
Máquina de Gradiente Ligero Impulsado, o LightGBM para abreviar, es una biblioteca de código abierto que proporciona una implementación eficiente y efectiva del algoritmo de aumento de gradiente.
LightGBM amplía el algoritmo de aumento de gradientes añadiendo un tipo de selección automática de características, así como centrándose en aumentar los ejemplos con gradientes más grandes. Esto puede resultar en una dramática aceleración del entrenamiento y en una mejora del rendimiento predictivo.
Como tal, el LightGBM se ha convertido en un algoritmo de facto para las competiciones de aprendizaje de máquinas cuando se trabaja con datos tabulares para las tareas de modelado predictivo de regresión y clasificación. Como tal, tiene una parte de la culpa del aumento de la popularidad y la adopción más amplia de los métodos de impulso de gradiente en general, junto con el Impulso de Gradiente Extremo (XGBoost).
En este tutorial, descubrirás cómo desarrollar conjuntos de máquinas de gradiente de luz potenciada para la clasificación y la regresión.
Después de completar este tutorial, lo sabrás:
- Light Gradient Boosted Machine (LightGBM) es una eficiente implementación de código abierto del algoritmo de conjunto de aumento de gradiente estocástico.
- Cómo desarrollar conjuntos LightGBM para la clasificación y la regresión con la API de aprendizaje de ciencias.
- Cómo explorar el efecto de los hiperparámetros del modelo LightGBM en el rendimiento del modelo.
Empecemos.

Cómo desarrollar un conjunto de máquinas de gradiente de luz (LightGBM)
Foto de GPA Photo Archive, algunos derechos reservados.
Resumen del Tutorial
Este tutorial está dividido en tres partes; son:
- Algoritmo de la máquina de gradientes de luz
- LightGBM Scikit-Learn API
- Conjunto LightGBM para la clasificación
- Conjunto LightGBM para la regresión
- Hiperparámetros LightGBM
- Explorar el número de árboles
- Explorar la profundidad del árbol
- Explorar el ritmo de aprendizaje
- Explorar el tipo de impulso
Algoritmo de la máquina de gradientes de luz
El aumento de gradiente se refiere a una clase de algoritmos de aprendizaje de máquinas en conjunto que pueden utilizarse para la clasificación o la regresión de problemas de modelado predictivo.
Los conjuntos se construyen a partir de modelos de árboles de decisión. Los árboles se añaden uno a uno al conjunto y se ajustan para corregir los errores de predicción de los modelos anteriores. Este es un tipo de modelo de aprendizaje de máquinas de conjuntos al que se le llama «boosting».
Los modelos se ajustan usando cualquier función de pérdida diferenciable arbitraria y algoritmo de optimización de descenso de gradiente. Esto le da a la técnica su nombre, «aumento del gradiente…ya que el gradiente de pérdida se minimiza al ajustar el modelo, como una red neuronal.
Para más información sobre la mejora de los gradientes, vea el tutorial:
Light Gradient Boosted Machine, o LightGBM para abreviar, es una implementación de código abierto de refuerzo de gradiente diseñada para ser eficiente y quizás más efectiva que otras implementaciones.
Como tal, LightGBM se refiere al proyecto de código abierto, la biblioteca de software y el algoritmo de aprendizaje de la máquina. De esta manera, es muy similar a la técnica de Extreme Gradient Boosting o XGBoost.
LightGBM fue descrito por Guolin Ke, et al. en el documento de 2017 titulado «LightGBM: Un árbol de decisión de impulso de gradiente altamente eficiente». La implementación introduce dos ideas clave: GOSS y EFB.
El muestreo de una sola cara basado en el gradiente, o GOSS para abreviar, es una modificación del método de potenciación del gradiente que centra la atención en los ejemplos de capacitación que dan lugar a un gradiente mayor, lo que a su vez acelera el aprendizaje y reduce la complejidad computacional del método.
Con el GOSS, excluimos una proporción significativa de instancias de datos con pequeños gradientes, y sólo utilizamos el resto para estimar la ganancia de información. Probamos que, dado que las instancias de datos con gradientes más grandes juegan un papel más importante en el cálculo de la ganancia de información, el GOSS puede obtener una estimación bastante precisa de la ganancia de información con un tamaño de datos mucho más pequeño.
– LightGBM: Un árbol de decisión de impulso de gradiente altamente eficiente, 2017.
La agrupación de características exclusivas, o EFB para abreviar, es un enfoque para agrupar características escasas (en su mayoría cero) y mutuamente exclusivas, como entradas variables categóricas que han sido codificadas en un solo punto. Como tal, es un tipo de selección automática de características.
… agrupamos características mutuamente excluyentes (es decir, rara vez toman valores distintos de cero simultáneamente), para reducir el número de características.
– LightGBM: Un árbol de decisión de impulso de gradiente altamente eficiente, 2017.
Juntos, estos dos cambios pueden acelerar el tiempo de entrenamiento del algoritmo hasta 20 veces. Como tal, el LightGBM puede ser considerado como un árbol de decisión que aumenta el gradiente (GBDT) con la adición del GOSS y el EFB.
Llamamos a nuestra nueva implementación de GBDT con GOSS y EFB LightGBM. Nuestros experimentos en múltiples conjuntos de datos públicos muestran que, el LightGBM acelera el proceso de entrenamiento del GBDT convencional hasta más de 20 veces, mientras alcanza casi la misma precisión
– LightGBM: Un árbol de decisión de impulso de gradiente altamente eficiente, 2017.
