
El aprendizaje por refuerzo (RL) se ha utilizado con éxito para resolver tareas que
tienen una función de recompensa bien definida: piense en AlphaZero para Go, OpenAI Five para
Dota o AlphaStar para StarCraft. Sin embargo, en muchas situaciones prácticas
no tiene una función de recompensa bien definida. Incluso una tarea tan aparentemente
tan sencillo como limpiar una habitación tiene muchos casos sutiles: si una empresa
tarjeta con un trozo de goma de mascar tirarse a la basura, o podría tener un contenido sentimental
¿valor? ¿Debería lavarse la ropa en el suelo o devolverla al
¿armario? ¿Dónde se supone que deben almacenarse los cuadernos? Incluso cuando estos aspectos de
una tarea ha sido aclarada, traducirla en una recompensa no es trivial: si
otorgar recompensas cada vez que barre la basura, entonces el agente podría tirar la
la basura vuelve a sacarla para que pueda barrerla de nuevo.
Alternativamente, podemos intentar aprender una función de recompensa a partir de la retroalimentación humana sobre
el comportamiento del agente. Por ejemplo, Deep RL de Human Preferences
aprende una función de recompensa a partir de comparaciones por pares de videoclips de la
comportamiento del agente. Sin embargo, desafortunadamente, este enfoque puede ser muy costoso:
entrenar a un guepardo MuJoCo para que corra hacia adelante requiere que un humano proporcione 750
comparaciones.

En cambio, proponemos un algoritmo que puede aprender una política sin ningún humano
función de supervisión o recompensa, mediante el uso de información implícitamente disponible en
el estado del mundo. Por ejemplo, aprendemos una política que equilibra esta
Guepardo en su pata delantera de un solo estado en el que se encuentra en equilibrio.
Los humanos parecen inferir lo que otras personas quieren sin necesidad de mucho
supervisión. ¿Cómo lo hacemos? Como ejemplo concreto, imaginemos que
entras en una habitación y ves esto:

Probablemente vas a tener mucho más cuidado de inmediato para asegurarte de que no
Derribar el elaborado castillo de naipes. Pero, ¿cómo lo supiste exactamente?
que Tú no debería ¿derribarla? Es de suponer que nunca te has encontrado con un
situación como esta antes, por lo que no puede ser una experiencia pasada. Ni puede ser
«Antecedentes incorporados» de la evolución – nuestros antepasados cazadores-recolectores no
encuentra de forma rutinaria casas de naipes gigantes mientras busca comida. No, la razón por la que lo sabes
no debe ser derribado es que alguien claramente ha puesto mucho esfuerzo
para hacer este castillo de naipes, ciertamente no se construyó solo, y
no lo habrían hecho a menos que realmente les importara.
Preferencias implícitas en el estado del mundo desarrolla un algoritmo,
Recompense el aprendizaje simulando el pasado (RLSP), que hace este tipo de
razonamiento, permitiendo a un agente inferir preferencias humanas sin explícito
realimentación. Como ejemplo, considere el entorno de la habitación a continuación:

Cuando se despliega el robot, Alice le pide que navegue hasta la puerta violeta. Si nosotros
codificar esto como una función de recompensa que solo recompensa al robot mientras
está en la puerta púrpura, el robot tomaría el camino más corto hacia la púrpura
puerta, derribando y rompiendo el jarrón, ya que nadie dijo que no debería ser
que. El robot es perfectamente consciente de que su plan hace que rompa el jarrón,
pero, de forma predeterminada, no se da cuenta de que no debería romper el jarrón.
En cambio, RLSP puede inferir que el jarrón no debe romperse. A un alto nivel,
considera efectivamente todas las formas en que pudo haber sido el pasado, verifica qué
unos son consistentes con el estado observado, e infiere una función de recompensa basada
en el resultado. Si a Alice no le importaba si el jarrón estaba roto, ella
probablemente lo habría roto en algún momento en el pasado. Si ella buscado el jarrón
roto, definitivamente lo habría roto en algún momento del pasado. Entonces el único
La explicación consistente es que a Alice le importaba que el jarrón estuviera intacto. En
Por el contrario, observaríamos el mismo estado independientemente de las preferencias de Alice
sobre alfombras, por lo que RLSP no infiere nada sobre esas preferencias.
