
Última actualización el 27 de abril de 2021
Aprendizaje conjunto es un metaenfoque general para el aprendizaje automático que busca un mejor rendimiento predictivo al combinar las predicciones de múltiples modelos.
Aunque hay un número aparentemente ilimitado de conjuntos que puede desarrollar para su problema de modelado predictivo, hay tres métodos que dominan el campo del aprendizaje por conjuntos. Tanto es así, que en lugar de algoritmos per se, cada uno es un campo de estudio que ha generado muchos métodos más especializados.
Las tres clases principales de métodos de aprendizaje por conjuntos son harpillera, apilado, y impulsando, y es importante tener una comprensión detallada de cada método y tenerlos en cuenta en su proyecto de modelado predictivo.
Pero, antes de eso, necesita una introducción suave a estos enfoques y las ideas clave detrás de cada método antes de superponer las matemáticas y el código.
En este tutorial, descubrirá las tres técnicas estándar de aprendizaje por conjuntos para el aprendizaje automático.
Después de completar este tutorial, sabrá:
- El ensacado implica ajustar muchos árboles de decisión en diferentes muestras del mismo conjunto de datos y promediar las predicciones.
- El apilamiento implica ajustar muchos tipos de modelos diferentes en los mismos datos y usar otro modelo para aprender cómo combinar mejor las predicciones.
- El impulso implica agregar miembros del conjunto secuencialmente que corrigen las predicciones hechas por modelos anteriores y generan un promedio ponderado de las predicciones.
Pon en marcha tu proyecto con mi nuevo libro Ensemble Learning Algorithms With Python, que incluye tutoriales paso a paso y el Código fuente de Python archivos para todos los ejemplos.
Empecemos.

Una suave introducción a los algoritmos de aprendizaje por conjuntos
Foto de Rajiv Bhuttan, algunos derechos reservados.
Descripción general del tutorial
Este tutorial se divide en cuatro partes; ellos son:
- Estrategias de aprendizaje en conjunto estándar
- Aprendizaje conjunto de ensacado
- Aprendizaje conjunto de apilamiento
- Impulsar el aprendizaje conjunto
Estrategias de aprendizaje en conjunto estándar
El aprendizaje conjunto se refiere a algoritmos que combinan las predicciones de dos o más modelos.
Aunque hay casi un número ilimitado de formas en que esto se puede lograr, hay quizás tres clases de técnicas de aprendizaje por conjuntos que se discuten y se usan con mayor frecuencia en la práctica. Su popularidad se debe en gran parte a su facilidad de implementación y éxito en una amplia gama de problemas de modelado predictivo.
En los últimos años se ha desarrollado una rica colección de clasificadores basados en conjuntos. Sin embargo, muchos de estos son algunas variaciones de unos pocos algoritmos bien establecidos, cuyas capacidades también se han probado exhaustivamente y se han informado ampliamente.
– Página 11, Ensemble Machine Learning, 2012.
Dado su amplio uso, podemos referirnos a ellos como «estándar”Estrategias de aprendizaje en conjunto; ellos son:
- Harpillera.
- Apilado.
- Impulso.
Existe un algoritmo que describe cada enfoque, aunque lo que es más importante, el éxito de cada enfoque ha generado una gran cantidad de extensiones y técnicas relacionadas. Como tal, es más útil describir cada uno como una clase de técnicas o enfoques estándar para el aprendizaje en conjunto.
En lugar de profundizar en los detalles de cada método, es útil recorrer, resumir y contrastar cada enfoque. También es importante recordar que, aunque la discusión y el uso de estos métodos son generalizados, estos tres métodos por sí solos no definen el alcance del aprendizaje en conjunto.
A continuación, echemos un vistazo más de cerca al embolsado.
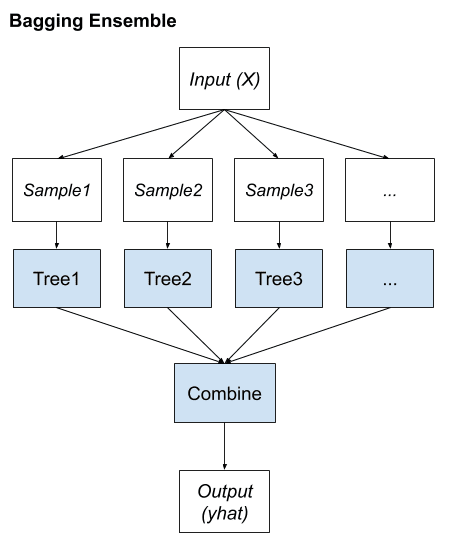
Aprendizaje conjunto de ensacado
La agregación Bootstrap, o empaquetamiento para abreviar, es un método de aprendizaje de conjunto que busca un grupo diverso de miembros del conjunto variando los datos de entrenamiento.