LightGBM Scikit-Learn API
LightGBM puede ser instalado como una biblioteca independiente y el modelo LightGBM puede ser desarrollado usando el API de scikit-learn.
El primer paso es instalar la biblioteca de LightGBM, si no está ya instalada. Esto se puede lograr usando el administrador de paquetes de pip python en la mayoría de las plataformas; por ejemplo:
|
sudo pip instalar lightgbm |
A continuación, puede confirmar que la biblioteca de LightGBM se instaló correctamente y puede ser utilizada ejecutando el siguiente script.
|
# Revisar la versión lightgbm importación lightgbm imprimir(lightgbm.La versión…) |
Ejecutando el guión se imprimirá tu versión de la biblioteca de LightGBM que has instalado.
Tu versión debería ser la misma o más alta. Si no, debes actualizar tu versión de la biblioteca de LightGBM.
Si necesita instrucciones específicas para su entorno de desarrollo, consulte el tutorial:
La biblioteca de LightGBM tiene su propia API personalizada, aunque usaremos el método a través de las clases de envoltorio de scikit-learn: LGBMRegressor y LGBMClassifier. Esto nos permitirá utilizar el conjunto completo de herramientas de la biblioteca de aprendizaje de la máquina scikit-learn para preparar datos y evaluar modelos.
Ambos modelos operan de la misma manera y toman los mismos argumentos que influyen en la forma en que los árboles de decisión se crean y se añaden al conjunto.
La aleatoriedad se utiliza en la construcción del modelo. Esto significa que cada vez que el algoritmo se ejecute con los mismos datos, producirá un modelo ligeramente diferente.
Cuando se utilizan algoritmos de aprendizaje automático que tienen un algoritmo de aprendizaje estocástico, es una buena práctica evaluarlos promediando su rendimiento a través de múltiples ejecuciones o repeticiones de validación cruzada. Al ajustar un modelo final, puede ser conveniente aumentar el número de árboles hasta que se reduzca la varianza del modelo a través de evaluaciones repetidas, o ajustar múltiples modelos finales y promediar sus predicciones.
Echemos un vistazo a cómo desarrollar un conjunto LightGBM tanto para la clasificación como para la regresión.
Conjunto LightGBM para la clasificación
En esta sección, veremos el uso de LightGBM para un problema de clasificación.
Primero, podemos usar la función make_classification() para crear un problema de clasificación binaria sintética con 1.000 ejemplos y 20 características de entrada.
El ejemplo completo figura a continuación.
|
# Conjunto de datos de clasificación de pruebas de sklearn.conjuntos de datos importación hacer_clasificación # Definir el conjunto de datos X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) # resumir el conjunto de datos imprimir(X.forma, y.forma) |
Ejecutando el ejemplo se crea el conjunto de datos y se resume la forma de los componentes de entrada y salida.
A continuación, podemos evaluar un algoritmo de LightGBM en este conjunto de datos.
Evaluaremos el modelo usando la validación cruzada estratificada k-pliegue repetida con tres repeticiones y 10 pliegues. Informaremos la media y la desviación estándar de la precisión del modelo en todas las repeticiones y pliegues.
|
# Evaluar el algoritmo de Lightgbm para la clasificación de numpy importación significa de numpy importación std de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepeatedStratifiedKFold de lightgbm importación LGBMClassifier # Definir el conjunto de datos X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) # Definir el modelo modelo = LGBMClassifier() # Evaluar el modelo cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) n_puntuaciones = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=–1) # Informe de rendimiento imprimir(«Precisión: %.3f (%.3f) % (significa(n_puntuaciones), std(n_puntuaciones))) |
La ejecución del ejemplo informa de la precisión de la media y la desviación estándar del modelo.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
En este caso, podemos ver que el conjunto LightGBM con hiperparámetros predeterminados logra una precisión de clasificación de alrededor del 92,5 por ciento en este conjunto de datos de prueba.
También podemos usar el modelo LightGBM como modelo final y hacer predicciones para la clasificación.
Primero, el conjunto LightGBM se ajusta a todos los datos disponibles, luego el predecir() se puede llamar a la función para hacer predicciones sobre nuevos datos.
El siguiente ejemplo lo demuestra en nuestro conjunto de datos de clasificación binaria.
|
# Hacer predicciones usando lightgbm para la clasificación de sklearn.conjuntos de datos importación make_classification de lightgbm importación LGBMClassifier # Definir el conjunto de datos X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) # Definir el modelo modelo = LGBMClassifier() # Encajar el modelo en todo el conjunto de datos modelo.encajar(X, y) # hacer una sola predicción fila = [[0.2929949,–4.21223056,–1.288332,–2.17849815,–0.64527665,2.58097719,0.28422388,–7.1827928,–1.91211104,2.73729512,0.81395695,3.96973717,–2.66939799,3.34692332,4.19791821,0.99990998,–0.30201875,–4.43170633,–2.82646737,0.44916808] yhat = modelo.predecir([[fila]) imprimir(Clase prevista: %d’. % yhat[[0]) |
La ejecución del ejemplo encaja con el modelo de conjunto LightGBM en todo el conjunto de datos y luego se utiliza para hacer una predicción en una nueva fila de datos, como podríamos hacer al utilizar el modelo en una aplicación.
Ahora que estamos familiarizados con el uso de LightGBM para la clasificación, veamos el API para la regresión.
Conjunto LightGBM para la regresión
En esta sección, veremos el uso del LightGBM para un problema de regresión.
Primero, podemos usar la función make_regression() para crear un problema de regresión sintética con 1.000 ejemplos y 20 características de entrada.
