

Los modelos de lenguaje preentrenado (LM) a gran escala han mostrado resultados prometedores en tareas simples de generación de código, pero tienen varias limitaciones: entrenar modelos con solo objetivos de predicción del siguiente token conduce a la acumulación de errores y descuidar las señales potencialmente significativas de las pruebas unitarias da como resultado resultados deficientes. capacidad de generalización cuando se enfrenta a tareas de codificación complejas e invisibles.
Un equipo de Salesforce Research aborda estos problemas en el nuevo documento CodeRL: Dominar la generación de código a través de modelos preentrenados y aprendizaje de refuerzo profundoproponiendo CodeRL, un marco novedoso para tareas de síntesis de programas que emplea LM preentrenados y aprendizaje de refuerzo profundo (RL) y logra un rendimiento de vanguardia en el desafiante punto de referencia de APPS mientras demuestra impresionantes capacidades de transferencia de disparo cero.
El equipo amplía la arquitectura de transformador codificador-descodificador preentrenado unificado de Salesforce CodeT5 (Wang et al., 2021) como la columna vertebral de CodeRL. Aunque las tareas de preentrenamiento de CodeT5, como la predicción de intervalo enmascarado (MSP), pueden beneficiar las tareas de comprensión del código, no necesariamente se alinean con los objetivos de síntesis del programa. Para mitigar esto, se integra una tarea de preentrenamiento de predicción del siguiente token (NTP) en CodeT5 para muestrear uniformemente una ubicación de pivote para cada muestra de código, luego pasar el contenido que precede al pivote al codificador y el contenido restante al decodificador.
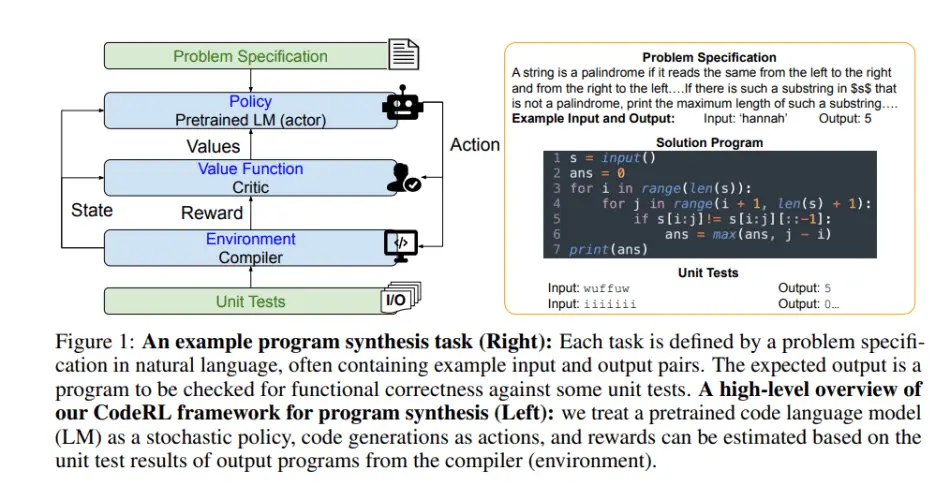
Los investigadores formulan la síntesis del programa de CodeRL como un problema de RL e introducen un enfoque actor-crítico para mejorar el rendimiento del modelo utilizando las señales de prueba unitaria tanto en la optimización del modelo como en los procesos de generación.
El equipo realizó experimentos en el desafiante punto de referencia de generación de código APPS (Estándar de progreso de programación automatizado) (Hendrycks et al., 2021) para evaluar el rendimiento del CodeRL propuesto; y usó el punto de referencia MBPP (Problemas de programación en su mayoría básicos) (Austin et al., 2021) para evaluar su capacidad de disparo cero.
