
Los algoritmos de aprendizaje automático, como la regresión logística y las máquinas de vectores de apoyo, están diseñados para problemas de clasificación de dos clases (binarias).
Como tal, estos algoritmos deben ser modificados para problemas de clasificación de múltiples clases (más de dos) o no ser utilizados en absoluto. El Corrección de errores en los códigos de salida es una técnica que permite reenmarcar un problema de clasificación de clases múltiples como problemas de clasificación binaria múltiple, lo que permite utilizar directamente modelos de clasificación binaria nativos.
A diferencia de los métodos uno contra uno y uno contra uno que ofrecen una solución similar al dividir un problema de clasificación de múltiples clases en un número fijo de problemas de clasificación binaria, la técnica de códigos de salida de corrección de errores permite codificar cada clase como un número arbitrario de problemas de clasificación binaria. Cuando se utiliza una representación sobredeterminada, permite que los modelos adicionales actúen como predicciones de «corrección de errores» que pueden dar lugar a un mejor rendimiento predictivo.
En este tutorial, descubrirá cómo utilizar los códigos de salida de corrección de errores para la clasificación.
Después de completar este tutorial, lo sabrás:
- La corrección de errores en los códigos de salida es una técnica para utilizar modelos de clasificación binaria en tareas de predicción de clasificación de clases múltiples.
- Cómo ajustar, evaluar y utilizar los modelos de clasificación de códigos de salida de corrección de errores para hacer predicciones.
- Cómo sintonizar y evaluar diferentes valores para el número de bits por clase de hiperparámetro utilizado por los códigos de salida de corrección de errores.
Empecemos.

Códigos de salida de corrección de errores (ECOC) para el aprendizaje automático
Foto de Fred Hsu, algunos derechos reservados.
Resumen del Tutorial
Este tutorial está dividido en tres partes; son:
- Corrección de errores en los códigos de salida
- Evaluar y utilizar los clasificadores ECOC
- Sintonizar el número de bits por clase
Corrección de errores en los códigos de salida
Las tareas de clasificación son aquellas en las que una etiqueta es predictiva para una determinada variable de entrada.
Las tareas de clasificación binaria son aquellos problemas de clasificación en los que el objetivo contiene dos valores, mientras que los problemas de clasificación multiclase son aquellos que tienen más de dos etiquetas de clase de objetivo.
Se han desarrollado muchos modelos de aprendizaje por máquina para la clasificación binaria, aunque pueden requerir modificaciones para trabajar con problemas de clasificación de clases múltiples. Por ejemplo, las máquinas de regresión logística y de vector de apoyo se diseñaron específicamente para la clasificación binaria.
Varios algoritmos de aprendizaje de máquinas, como el SVM, fueron diseñados originalmente para resolver sólo tareas de clasificación binaria.
– Página 133, Clasificación de patrones usando métodos de ensamblaje, 2010.
En lugar de limitar la elección de los algoritmos o adaptarlos a problemas de múltiples clases, un enfoque alternativo consiste en reformular el problema de clasificación de múltiples clases como problemas de clasificación binaria múltiple. Dos métodos comunes que pueden utilizarse para lograrlo son las técnicas de uno contra uno (OvR) y uno contra uno (OvO).
- OvR…divide un problema multiclase en un problema binario por clase.
- OvOdivide un problema de varias clases en un problema binario por cada par de clases.
Una vez dividido en subtareas, se puede ajustar un modelo de clasificación binaria en cada tarea y se puede tomar como predicción el modelo con la mayor respuesta.
Tanto el OvR como el OvO pueden considerarse como un tipo de modelo de aprendizaje en conjunto, dado que múltiples modelos separados son adecuados para una tarea de modelación predictiva y se utilizan en conjunto para hacer una predicción. En ambos casos, la predicción del «miembros del conjunto» es un simple ganador, tomar todo el enfoque.
… convertir la tarea multiclase en un conjunto de tareas de clasificación binaria, cuyos resultados se combinan.
– Página 134, Clasificación de patrones usando métodos de ensamblaje, 2010.