El ejemplo completo figura a continuación.
|
# conjunto de datos de regresión de pruebas de sklearn.conjuntos de datos importación hacer_regresión # Definir el conjunto de datos X, y = make_regression(n_muestras=1000, n_funciones=20, n_informativo=15, ruido=0.1, estado_aleatorio=7) # resumir el conjunto de datos imprimir(X.forma, y.forma) |
Ejecutando el ejemplo se crea el conjunto de datos y se resume la forma de los componentes de entrada y salida.
A continuación, podemos evaluar un algoritmo de LightGBM en este conjunto de datos.
Como hicimos con la última sección, evaluaremos el modelo usando la validación cruzada repetida k-pliegue, con tres repeticiones y 10 pliegues. Informaremos del error medio absoluto (MAE) del modelo en todas las repeticiones y pliegues. La biblioteca de aprendizaje de ciencias hace que el MAE sea negativo, de modo que se maximiza en lugar de minimizarse. Esto significa que los MAE negativos más grandes son mejores y un modelo perfecto tiene un MAE de 0.
El ejemplo completo figura a continuación.
|
# Evaluar el conjunto de Lightgbm para la regresión de numpy importación significa de numpy importación std de sklearn.conjuntos de datos importación make_regression de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepetidoKFold de lightgbm importación LGBMRegressor # Definir el conjunto de datos X, y = make_regression(n_muestras=1000, n_funciones=20, n_informativo=15, ruido=0.1, estado_aleatorio=7) # Definir el modelo modelo = LGBMRegressor() # Evaluar el modelo cv = RepetidoKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) n_puntuaciones = puntaje_valor_cruzado(modelo, X, y, puntuación=‘neg_mean_absolute_error’, cv=cv, n_jobs=–1, error_score=«aumentar) # Informe de rendimiento imprimir(MAE: %.3f (%.3f)’. % (significa(n_puntuaciones), std(n_puntuaciones))) |
La ejecución del ejemplo informa de la precisión de la media y la desviación estándar del modelo.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
En este caso, podemos ver que el conjunto LightGBM con hiperparámetros por defecto alcanza un MAE de unos 60.
También podemos usar el modelo LightGBM como modelo final y hacer predicciones para la regresión.
Primero, el conjunto LightGBM se ajusta a todos los datos disponibles, luego el predecir() se puede llamar a la función para hacer predicciones sobre nuevos datos.
El siguiente ejemplo lo demuestra en nuestro conjunto de datos de regresión.
|
# gradiente lightgbm para hacer predicciones de regresión de sklearn.conjuntos de datos importación make_regression de lightgbm importación LGBMRegressor # Definir el conjunto de datos X, y = make_regression(n_muestras=1000, n_funciones=20, n_informativo=15, ruido=0.1, estado_aleatorio=7) # Definir el modelo modelo = LGBMRegressor() # Encajar el modelo en todo el conjunto de datos modelo.encajar(X, y) # hacer una sola predicción fila = [[0.20543991,–0.97049844,–0.81403429,–0.23842689,–0.60704084,–0.48541492,0.53113006,2.01834338,–0.90745243,–1.85859731,–1.02334791,–0.6877744,0.60984819,–0.70630121,–1.29161497,1.32385441,1.42150747,1.26567231,2.56569098,–0.11154792] yhat = modelo.predecir([[fila]) imprimir(«Predicción: %d % yhat[[0]) |
La ejecución del ejemplo encaja con el modelo de conjunto LightGBM en todo el conjunto de datos y luego se utiliza para hacer una predicción en una nueva fila de datos, como podríamos hacer al utilizar el modelo en una aplicación.
Ahora que estamos familiarizados con el uso del API de scikit-learn para evaluar y usar los conjuntos LightGBM, veamos la configuración del modelo.
Hiperparámetros LightGBM
En esta sección, echaremos un vistazo más de cerca a algunos de los hiperparámetros que debería considerar para la puesta a punto del conjunto LightGBM y su efecto en el rendimiento del modelo.
Hay muchos hiperparámetros que podemos mirar para el LightGBM, aunque en este caso, miraremos el número de árboles y la profundidad de los mismos, la tasa de aprendizaje y el tipo de impulso.
Para un buen consejo general sobre la sintonización de los hiperparámetros de LightGBM, vea la documentación:
Explorar el número de árboles
Un importante hiperparámetro para el algoritmo del conjunto LightGBM es el número de árboles de decisión utilizados en el conjunto.
Recordemos que los árboles de decisión se añaden al modelo de forma secuencial en un esfuerzo por corregir y mejorar las predicciones hechas por los árboles anteriores. Como tal, más árboles son a menudo mejores.
El número de árboles se puede establecer a través de la «n_estimadores«y por defecto a 100.
