_cambios=1): # Copiar la solución actual actualizado = actual.copia() para i en rango(n_cambios): # Selecciona un punto a cambiar ix = randint(0, len(actualizado)–1) # Voltea la etiqueta de la clase actualizado[[ix] = al azar() volver actualizado # Correr una subida de colina para un conjunto de predicciones def hill_climb_testset(X_test, y_test, max_iteraciones): resultados = lista() # Generar la solución inicial solución = random_predictions(X_test.forma[[0]) # Evaluar la solución inicial puntuación = evaluate_predictions(y_test, solución) imprimir(‘>%.3f’ % puntuación) # Subir la colina a una solución para i en rango(max_iteraciones): # Grabar las puntuaciones resultados.anexar(puntuación) # Detente una vez que logremos la mejor puntuación si puntuación == 0.0: break # Generar un nuevo candidato candidato = modify_predictions(solución) # Evaluar el candidato valor = evaluate_predictions(y_test, candidato) # Comprueba si es tan bueno o mejor si valor <= puntuación: solución, puntuación = candidato, valor imprimir(‘>%d, score=%.3f’ % (i, puntuación)) volver solución, resultados # Cargar el conjunto de datos X, y = load_dataset() imprimir(X.forma, y.forma) # Dividir el conjunto de datos en trenes y conjuntos de pruebas X_tren, X_test, y_tren, y_test = prueba_de_trenes_split(X, y, tamaño_de_prueba=0.33, estado_aleatorio=1) imprimir(X_tren.forma, X_test.forma, y_tren.forma, y_test.forma) # Corre, sube la colina yhat, resultados = hill_climb_testset(X_test, y_test, 100000) # Trazar las puntuaciones vs iteraciones pyplot.parcela(resultados) pyplot.mostrar() |
Ejecutando el ejemplo se informa el número de iteración y MAE cada vez que se ve una mejora durante la búsqueda.
Utilizamos muchas más iteraciones en este caso porque es un problema más complejo de optimizar. El método elegido para crear soluciones candidatas también hace que sea más lento y menos probable que logremos un error perfecto.
De hecho, no lograríamos un error perfecto; en cambio, sería mejor detenerse si el error alcanzara un valor inferior a un valor mínimo como 1e-7 o algo significativo para el dominio de destino. Esto también se deja como ejercicio para el lector.
Por ejemplo:
|
... # Detente una vez que logremos una buena si puntuación <= 1e–7: break |
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
En este caso, podemos ver que logramos un buen error al final de la carrera.
|
… >95991, puntuación=0.001 >96011, puntuación=0.001 >96295, puntuación=0.001 >96366, puntuación=0.001 >96585, puntuación=0.001 >97575, puntuación=0.001 >98828, puntuación=0.001 >98947, puntuación=0.001 >99712, puntuación=0.001 >99913, puntuación=0.001 |
También se crea un gráfico de líneas del progreso de la búsqueda que muestra que la convergencia fue rápida y se mantiene plana durante la mayoría de las iteraciones.