Para más información sobre los modelos de uno contra uno y uno contra uno, vea el tutorial:
Un enfoque relacionado es preparar una codificación binaria (por ejemplo, una cadena de bits) para representar cada clase del problema. Cada bit de la cadena puede predecirse mediante un problema de clasificación binaria separado. Arbitrariamente, se pueden elegir codificaciones de longitudes para un problema de clasificación multiclase determinado.
Para ser claros, cada modelo recibe el patrón de entrada completo y sólo predice una posición en la cadena de salida. Durante el entrenamiento, cada modelo puede ser entrenado para producir la salida correcta 0 o 1 para la tarea de clasificación binaria. Luego se puede hacer una predicción para nuevos ejemplos utilizando cada modelo para hacer una predicción de la entrada para crear la cadena binaria, y luego comparar la cadena binaria con la codificación conocida de cada clase. La codificación de la clase que tiene la menor distancia a la predicción se elige entonces como salida.
A cada clase se le atribuye una palabra clave de longitud l. Comúnmente, el tamaño de las palabras clave tiene más bits de los necesarios para representar de manera única a cada clase.
– Página 138, Clasificación de patrones usando métodos de ensamblaje, 2010.
Se trata de un enfoque interesante que permite que la representación de las clases sea más elaborada de lo que se requiere (tal vez sobredeterminada) en comparación con una codificación de una sola vez e introduce la redundancia en la representación y el modelado del problema. Esto es intencional ya que los bits adicionales en la representación actúan como códigos de corrección de errores para arreglar, corregir o mejorar la predicción.
… la idea es que los bits redundantes de «corrección de errores» permiten algunas inexactitudes, y pueden mejorar el rendimiento.
– Página 606, Los elementos del aprendizaje estadístico, 2016.
Esto le da a la técnica su nombre: códigos de salida de corrección de errores, o ECOC para abreviar.
Los Códigos de Salida con Corrección de Errores (CEC) son un enfoque simple pero poderoso para tratar un problema de múltiples clases basado en la combinación de clasificadores binarios.
– Página 90, Métodos de ensamblaje, 2012.
Se puede tener cuidado para asegurar que cada clase codificada tenga una codificación de cadena binaria muy diferente. Se ha explorado un conjunto de diferentes esquemas de codificación, así como métodos específicos para construir las codificaciones para asegurar que estén suficientemente separadas en el espacio de codificación. Es interesante que se ha descubierto que las codificaciones aleatorias funcionan quizás igual de bien.
… analizó el enfoque ECOC, y mostró que la asignación de códigos aleatorios funcionaba tan bien como los códigos de corrección de errores óptimamente construidos
– Página 606, Los elementos del aprendizaje estadístico, 2016.
Para una revisión detallada de los diferentes esquemas de codificación y métodos de mapeo de cadenas predichas a clases codificadas, recomiendo el Capítulo 6 «Corrección de errores en los códigos de salida» del libro «Clasificación de patrones usando métodos de conjunto».
Evaluar y utilizar los clasificadores ECOC
La biblioteca de aprendizaje científico proporciona una implementación de ECOC a través de la clase OutputCodeClassifier.
La clase toma como argumento el modelo a utilizar para ajustar cada clasificador binario, y se puede utilizar cualquier modelo de aprendizaje de máquina. En este caso, utilizaremos un modelo de regresión logística, destinado a la clasificación binaria.
La clase también proporciona la «tamaño_de_código«que especifica el tamaño de la codificación de las clases como un múltiplo del número de clases, por ejemplo, el número de bits a codificar para cada etiqueta de clase.
Por ejemplo, si quisiéramos una codificación con cadenas de bits con una longitud de 6 bits, y tuviéramos tres clases, entonces podemos especificar el tamaño de la codificación como 2:
- longitud_de_codificación = tamaño_de_codificación * clases_numéricas
- longitud_de_codificación = 2 * 3
- longitud_de_codificación = 6
El ejemplo que figura a continuación demuestra cómo definir un ejemplo de la OutputCodeClassifier con 2 bits por clase y usando un modelo de LogisticRegression para cada bit de la codificación.
|
... # Definir el modelo de clasificación binaria modelo = LogisticRegression() # Definir el modelo ecoc ecoc = OutputCodeClassifier(modelo, tamaño_de_código=2, estado_aleatorio=1) |
Aunque hay muchas maneras sofisticadas de construir la codificación para cada clase, la OutputCodeClassifier La clase selecciona una codificación de cadena de bits al azar para cada clase, al menos en el momento de la escritura.