El siguiente ejemplo explora el efecto del número de árboles con valores entre 10 y 5.000.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
# Explorar el efecto del número de árboles de Lightgbm en el rendimiento de numpy importación significa de numpy importación std de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepeatedStratifiedKFold de lightgbm importación LGBMClassifier de matplotlib importación pyplot # Obtener el conjunto de datos def get_dataset(): X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) volver X, y # Obtener una lista de modelos para evaluar def get_models(): modelos = dict() árboles = [[10, 50, 100, 500, 1000, 5000] para n en árboles: modelos[[str(n)] = LGBMClassifier(n_estimadores=n) volver modelos # Evaluar un modelo dado usando validación cruzada def evaluate_model(modelo): cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) resultados = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=–1) volver resultados # Definir el conjunto de datos X, y = get_dataset() # conseguir que los modelos evalúen modelos = get_models() # Evaluar los modelos y almacenar los resultados resultados, nombres = lista(), lista() para nombre, modelo en modelos.artículos(): resultados = evaluate_model(modelo) resultados.anexar(resultados) nombres.anexar(nombre) imprimir(«>%s %.3f (%.3f) % (nombre, significa(resultados), std(resultados))) # Rendimiento del modelo de la trama para la comparación pyplot.Boxplot(resultados, etiquetas=nombres, showmeans=Verdadero) pyplot.mostrar() |
La ejecución del ejemplo primero reporta la precisión media para cada número configurado de árboles de decisión.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
En este caso, podemos ver que el rendimiento mejora en este conjunto de datos hasta unos 500 árboles, después de lo cual el rendimiento parece nivelarse.
|
>10 0.857 (0.033) >50 0.916 (0.032) >100 0.925 (0.031) >500 0.938 (0.026) >1000 0.938 (0.028) >5000 0.937 (0.028) |
Se crea un gráfico de caja y bigote para la distribución de las puntuaciones de precisión para cada número configurado de árboles.
Podemos ver la tendencia general de aumentar el rendimiento de los modelos y el tamaño de los conjuntos.
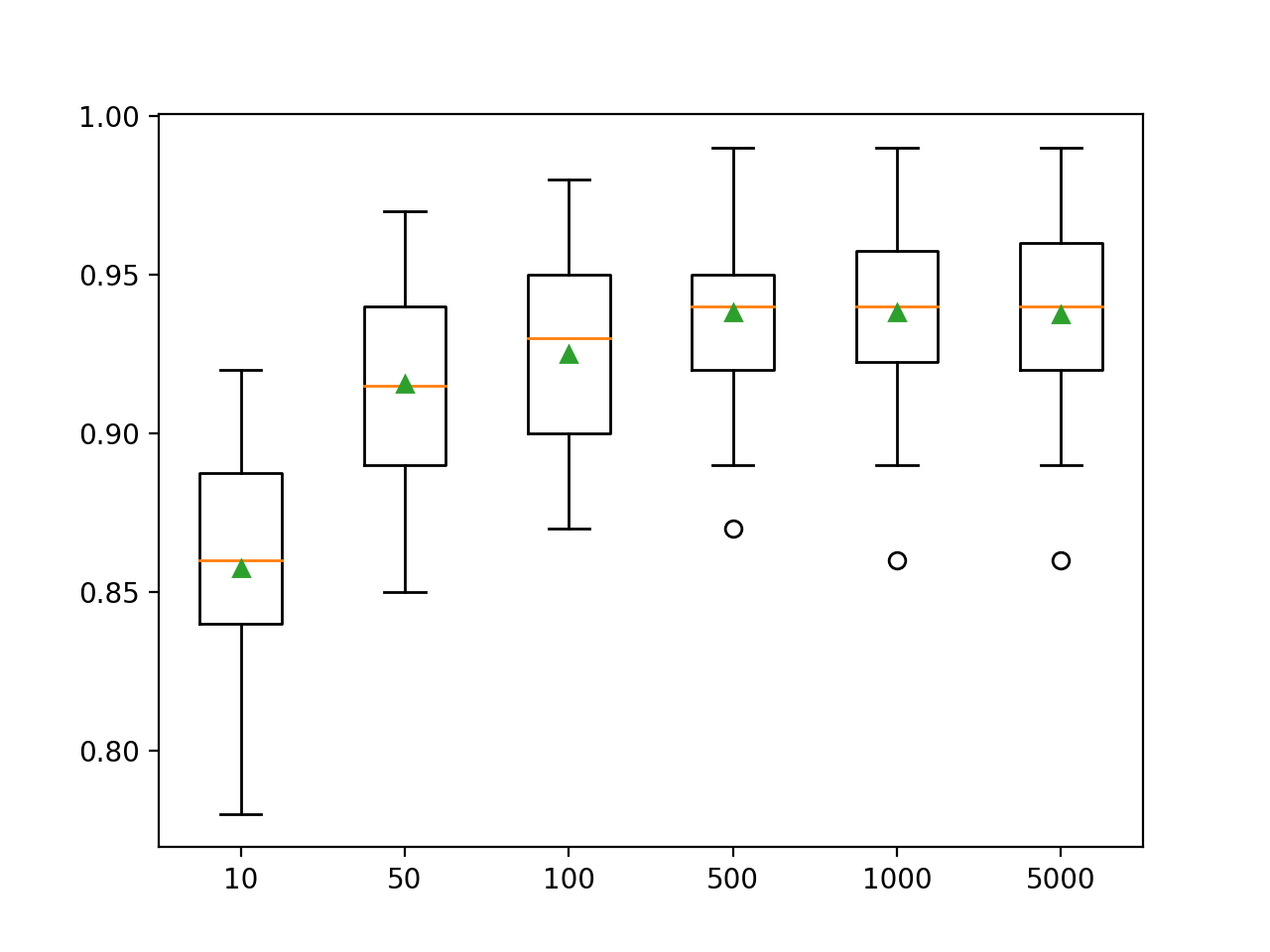
Cuadro de tamaño del conjunto LightGBM vs. Precisión de clasificación
Explorar la profundidad del árbol
Variar la profundidad de cada árbol añadido al conjunto es otro importante hiperparámetro para aumentar el gradiente.
La profundidad del árbol controla cuán especializado está cada árbol en el conjunto de datos de entrenamiento: cuán general o excesivo puede ser. Se prefieren árboles que no sean demasiado superficiales y generales (como el AdaBoost) y no demasiado profundos y especializados (como la agregación de bootstrap).