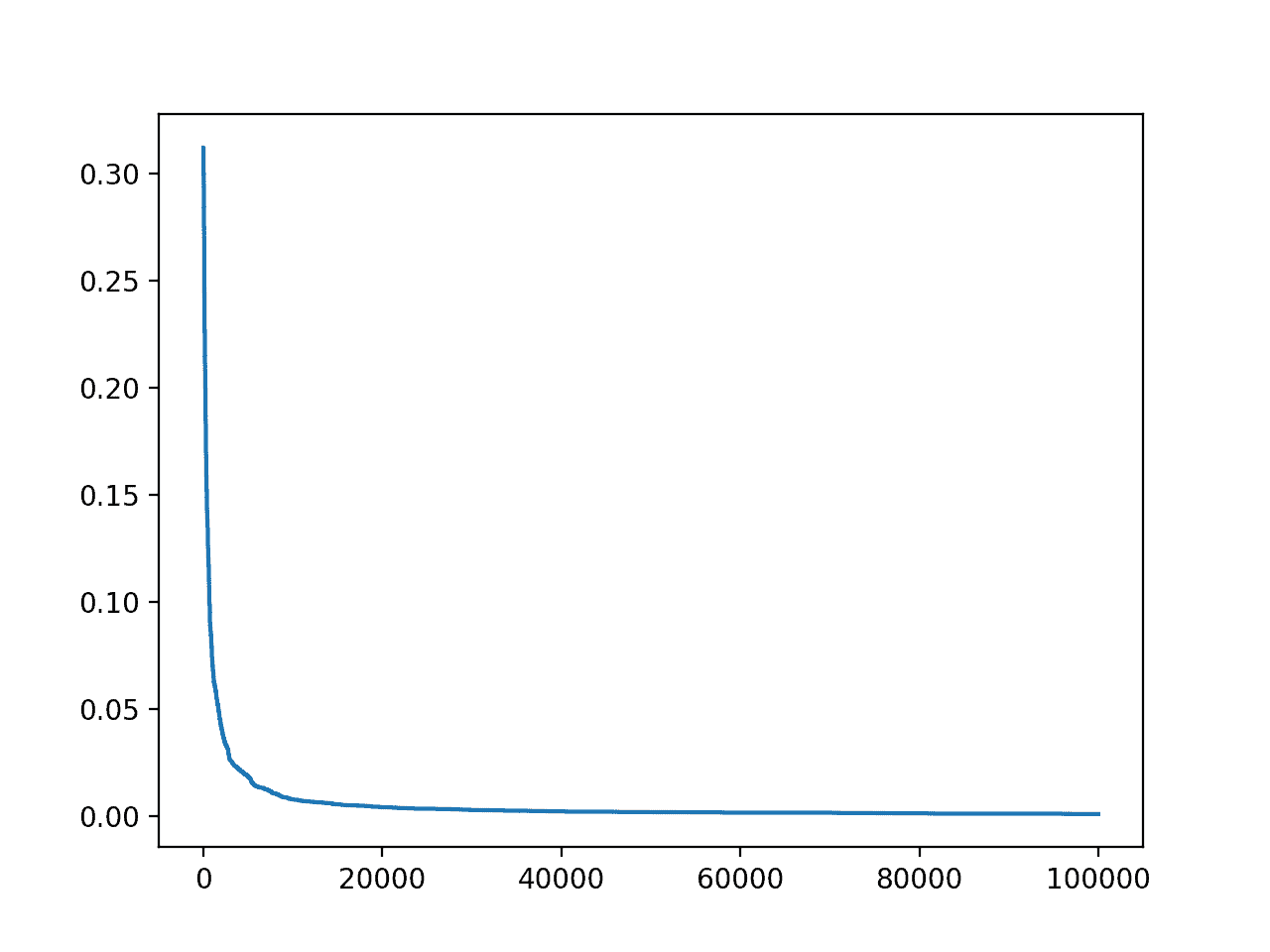
Trazado de líneas de precisión vs. Iteración de optimización de la subida de colinas para el conjunto de datos de la vivienda
Más lecturas
Esta sección proporciona más recursos sobre el tema si desea profundizar en él.
Documentos
Artículos
Resumen
En este tutorial, descubriste cómo escalar el conjunto de pruebas para el aprendizaje de la máquina.
Específicamente, aprendiste:
- Se pueden hacer predicciones perfectas subiendo la colina del conjunto de pruebas sin siquiera mirar el conjunto de datos de entrenamiento.
- Cómo escalar el conjunto de pruebas para las tareas de clasificación y regresión.
- Implícitamente escalamos el conjunto de pruebas cuando lo utilizamos en exceso para evaluar nuestros conductos de modelización.
¿Tiene alguna pregunta?
Haga sus preguntas en los comentarios de abajo y haré lo posible por responder.
¡Controla la preparación de los datos modernos!

Prepare sus datos de aprendizaje de la máquina en minutos
…con sólo unas pocas líneas de código pitón…
Descubre cómo en mi nuevo Ebook:
Preparación de datos para el aprendizaje automático
Proporciona Tutoriales de auto-estudio con código de trabajo completo en:
Selección de características, RFE, Limpieza de datos, Transformaciones de datos, Escalado, Reducción de la dimensionalidad,
y mucho más…
Traer las modernas técnicas de preparación de datos a
Sus proyectos de aprendizaje de la máquina
Ver lo que hay dentro