Podemos explorar el uso de la OutputCodeClassifier en un problema de clasificación sintética de clases múltiples.
Podemos usar la función make_classification() para definir un problema de clasificación multiclase con 1.000 ejemplos, 20 características de entrada y tres clases.
El siguiente ejemplo demuestra cómo crear el conjunto de datos y resumir el número de filas, columnas y clases en el conjunto de datos.
|
# Conjunto de datos de clasificación multiclase de colecciones importación Contador de sklearn.conjuntos de datos importación hacer_clasificación # Definir el conjunto de datos X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=1, n_clases=3) # resumir el conjunto de datos imprimir(X.forma, y.forma) # resumir el número de clases imprimir(Contador(y)) |
Ejecutando el ejemplo se crea el conjunto de datos y se informa del número de filas y columnas, confirmando que el conjunto de datos fue creado como se esperaba.
A continuación, se informa del número de ejemplos de cada clase, mostrando un número casi igual de casos para cada una de las tres clases configuradas.
|
(1000, 20) (1000,) Contador({2: 335, 1: 333, 0: 332}) |
A continuación, podemos evaluar un modelo de códigos de salida de corrección de errores en el conjunto de datos.
Usaremos una regresión logística con 2 bits por clase como definimos anteriormente. El modelo será evaluado usando una validación cruzada estratificada k-pliegue repetida con tres repeticiones y 10 pliegues. Resumiremos el rendimiento del modelo utilizando la media y la desviación estándar de la precisión de la clasificación en todas las repeticiones y pliegues.
|
... # Definir el procedimiento de evaluación cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) # Evaluar el modelo y recoger las puntuaciones n_puntuaciones = puntaje_valor_cruzado(ecoc, X, y, puntuación=«exactitud, cv=cv, n_jobs=–1) # Resumir la actuación imprimir(«Precisión: %.3f (%.3f) % (significa(n_puntuaciones), std(n_puntuaciones))) |
A continuación se muestra el ejemplo completo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# Evaluar los códigos de salida de corrección de errores para la clasificación de clases múltiples de numpy importación significa de numpy importación std de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepeatedStratifiedKFold de sklearn.modelo_lineal importación LogisticRegression de sklearn.multiclase importación OutputCodeClassifier # Definir el conjunto de datos X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=1, n_clases=3) # Definir el modelo de clasificación binaria modelo = LogisticRegression() # Definir el modelo ecoc ecoc = OutputCodeClassifier(modelo, tamaño_de_código=2, estado_aleatorio=1) # Definir el procedimiento de evaluación cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) # Evaluar el modelo y recoger las puntuaciones n_puntuaciones = puntaje_valor_cruzado(ecoc, X, y, puntuación=«exactitud, cv=cv, n_jobs=–1) # Resumir la actuación imprimir(«Precisión: %.3f (%.3f) % (significa(n_puntuaciones), std(n_puntuaciones))) |
Ejecutando el ejemplo se define el modelo y se evalúa en nuestro conjunto de datos de clasificación sintética multiclase usando el procedimiento de prueba definido.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
En este caso, podemos ver que el modelo alcanzó una precisión media de clasificación de alrededor del 76,6 por ciento.
Podemos elegir usar esto como nuestro modelo final.
Esto requiere que ajustemos el modelo a todos los datos disponibles y lo usemos para hacer predicciones sobre nuevos datos.