La potenciación del gradiente generalmente funciona bien con árboles que tienen una profundidad modesta, encontrando un equilibrio entre la habilidad y la generalidad.
La profundidad del árbol se controla a través de la «max_depth«El mecanismo por defecto para controlar la complejidad de los árboles es utilizar el número de nodos de hojas.
Hay dos formas principales de controlar la complejidad de los árboles: la profundidad máxima de los árboles y el número máximo de nodos terminales (hojas) en el árbol. En este caso, estamos explorando el número de hojas, por lo que necesitamos aumentar el número de hojas para apoyar a los árboles más profundos estableciendo el «num_leaves«argumento».
En el ejemplo que figura a continuación se exploran las profundidades de los árboles entre 1 y 10 y el efecto en el rendimiento del modelo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# Explorar el efecto de la profundidad del árbol de la luz en el rendimiento de numpy importación significa de numpy importación std de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepeatedStratifiedKFold de lightgbm importación LGBMClassifier de matplotlib importación pyplot # Obtener el conjunto de datos def get_dataset(): X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) volver X, y # Obtener una lista de modelos para evaluar def get_models(): modelos = dict() para i en rango(1,11): modelos[[str(i)] = LGBMClassifier(max_depth=i, num_leaves=2**i) volver modelos # Evaluar un modelo dado usando validación cruzada def evaluate_model(modelo): cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) resultados = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=–1) volver resultados # Definir el conjunto de datos X, y = get_dataset() # conseguir que los modelos evalúen modelos = get_models() # Evaluar los modelos y almacenar los resultados resultados, nombres = lista(), lista() para nombre, modelo en modelos.artículos(): resultados = evaluate_model(modelo) resultados.anexar(resultados) nombres.anexar(nombre) imprimir(«>%s %.3f (%.3f) % (nombre, significa(resultados), std(resultados))) # Rendimiento del modelo de la trama para la comparación pyplot.Boxplot(resultados, etiquetas=nombres, showmeans=Verdadero) pyplot.mostrar() |
Ejecutando el ejemplo primero se informa de la precisión media para cada profundidad de árbol configurada.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
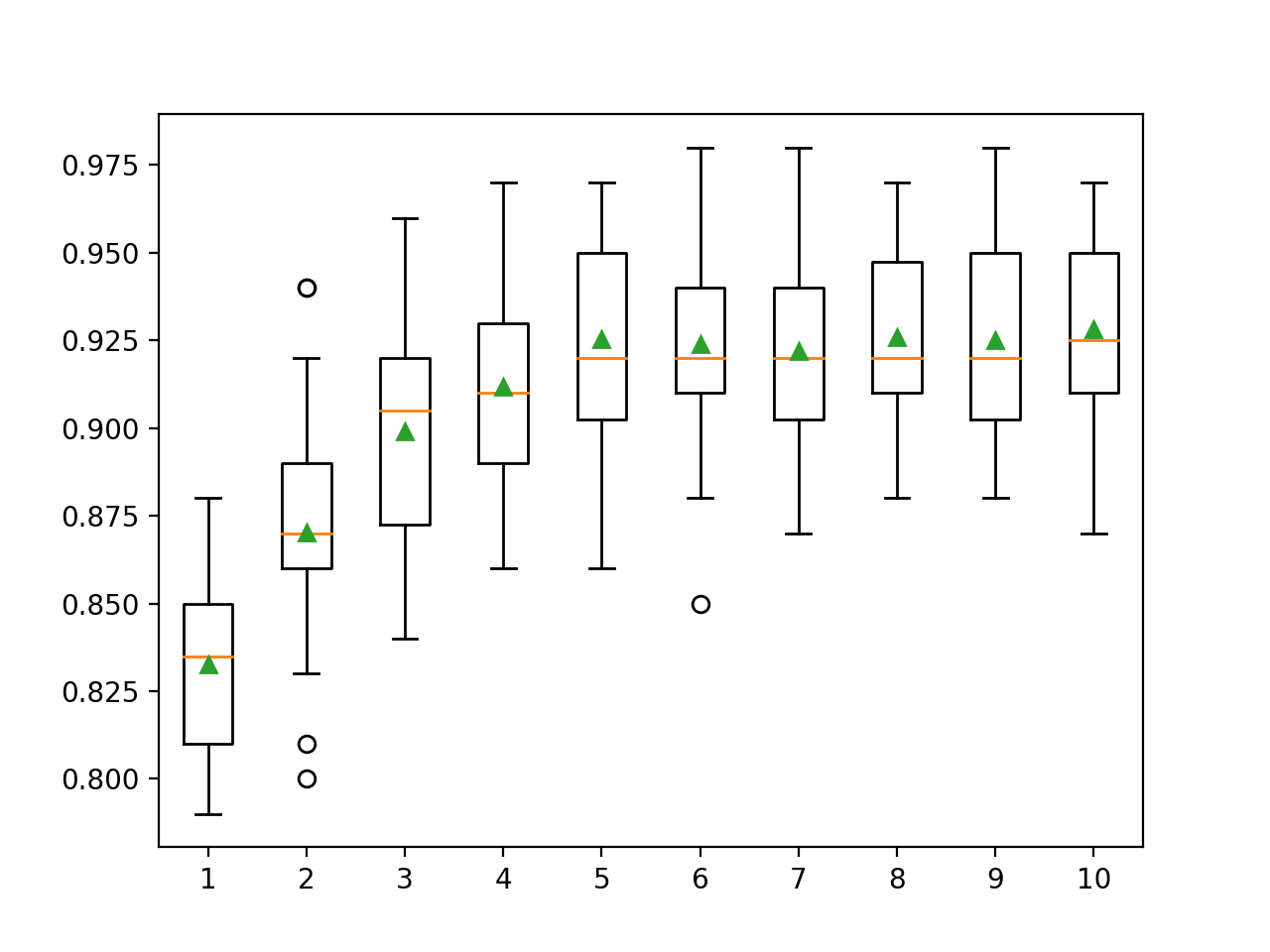
En este caso, podemos ver que el rendimiento mejora con la profundidad del árbol, quizás hasta 10 niveles. Podría ser interesante explorar árboles aún más profundos.