El nombre Bagging proviene de la abreviatura de Bootstrap AGGregatING. Como su nombre lo indica, los dos ingredientes clave de Bagging son bootstrap y agregación.
– Página 48, Métodos de conjunto, 2012.
Por lo general, esto implica el uso de un solo algoritmo de aprendizaje automático, casi siempre un árbol de decisiones sin podar, y el entrenamiento de cada modelo en una muestra diferente del mismo conjunto de datos de entrenamiento. Las predicciones hechas por los miembros del conjunto luego se combinan usando estadísticas simples, como votaciones o promedios.
La diversidad en el conjunto está asegurada por las variaciones dentro de las réplicas bootstrapped en las que se entrena cada clasificador, así como por el uso de un clasificador relativamente débil cuyos límites de decisión varían de manera mensurable con respecto a perturbaciones relativamente pequeñas en los datos de entrenamiento.
– Página 11, Ensemble Machine Learning, 2012.
La clave del método es la forma en que se prepara cada muestra del conjunto de datos para entrenar a los miembros del conjunto. Cada modelo obtiene su propia muestra única del conjunto de datos.
Los ejemplos (filas) se extraen del conjunto de datos al azar, aunque con reemplazo.
Bagging adopta la distribución bootstrap para generar diferentes alumnos base. En otras palabras, aplica el muestreo bootstrap para obtener los subconjuntos de datos para capacitar a los alumnos base.
– Página 48, Métodos de conjunto, 2012.
Reemplazo significa que si se selecciona una fila, se devuelve al conjunto de datos de entrenamiento para una posible nueva selección en el mismo conjunto de datos de entrenamiento. Esto significa que una fila de datos se puede seleccionar cero, una o varias veces para un conjunto de datos de entrenamiento dado.
Esto se llama muestra de arranque. Es una técnica que se utiliza a menudo en estadísticas con pequeños conjuntos de datos para estimar el valor estadístico de una muestra de datos. Al preparar múltiples muestras de arranque diferentes y estimar una cantidad estadística y calcular la media de las estimaciones, se puede lograr una mejor estimación general de la cantidad deseada que simplemente estimar directamente a partir del conjunto de datos.
De la misma manera, se pueden preparar múltiples conjuntos de datos de entrenamiento diferentes, usarlos para estimar un modelo predictivo y hacer predicciones. El promedio de las predicciones entre los modelos generalmente da como resultado mejores predicciones que un solo modelo que se ajusta directamente al conjunto de datos de entrenamiento.
Podemos resumir los elementos clave del ensacado de la siguiente manera:
- Muestras de bootstrap del conjunto de datos de entrenamiento.
- Los árboles de decisión sin podar encajan en cada muestra.
- Votación simple o promediado de predicciones.
En resumen, la contribución del ensacado radica en la variación de los datos de entrenamiento utilizados para adaptarse a cada miembro del conjunto, lo que, a su vez, da como resultado modelos hábiles pero diferentes.
Conjunto de ensacado
Es un enfoque general y fácil de ampliar. Por ejemplo, se pueden introducir más cambios en el conjunto de datos de entrenamiento, se puede reemplazar el ajuste del algoritmo en los datos de entrenamiento y se puede modificar el mecanismo utilizado para combinar predicciones.
Muchos algoritmos de conjuntos populares se basan en este enfoque, que incluyen:
- Árboles de decisión empaquetados (ensacado canónico)
- Bosque aleatorio
- Árboles adicionales
A continuación, echemos un vistazo más de cerca al apilamiento.
¿Quiere comenzar con el aprendizaje por conjuntos?
Realice ahora mi curso intensivo gratuito de 7 días por correo electrónico (con código de muestra).
Haga clic para registrarse y obtener también una versión gratuita en formato PDF del curso.
Descarga tu minicurso GRATIS
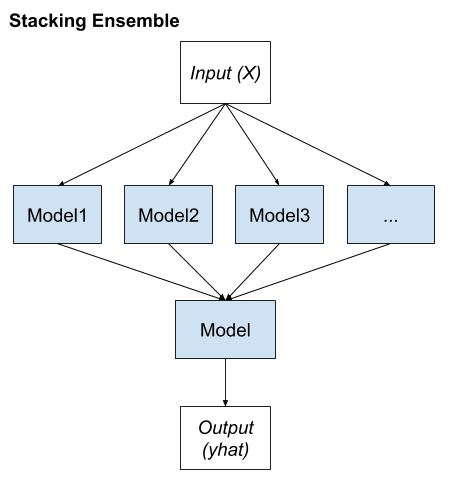
Aprendizaje conjunto de apilamiento
La generalización apilada, o apilamiento para abreviar, es un método de conjunto que busca un grupo diverso de miembros variando los tipos de modelos que se ajustan a los datos de entrenamiento y usando un modelo para combinar predicciones.