En el ejemplo que figura a continuación se ofrece un ejemplo completo de cómo ajustar y utilizar un modelo de salida con corrección de errores como modelo final.
|
# Usar el modelo de códigos de salida de corrección de errores como modelo final y hacer una predicción de sklearn.conjuntos de datos importación make_classification de sklearn.modelo_lineal importación LogisticRegression de sklearn.multiclase importación OutputCodeClassifier # Definir el conjunto de datos X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=1, n_clases=3) # Definir el modelo de clasificación binaria modelo = LogisticRegression() # Definir el modelo ecoc ecoc = OutputCodeClassifier(modelo, tamaño_de_código=2, estado_aleatorio=1) # Encajar el modelo en todo el conjunto de datos ecoc.encajar(X, y) # hacer una sola predicción fila = [[[[0.04339387, 2.75542632, –3.79522705, –0.71310994, –3.08888853, –1.2963487, –1.92065166, –3.15609907, 1.37532356, 3.61293237, 1.00353523, –3.77126962, 2.26638828, –10.22368666, –0.35137382, 1.84443763, 3.7040748, 2.50964286, 2.18839505, –2.31211692]] yhat = ecoc.predecir(fila) imprimir(Clase prevista: %d’. % yhat[[0]) |
La ejecución del ejemplo se ajusta al modelo ECOC en todo el conjunto de datos y utiliza el modelo para predecir la etiqueta de la clase para una sola fila de datos.
En este caso, podemos ver que el modelo predijo la etiqueta de clase 0.
Ahora que estamos familiarizados con la forma de ajustar y utilizar el modelo ECOC, vamos a ver más de cerca cómo configurarlo.
Sintonizar el número de bits por clase
El hiperparámetro clave del modelo ECOC es la codificación de las etiquetas de clase.
Esto incluye propiedades como:
- La elección de la representación (bits, números reales, etc.)
- La codificación de cada etiqueta de clase (aleatoria, etc.)
- La longitud de la representación (número de bits, etc.)
- Cómo se asignan las predicciones a las clases (distancia, etc.)
La implementación del Clasificador de Códigos de Salida (OutputCodeClassifier) no proporciona actualmente mucho control sobre estos elementos.
El elemento sobre el que da control es el número de bits usados para codificar cada etiqueta de clase.
En esta sección, podemos realizar una búsqueda manual en la cuadrícula a través de diferentes números de bits por etiqueta de clase y comparar los resultados. Esto proporciona una plantilla que puede adaptar y utilizar en su propio proyecto.
Primero, podemos definir una función para crear y devolver el conjunto de datos.
|
# Obtener el conjunto de datos def get_dataset(): X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=1, n_clases=3) volver X, y |
Podemos entonces definir una función que creará una colección de modelos para evaluar.
Cada modelo será un ejemplo de la OutputCodeClassifier usando una Regresión Logística para cada problema de clasificación binaria. Configuraremos el tamaño_de_código de cada modelo para ser diferente, con valores que van de 1 a 20.
|
# Obtener una lista de modelos para evaluar def get_models(): modelos = dict() para i en rango(1,21): # Crear un modelo modelo = LogisticRegression() # Crear un clasificador de código de salida que corrija los errores modelos[[str(i)] = OutputCodeClassifier(modelo, tamaño_de_código=i, estado_aleatorio=1) volver modelos |
Podemos evaluar cada modelo utilizando la validación cruzada relacionada con el pliegue k, como hicimos en la sección anterior, para dar una muestra de las puntuaciones de la precisión de la clasificación.
|
# Evaluar un modelo dado usando validación cruzada def evaluate_model(modelo): cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) resultados = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=–1) volver resultados |
Podemos informar la media y la desviación estándar de las puntuaciones para cada configuración y trazar las distribuciones como gráficos de caja y bigote uno al lado del otro para comparar visualmente los resultados.