|
>1 0.833 (0.028) >2 0.870 (0.033) >3 0.899 (0.032) >4 0.912 (0.026) >5 0.925 (0.031) >6 0.924 (0.029) >7 0.922 (0.027) >8 0.926 (0.027) >9 0.925 (0.028) >10 0.928 (0.029) |
Se crea un gráfico de caja y bigote para la distribución de las puntuaciones de precisión para cada profundidad de árbol configurada.
Podemos ver la tendencia general de aumentar el rendimiento del modelo con la profundidad del árbol hasta una profundidad de cinco niveles, después de lo cual el rendimiento comienza a ser razonablemente plano.
Recuadro de la profundidad del árbol del conjunto LightGBM vs. Precisión de la clasificación
Explorar el ritmo de aprendizaje
La tasa de aprendizaje controla la cantidad de contribución que cada modelo tiene en la predicción del conjunto.
Las tasas más pequeñas pueden requerir más árboles de decisión en el conjunto.
El ritmo de aprendizaje puede ser controlado a través de la «tasa_de_aprendizaje«…y el valor por defecto es de 0,1.
El siguiente ejemplo explora la tasa de aprendizaje y compara el efecto de los valores entre 0,0001 y 1,0.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
# Explorar el efecto de la tasa de aprendizaje de Lightgbm en el rendimiento de numpy importación significa de numpy importación std de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepeatedStratifiedKFold de lightgbm importación LGBMClassifier de matplotlib importación pyplot # Obtener el conjunto de datos def get_dataset(): X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) volver X, y # Obtener una lista de modelos para evaluar def get_models(): modelos = dict() tarifas = [[0.0001, 0.001, 0.01, 0.1, 1.0] para r en tarifas: clave = ‘%.4f’ % r modelos[[clave] = LGBMClassifier(tasa_de_aprendizaje=r) volver modelos # Evaluar un modelo dado usando validación cruzada def evaluate_model(modelo): cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) resultados = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=–1) volver resultados # Definir el conjunto de datos X, y = get_dataset() # conseguir que los modelos evalúen modelos = get_models() # Evaluar los modelos y almacenar los resultados resultados, nombres = lista(), lista() para nombre, modelo en modelos.artículos(): resultados = evaluate_model(modelo) resultados.anexar(resultados) nombres.anexar(nombre) imprimir(«>%s %.3f (%.3f) % (nombre, significa(resultados), std(resultados))) # Rendimiento del modelo de la trama para la comparación pyplot.Boxplot(resultados, etiquetas=nombres, showmeans=Verdadero) pyplot.mostrar() |
Ejecutando el ejemplo primero se informa de la precisión media para cada tasa de aprendizaje configurada.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
En este caso, podemos ver que una mayor tasa de aprendizaje resulta en un mejor rendimiento en este conjunto de datos. Esperábamos que añadir más árboles al conjunto para las tasas de aprendizaje más pequeñas elevaría aún más el rendimiento.
|
>0.0001 0.800 (0.038) >0.0010 0.811 (0.035) >0.0100 0.859 (0.035) >0.1000 0.925 (0.031) >1.0000 0.928 (0.025) |
Se crea un gráfico de caja y bigote para la distribución de las puntuaciones de precisión para cada tasa de aprendizaje configurada.
Podemos ver la tendencia general de aumentar el rendimiento del modelo con el aumento de la tasa de aprendizaje hasta los grandes valores de 1,0.