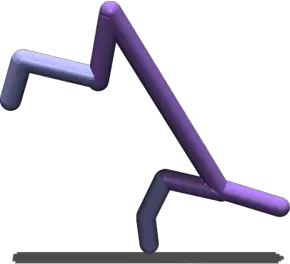
Desafortunadamente, este enfoque requiere razonar sobre todos los pasados posibles, que
es intratable incluso en entornos moderados. El trabajo anterior solo ha probado el
idea en entornos de gridworld muy simples. ¿Qué se necesitaría para escalar esto?
idea hasta entornos más grandes y continuos, donde no tenemos el conocimiento completo
de la dinámica ambiental? Intuitivamente, aún debería ser posible hacer
tales inferencias. Considere, por ejemplo, este guepardo que se balancea sobre su
pata delantera. Al igual que antes, podemos razonar que hay muy pocos comportamientos que
terminar con el guepardo en este estado en particular, por lo que el guepardo «prefiere»
estar en equilibrio sobre una pierna.
En nuestro último artículo presentado en ICLR 2021, presentamos Profundo
Recompense el aprendizaje simulando el pasado (Deep RLSP), una extensión del RLSP
algoritmo que se puede escalar a tareas como la tarea de equilibrio Cheetah.
La dificultad clave para ampliar RLSP a entornos más grandes está en cómo
razón sobre «lo que debe haber sucedido en el pasado». Para abordar esto,
muestra probables trayectorias pasadas, en lugar de enumerar todas las posibles
trayectorias. En el caso del guepardo en equilibrio, podemos inferir que el
Cheetah debe haber seguido una trayectoria similar a la que se muestra aquí:

Los algoritmos de RL basados en modelos a menudo simulan el futuro mediante la implementación de una política
$ pi (a_t mid s_t) $ para elegir acciones y un modelo de dinámica ambiental
$ mathcal {T} (s_ {t + 1} mid s_t, a_t) $ para predecir estados futuros. Del mismo modo, nosotros
simular el pasado implementando una política inversa $ pi ^ {- 1} (a_t mid s_ {t + 1}) $
que predice qué acción $ a_t $ tomó el usuario que resultó en el estado
$ s_ {t + 1} $, y un modelo de dinámica de entorno inverso $ mathcal {T} ^ {- 1} (s_t mid
s_ {t + 1}, a_t) $ que predice el estado $ s_t $ a partir del cual la acción elegida $ a_t $
habría llevado a $ s_ {t + 1} $. Al alternar entre predecir acciones pasadas,
y predecir estados pasados a partir de los cuales se tomaron esas acciones, podemos simular
trayectorias arbitrariamente lejanas en el pasado.
Antes de entrar en detalles sobre cómo entrenamos estos modelos, primero
comprender cómo vamos a utilizar los modelos entrenados para inferir preferencias de
un estado observado $ s_0 $.
El algoritmo RLSP utiliza el ascenso en gradiente para actualizar continuamente una recompensa lineal.
función para explicar un estado observado $ s_0 $. Para ampliar esta idea, hacemos dos
cambios clave en su enfoque: (1) aprendemos una representación de características de cada
establecer y modelar la función de recompensa como lineal en estas características, y (2)
aproximar el gradiente RLSP muestreando probables trayectorias pasadas en lugar de
enumerando todas las posibles trayectorias pasadas. Consulte nuestro artículo para obtener información detallada.
discusión de la derivación.