|
... # Evaluar los modelos y almacenar los resultados resultados, nombres = lista(), lista() para nombre, modelo en modelos.artículos(): resultados = evaluate_model(modelo) resultados.anexar(resultados) nombres.anexar(nombre) imprimir(«>%s %.3f (%.3f) % (nombre, significa(resultados), std(resultados))) # Rendimiento del modelo de la trama para la comparación pyplot.Boxplot(resultados, etiquetas=nombres, showmeans=Verdadero) pyplot.mostrar() |
A continuación se muestra el ejemplo completo de la comparación de la clasificación ECOC con una cuadrícula del número de bits por clase.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
# Comparar el número de bits por clase para corregir errores de clasificación del código de salida de numpy importación significa de numpy importación std de sklearn.conjuntos de datos importación make_classification de sklearn.model_selection importación puntaje_valor_cruzado de sklearn.model_selection importación RepeatedStratifiedKFold de sklearn.modelo_lineal importación LogisticRegression de sklearn.multiclase importación OutputCodeClassifier de matplotlib importación pyplot # Obtener el conjunto de datos def get_dataset(): X, y = make_classification(n_muestras=1000, n_funciones=20, n_informativo=15, n_redundante=5, estado_aleatorio=1, n_clases=3) volver X, y # Obtener una lista de modelos para evaluar def get_models(): modelos = dict() para i en rango(1,21): # Crear un modelo modelo = LogisticRegression() # Crear un clasificador de código de salida que corrija los errores modelos[[str(i)] = OutputCodeClassifier(modelo, tamaño_de_código=i, estado_aleatorio=1) volver modelos # Evaluar un modelo dado usando validación cruzada def evaluate_model(modelo): cv = RepeatedStratifiedKFold(n_splits=10, n_repeticiones=3, estado_aleatorio=1) resultados = puntaje_valor_cruzado(modelo, X, y, puntuación=«exactitud, cv=cv, n_jobs=–1) volver resultados # Definir el conjunto de datos X, y = get_dataset() # conseguir que los modelos evalúen modelos = get_models() # Evaluar los modelos y almacenar los resultados resultados, nombres = lista(), lista() para nombre, modelo en modelos.artículos(): resultados = evaluate_model(modelo) resultados.anexar(resultados) nombres.anexar(nombre) imprimir(«>%s %.3f (%.3f) % (nombre, significa(resultados), std(resultados))) # Rendimiento del modelo de la trama para la comparación pyplot.Boxplot(resultados, etiquetas=nombres, showmeans=Verdadero) pyplot.mostrar() |
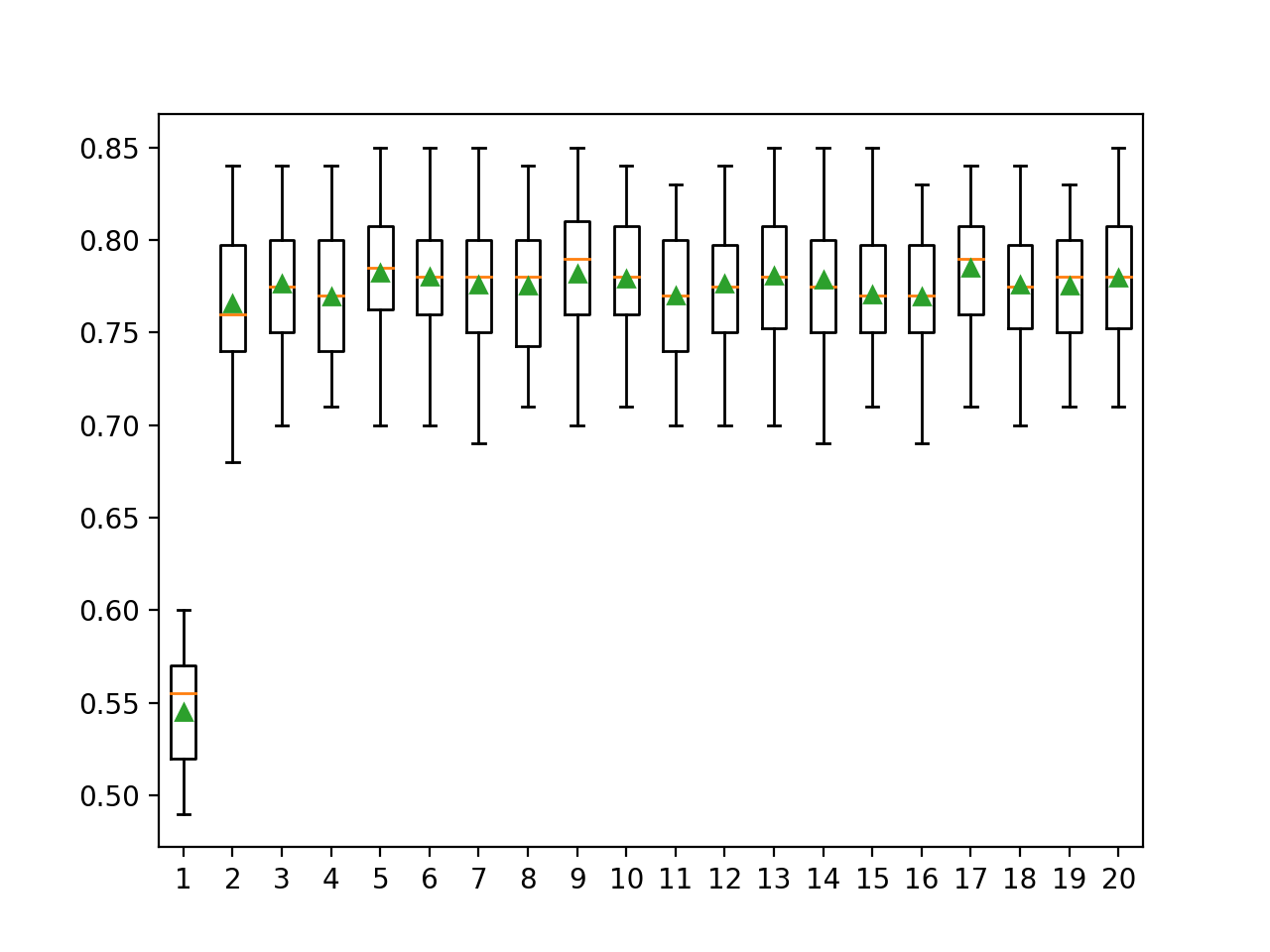