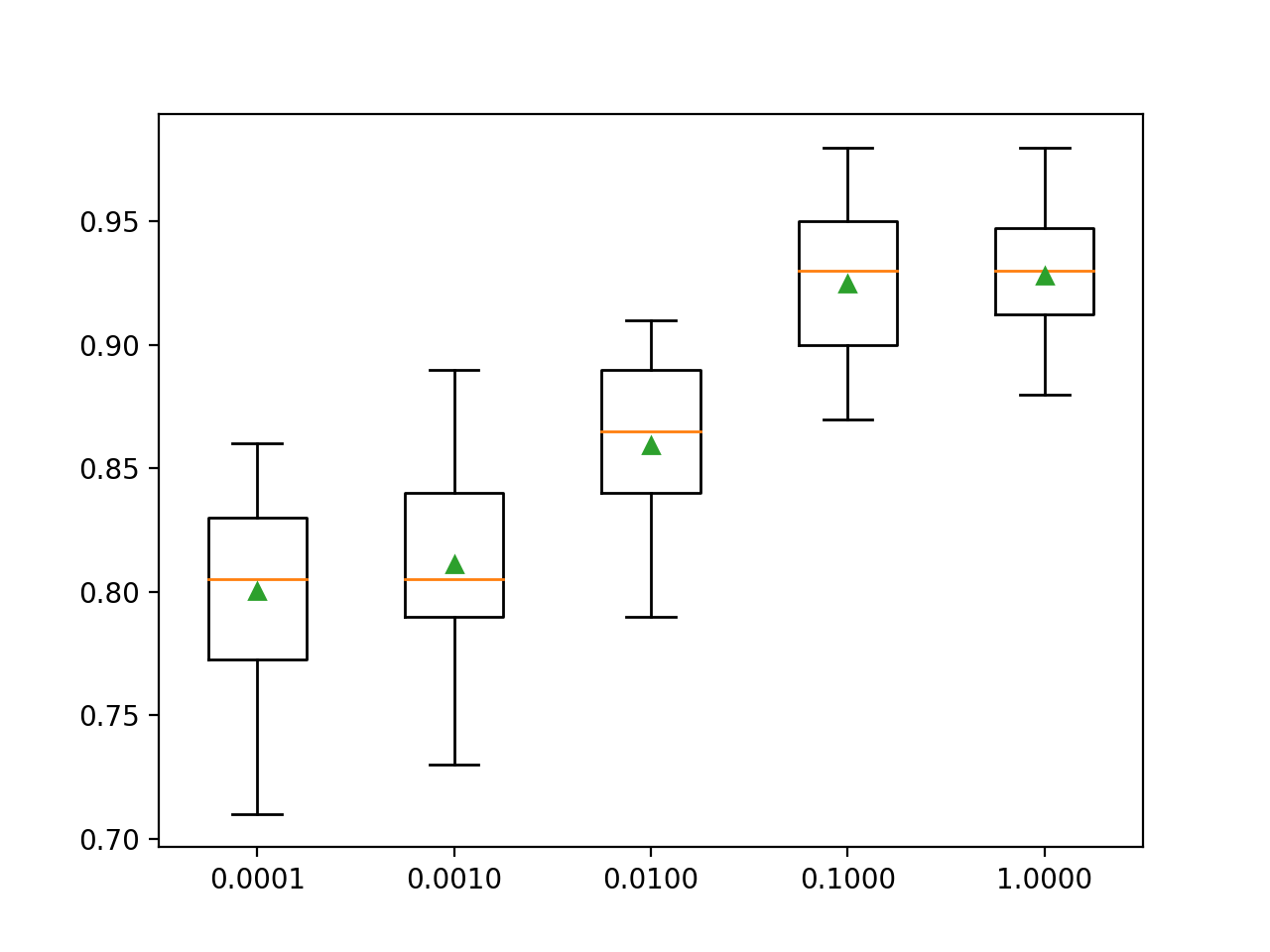
Cuadro de la tasa de aprendizaje de LightGBM vs. Precisión de clasificación
Explorar el tipo de impulso
Una característica de LightGBM es que soporta un número de diferentes algoritmos de refuerzo, referidos como tipos de refuerzo.
El tipo de impulso puede ser especificado a través de la «tipo_de_incremento«y tomar una cadena para especificar el tipo. Las opciones incluyen:
- ‘gbdt‘: Árbol de decisión de potenciación de gradientes (GDBT).
- ‘dardo‘: Los desertores se encuentran con los árboles de regresión aditiva múltiple (DART).
- ‘goss‘: Muestreo de un solo lado basado en el gradiente (GOSS).
El valor por defecto es GDBT, que es el clásico algoritmo de aumento de gradiente.
DART se describe en el documento de 2015 titulado «DART: Dropouts meet Multiple Additive Regression Trees» y, como su nombre lo indica, añade el concepto de abandono del aprendizaje profundo al algoritmo de los árboles de regresión aditiva múltiple (MART), un precursor de los árboles de decisión que potencian el gradiente.
Este algoritmo es conocido por muchos nombres, incluyendo Gradient TreeBoost, Boosted Trees, y Multiple Additive Regression Trees (MART). Usamos este último para referirnos a este algoritmo.
– Los desertores se encuentran con múltiples árboles de regresión aditiva, 2015.
El GOSS se introdujo con el papel y la biblioteca de LightGBM. El enfoque busca utilizar sólo las instancias que resultan en un gran gradiente de error para actualizar el modelo y dejar el resto.
… excluimos una proporción significativa de los casos de datos con pequeños gradientes, y sólo utilizamos el resto para estimar la ganancia de información.
– LightGBM: Un árbol de decisión de impulso de gradiente altamente eficiente, 2017.
En el ejemplo que figura a continuación se compara el LightGBM del conjunto de datos de clasificación sintética con las tres técnicas clave de potenciación.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
# Explorar el efecto del tipo de aumento de la luz en el rendimiento de numpy importación arange de numpy importación significa de numpy importación std de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepeatedStratifiedKFold de lightgbm importación LGBMClassifier de matplotlib importación pyplot # Obtener el conjunto de datos def get_dataset(): X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=7) volver X, y # Obtener una lista de modelos para evaluar def get_models(): modelos = dict() tipos = [[«gbdt, «dardo, «goss] para t en tipos: modelos[[t] = LGBMClassifier(tipo_de_incremento=t) volver modelos # Evaluar un modelo dado usando validación cruzada def evaluate_model(modelo): cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) resultados = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=–1) volver resultados # Definir el conjunto de datos X, y = get_dataset() # conseguir que los modelos evalúen modelos = get_models() # Evaluar los modelos y almacenar los resultados resultados, nombres = lista(), lista() para nombre, modelo en modelos.artículos(): resultados = evaluate_model(modelo) resultados.anexar(resultados) nombres.anexar(nombre) imprimir(«>%s %.3f (%.3f) % (nombre, significa(resultados), std(resultados))) # Rendimiento del modelo de la trama para la comparación pyplot.Boxplot(resultados, etiquetas=nombres, showmeans=Verdadero) pyplot.mostrar() |
Ejecutando el ejemplo primero se informa de la precisión media para cada tipo de impulso configurado.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
En este caso, podemos ver que el método de refuerzo por defecto funcionó mejor que las otras dos técnicas que fueron evaluadas.
|
>gbdt 0,925 (0,031) >dardo 0.912 (0.028) >goss 0.918 (0.027) |
Se crea un gráfico de caja y bigote para la distribución de las puntuaciones de precisión para cada método de potenciación configurado, lo que permite comparar las técnicas directamente.