Esto da como resultado el estimador de gradiente Deep RLSP que tiene como objetivo maximizar el
probabilidad de un estado observado $ s_0 $ bajo una función de recompensa definida con un
vector de parámetro $ theta $:
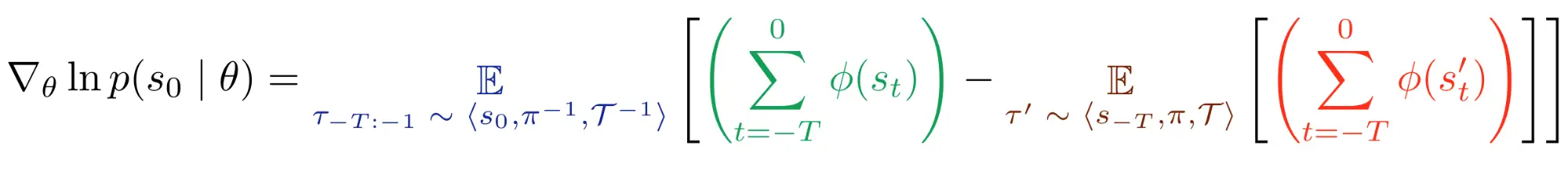
->
Intuitivamente, el gradiente se calcula en tres pasos: Primero, simular al revés
para determinar que debe haber sucedido antes de $ s_0 $. Segundo, nosotros simular hacia delante para determinar lo que hace la política actual (que está optimizada para $ theta $). En tercer lugar, calculamos
la diferencia de las trayectorias hacia atrás y hacia adelante. Este gradiente cambia
el parámetro de recompensa $ theta $ de modo que recompense las características observadas en el
trayectorias hacia atrás, y castiga las características observadas en el avance
trayectorias. Como resultado, cuando se vuelva a optimizar la recompensa, la nueva política
tienden a crear trayectorias que son menos parecidas a las trayectorias hacia adelante y
más como las trayectorias hacia atrás.
En otras palabras, el gradiente fomenta una función de recompensa tal que el
trayectorias hacia atrás (lo que debe haberse hecho en el pasado) y hacia adelante
trayectorias (lo que haría un agente usando la recompensa actual) son consistente
juntos. Una vez que las trayectorias son consistentes, el gradiente se vuelve
cero, y hemos aprendido una función de recompensa que probablemente cause la
estado observado $ s_0 $.
El núcleo de nuestro algoritmo es realizar un ascenso de gradiente utilizando este gradiente.
Sin embargo, necesitamos acceso a $ phi $, $ pi ^ {- 1} $, $ mathcal {T} ^ {- 1} $, $ pi $ y
$ mathcal {T} $ para calcular el gradiente. Aprendemos estos modelos de una
conjunto de datos $ mathcal {D} $ de interacciones ambientales. Tenga en cuenta que $ mathcal {D} $ necesita
no implica ninguna intervención humana: en nuestros experimentos, utilizamos lanzamientos de un
política para producir $ mathcal {D} $. Entonces podemos aprender los modelos necesarios como
sigue:
- La función característica $ phi $ se puede entrenar aplicando cualquier técnica de aprendizaje de representación auto-supervisada a $ mathcal {D} $. Usamos un Autoencoder Variacional (VAE) en nuestros experimentos.
- La política de reenvío $ pi $ se entrena utilizando Deep RL. Usamos Soft-Actor-Critic (SAC) en nuestros experimentos.
- No es necesario aprender la dinámica del entorno directo $ mathcal {T} $, ya que tenemos acceso a un simulador del entorno.
- La política inversa $ pi ^ {- 1} $ se entrena mediante el aprendizaje supervisado en $ (s, a, s ’) $ transiciones recopiladas al ejecutar $ pi $.
- La dinámica del entorno inverso $ mathcal {T} ^ {- 1} $ se entrena mediante el aprendizaje supervisado en $ (s, a, s ’) $ transiciones en $ mathcal {D} $.
Para probar nuestro algoritmo, lo aplicamos a tareas en el simulador de MuJoCo. Estas
Los entornos se utilizan comúnmente para comparar algoritmos de RL, y una tarea típica
sería hacer caminar a robots simulados.