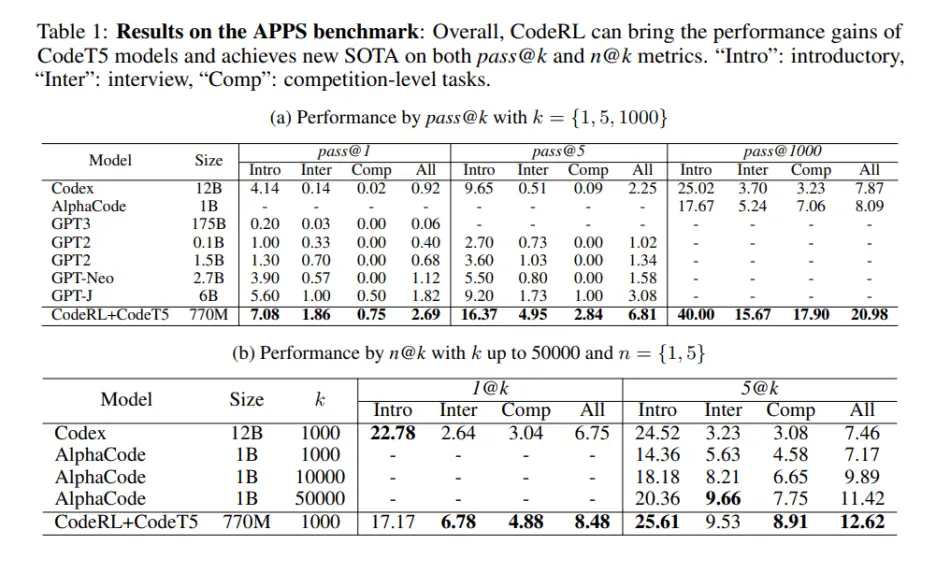
En APPS, los investigadores compararon sus modelos con sólidas líneas de base convencionales que incluían GPT-2, GPT-Neo, GPT3, Codex y AlphaCode, donde CodeRL con CodeT5 logró nuevos resultados SOTA de 2,69 % aprobado@1, 6,81 % aprobado@5 y 20,98 por ciento aprobado@1000.
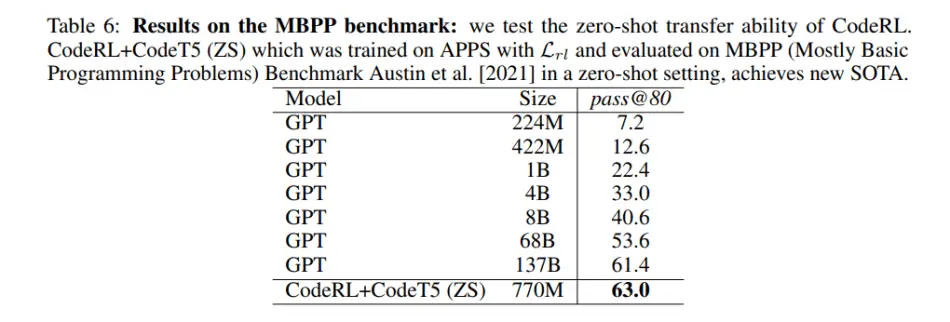
En MBPP, CodeRL con CodeT5 obtuvo un rendimiento de tiro cero sorprendentemente bueno, logrando un nuevo SOTA del 63,0 por ciento de aprobación a 80 sobre el 61,4 por ciento de aprobación a 80 de GPT-137B.
Este trabajo muestra que el método CodeRL puede aprovechar de manera efectiva las señales de prueba unitaria para llevar el rendimiento de generación de código a un nuevo rendimiento SOTA y lograr sólidas capacidades de transferencia de disparo cero.
El código está disponible en el GitHub del proyecto. El papel CodeRL: Dominar la generación de código a través de modelos preentrenados y aprendizaje de refuerzo profundo está en arXiv.
Autor: Hécate Él | Editor: Michael Sarazen

Sabemos que no quiere perderse ninguna noticia o avance de investigación. Suscríbete a nuestro popular boletín IA global sincronizada semanalmente para recibir actualizaciones semanales de IA.
Como esto:
Cargando…