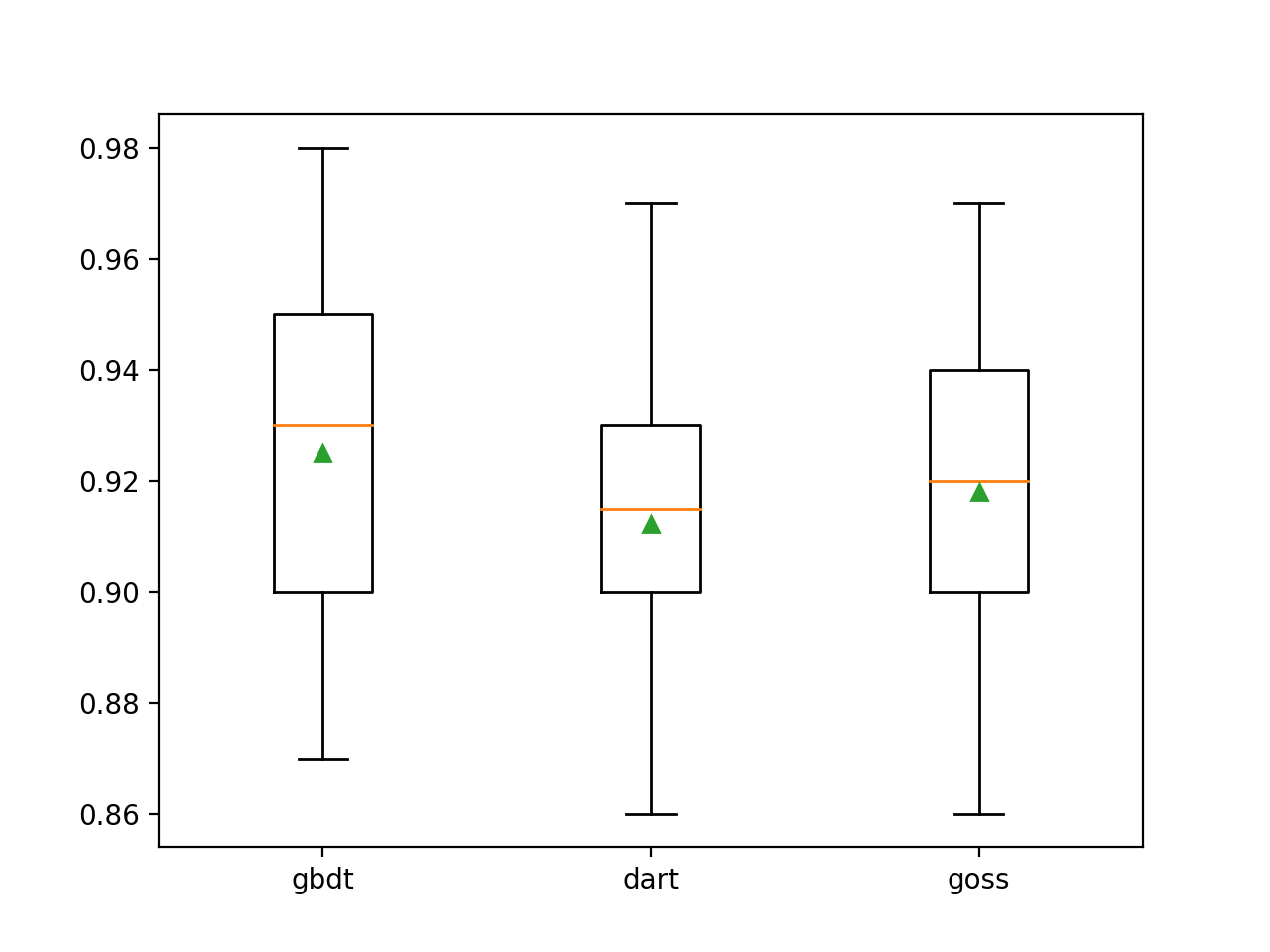
Recuadro de la caja del tipo de refuerzo de LightGBM contra la precisión de la clasificación
Más lecturas
Esta sección proporciona más recursos sobre el tema si desea profundizar en él.
Tutoriales relacionados
Documentos
APIs
Artículos
Resumen
En este tutorial, descubriste cómo desarrollar conjuntos de máquinas potenciadoras de gradientes de luz para la clasificación y la regresión.
Específicamente, aprendiste:
- Light Gradient Boosted Machine (LightGBM) es una eficiente implementación de código abierto del algoritmo de conjunto de aumento de gradiente estocástico.
- Cómo desarrollar conjuntos LightGBM para la clasificación y la regresión con la API de aprendizaje de ciencias.
- Cómo explorar el efecto de los hiperparámetros del modelo LightGBM en el rendimiento del modelo.
¿Tiene alguna pregunta?
Haga sus preguntas en los comentarios de abajo y haré lo posible por responder.