Para evaluar Deep RLSP, usamos RL para entrenar políticas que caminan, corren o saltan
adelante y luego muestrear un solo estado de estas políticas. Deep RLSP debe
luego use solo ese estado para inferir que se supone que debe hacer la simulación
robot camina hacia adelante. Tenga en cuenta que esta tarea es un poco más fácil de lo que parece.
porque la información del estado en MuJoCo no solo contiene posiciones conjuntas, sino
también velocidades, por lo que un solo estado también proporciona alguna información sobre cómo
el robot se está moviendo.
Nuestros experimentos muestran que esto funciona razonablemente bien. Lo probamos principalmente
para un robot Cheetah y un robot Hopper, y en ambos casos aprendió
avanzar. Por supuesto, las políticas aprendidas no funcionan tan bien como
políticas que están directamente capacitadas en la verdadera función de recompensa.
Pero el objetivo de Deep RLSP es aprender en situaciones en las que no
tener una recompensa. Entonces, como un caso de prueba más interesante, usamos Deep RLSP para
imitar comportamientos de un solo estado que son difíciles de especificar explícitamente en un
función de recompensa. Generamos un conjunto de «habilidades» utilizando una habilidad sin supervisión
algoritmo de descubrimiento llamado DADS, incluida la habilidad de equilibrio que vimos
más temprano. Nuevamente, muestreamos un solo estado o un pequeño número de estados, y
comprobó si Deep RLSP aprendería a imitar la habilidad.
Dado que no tenemos acceso a una verdadera función de recompensa por «equilibrar», no
tienen una forma obvia de evaluar cuantitativamente el rendimiento de Deep RLSP. Nosotros
en su lugar, miró videos de las políticas aprendidas y las evaluó
cualitativamente. Por ejemplo, aquí está el guepardo de equilibrio original, junto con
el comportamiento aprendido por Deep RLSP usando un solo estado de entrada:


De izquierda a derecha: Política original, Estado muestreado, y Política de Deep RLSP.
El comportamiento no es perfecto: puede ver que la cabeza a veces toca el
suelo, y no parece particularmente bien en el equilibrio, pero tiene
aprendió claramente el esquema general de lo que se debe hacer.
Si bien nuestra evaluación inicial de Deep RLSP es prometedora, queda mucho por hacer
trabajar para aprender las preferencias del estado del mundo.
El requisito principal para que Deep RLSP funcione bien es aprender buenos modelos de
dinámica del entorno inverso y política inversa, y una buena función característica.
En los entornos de MuJoCo, confiamos en el aprendizaje de representación simple para el
función característica y aprendizaje supervisado para los modelos. Este enfoque es
Es poco probable que funcione para entornos mucho más grandes o robótica del mundo real.
aplicaciones. Sin embargo, somos optimistas de que los avances en la RL basada en modelos pueden
aplicarse directamente a este problema.
Una segunda pregunta abierta es cómo aprender las preferencias del estado del mundo.
en un entorno de agentes múltiples. Normalmente, el estado se optimizará mediante uno o más
humanos, y queremos una diferente robot para conocer estas preferencias. RLSP profundo
actualmente aprende la política y la recompensa del ser humano, pero en última instancia queremos utilizar
eso para informar el comportamiento del robot. En nuestros experimentos, el «humano» y
«Robot» eran los mismos, por lo que podríamos utilizar directamente la política inferida como nuestra
política de robots, pero obviamente este no será el caso en una
solicitud.
Finalmente, mientras nos enfocamos en el aprendizaje de imitación en este proyecto, Deep RLSP es
también muy prometedor para el aprendizaje restricciones de seguridad, como «no rompa el
jarrón». Esperamos que la idea de aprender las preferencias del estado del
world también será útil para aplicar RL en entornos críticos para la seguridad.
Esta publicación se basa en el documento «Aprender qué hacer mediante la simulación de
Pasado ”, presentado en ICLR 2021. Puede ver nuestras políticas capacitadas sobre
nuestra página web. También proporcionamos código para reproducir nuestros experimentos.
aquí.