Al ejecutar el ejemplo primero se evalúa cada configuración del modelo y se informa de la media y la desviación estándar de las puntuaciones de precisión.
Nota: Sus resultados pueden variar dada la naturaleza estocástica del algoritmo o el procedimiento de evaluación, o las diferencias en la precisión numérica. Considere ejecutar el ejemplo unas cuantas veces y compare el resultado promedio.
En este caso, podemos ver que tal vez 5 o 6 bits por clase resultan en el mejor desempeño con puntuaciones de precisión media reportadas de alrededor de 78,2 por ciento y 78,0 por ciento respectivamente. También vemos buenos resultados para 9, 13, 17 y 20 bits por clase, con quizás 17 bits por clase dando el mejor resultado de alrededor del 78,5 por ciento.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
>1 0.545 (0.032) >2 0.766 (0.037) >3 0.776 (0.036) >4 0.769 (0.035) >5 0.782 (0.037) >6 0.780 (0.037) >7 0.776 (0.039) >8 0.775 (0.036) >9 0.782 (0.038) >10 0.779 (0.036) >11 0.770 (0.033) >12 0.777 (0.037) >13 0.781 (0.037) >14 0.779 (0.039) >15 0.771 (0.033) >16 0.769 (0.035) >17 0.785 (0.034) >18 0.776 (0.038) >19 0.776 (0.034) >20 0.780 (0.038) |
Se crea una figura que muestra las gráficas de caja y bigote para las puntuaciones de precisión de cada configuración de modelo.
Podemos ver que además de un valor de 1, el número de bits por clase ofrece resultados similares en términos de dispersión y de precisión media que se agrupan alrededor del 77 por ciento. Esto sugiere que el enfoque es razonablemente estable en todas las configuraciones.
Parcelas de caja y bigote de bits por clase vs. distribución de la precisión de la clasificación para la CEC
Más lecturas
Esta sección proporciona más recursos sobre el tema si desea profundizar en él.
Tutoriales relacionados
Documentos
Libros
APIs
Resumen
En este tutorial, descubriste cómo usar códigos de salida de corrección de errores para la clasificación.
Específicamente, aprendiste:
- La corrección de errores en los códigos de salida es una técnica para utilizar modelos de clasificación binaria en tareas de predicción de clasificación de clases múltiples.
- Cómo ajustar, evaluar y utilizar los modelos de clasificación de códigos de salida de corrección de errores para hacer predicciones.
- Cómo sintonizar y evaluar diferentes valores para el número de bits por clase de hiperparámetro utilizado por los códigos de salida de corrección de errores.
¿Tiene alguna pregunta?
Haga sus preguntas en los comentarios de abajo y haré lo posible por responder.