El apilamiento es un procedimiento general en el que se capacita a un alumno para combinar a los alumnos individuales. Aquí, los alumnos individuales se denominan alumnos de primer nivel, mientras que el combinador se denomina alumno de segundo nivel o metaaprendizaje.
– Página 83, Métodos de conjunto, 2012.
El apilamiento tiene su propia nomenclatura en la que los miembros del conjunto se denominan modelos de nivel 0 y el modelo que se utiliza para combinar las predicciones se denomina modelo de nivel 1.
La jerarquía de modelos de dos niveles es el enfoque más común, aunque se pueden utilizar más capas de modelos. Por ejemplo, en lugar de un modelo de nivel 1 único, podríamos tener 3 o 5 modelos de nivel 1 y un modelo de nivel 2 único que combina las predicciones de los modelos de nivel 1 para hacer una predicción.
El apilamiento es probablemente la técnica de metaaprendizaje más popular. Mediante el uso de un metaaprendiz, este método intenta inducir qué clasificadores son confiables y cuáles no.
– Página 82, Clasificación de patrones utilizando métodos de conjunto, 2010.
Se puede usar cualquier modelo de aprendizaje automático para agregar las predicciones, aunque es común usar un modelo lineal, como la regresión lineal para la regresión y la regresión logística para la clasificación binaria. Esto fomenta la complejidad del modelo para que resida en los modelos de miembros del conjunto de nivel inferior y en los modelos simples para aprender a aprovechar la variedad de predicciones realizadas.
Usando combinadores entrenables, es posible determinar qué clasificadores tienen probabilidades de tener éxito en qué parte del espacio de características y combinarlos en consecuencia.
– Página 15, Ensemble Machine Learning, 2012.
Podemos resumir los elementos clave del apilamiento de la siguiente manera:
- Conjunto de datos de entrenamiento sin cambios.
- Diferentes algoritmos de aprendizaje automático para cada miembro del conjunto.
- Modelo de aprendizaje automático para aprender a combinar mejor las predicciones.
La diversidad proviene de los diferentes modelos de aprendizaje automático que se utilizan como miembros del conjunto.
Como tal, es deseable utilizar un conjunto de modelos que se aprenden o construyen de formas muy diferentes, asegurándose de que hagan diferentes suposiciones y, a su vez, tengan menos errores de predicción correlacionados.
Conjunto de apilamiento
Muchos algoritmos de conjuntos populares se basan en este enfoque, que incluyen:
- Modelos apilados (apilamiento canónico)
- Mezcla
- Super Conjunto
A continuación, echemos un vistazo más de cerca al impulso.
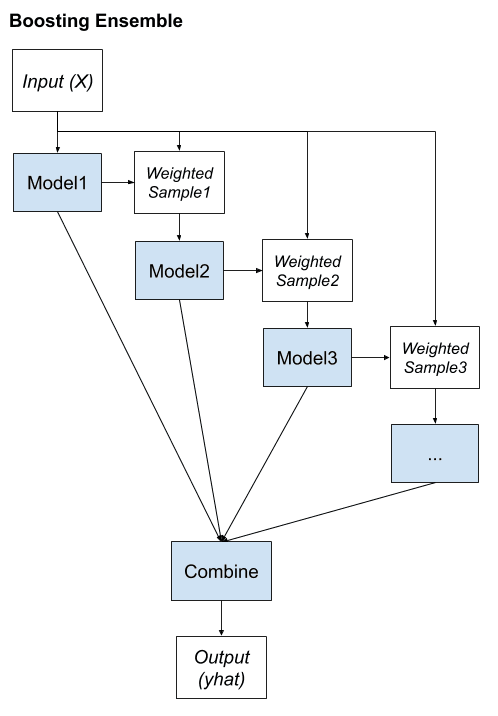
Impulsar el aprendizaje conjunto
El impulso es un método de conjunto que busca cambiar los datos de entrenamiento para centrar la atención en ejemplos en los que los modelos de ajuste anteriores en el conjunto de datos de entrenamiento se han equivocado.
Al impulsar, […] el conjunto de datos de entrenamiento para cada clasificador subsiguiente se enfoca cada vez más en instancias mal clasificadas por clasificadores generados previamente.
– Página 13, Ensemble Machine Learning, 2012.
La propiedad clave de impulsar conjuntos es la idea de corregir errores de predicción. Los modelos se ajustan y se agregan al conjunto secuencialmente de modo que el segundo modelo intenta corregir las predicciones del primer modelo, el tercero corrige el segundo modelo, y así sucesivamente.
Por lo general, esto implica el uso de árboles de decisiones muy simples que solo toman una o pocas decisiones, a las que se hace referencia en el refuerzo como estudiantes débiles. Las predicciones de los estudiantes débiles se combinan mediante votaciones simples o promedios, aunque las contribuciones se pesan de manera proporcional a su desempeño o capacidad. El objetivo es desarrollar un llamado «aprendiz fuerte«De muchos construidos expresamente»aprendices débiles. «
… Un enfoque iterativo para generar un clasificador fuerte, uno que sea capaz de lograr un error de entrenamiento arbitrariamente bajo, a partir de un conjunto de clasificadores débiles, cada uno de los cuales apenas puede funcionar mejor que la adivinación aleatoria.
– Página 13, Ensemble Machine Learning, 2012.
Por lo general, el conjunto de datos de entrenamiento no se modifica y, en cambio, el algoritmo de aprendizaje se modifica para prestar más o menos atención a ejemplos específicos (filas de datos) en función de si los miembros del conjunto añadidos previamente los han predicho correctamente o incorrectamente. Por ejemplo, las filas de datos se pueden pesar para indicar la cantidad de enfoque que debe dar un algoritmo de aprendizaje mientras aprende el modelo.
Podemos resumir los elementos clave del impulso de la siguiente manera:
- Sesgo de datos de entrenamiento hacia aquellos ejemplos que son difíciles de predecir.
- Agregue iterativamente miembros del conjunto para corregir las predicciones de modelos anteriores.
- Combine predicciones utilizando un promedio ponderado de modelos.
La idea de combinar muchos estudiantes débiles en estudiantes fuertes se propuso por primera vez teóricamente y se propusieron muchos algoritmos con poco éxito. No fue hasta que se desarrolló el algoritmo Adaptive Boosting (AdaBoost) que se demostró que el refuerzo era un método de conjunto eficaz.
El término impulso se refiere a una familia de algoritmos que pueden convertir a los estudiantes débiles en estudiantes fuertes.
– Página 23, Métodos de conjunto, 2012.
Desde AdaBoost, se han desarrollado muchos métodos de refuerzo y algunos, como el aumento de gradiente estocástico, pueden estar entre las técnicas más efectivas para la clasificación y regresión de datos tabulares (estructurados).
Conjunto de impulso
Para resumir, muchos algoritmos de conjuntos populares se basan en este enfoque, que incluyen:
- AdaBoost (refuerzo canónico)
- Máquinas de aumento de gradiente
- Impulso de gradiente estocástico (XGBoost y similar)
Esto completa nuestro recorrido por las técnicas estándar de aprendizaje en conjunto.
Otras lecturas
Esta sección proporciona más recursos sobre el tema si desea profundizar.
Libros
Artículos
Resumen
En este tutorial, descubrió las tres técnicas estándar de aprendizaje por conjuntos para el aprendizaje automático.
Específicamente, aprendiste:
- El ensacado implica ajustar muchos árboles de decisión en diferentes muestras del mismo conjunto de datos y promediar las predicciones.
- El apilamiento implica ajustar muchos tipos de modelos diferentes en los mismos datos y usar otro modelo para aprender cómo combinar mejor las predicciones.
- El impulso implica agregar miembros del conjunto secuencialmente que corrigen las predicciones hechas por modelos anteriores y generan un promedio ponderado de las predicciones.
¿Tiene usted alguna pregunta?
Haga sus preguntas en los comentarios a continuación y haré todo lo posible para responder.
¡Controle el aprendizaje conjunto moderno!

Mejore sus predicciones en minutos
… con solo unas pocas líneas de código Python
Descubra cómo en mi nuevo libro electrónico:
Algoritmos de aprendizaje por conjuntos con Python
Proporciona tutoriales de autoaprendizaje con código de trabajo completo en:
Apilado, Votación, Impulsando, Harpillera, Mezcla, Súper aprendiz,
y mucho más…
Lleve las técnicas modernas de aprendizaje por conjuntos a
Sus proyectos de aprendizaje automático
Mira lo que hay dentro