
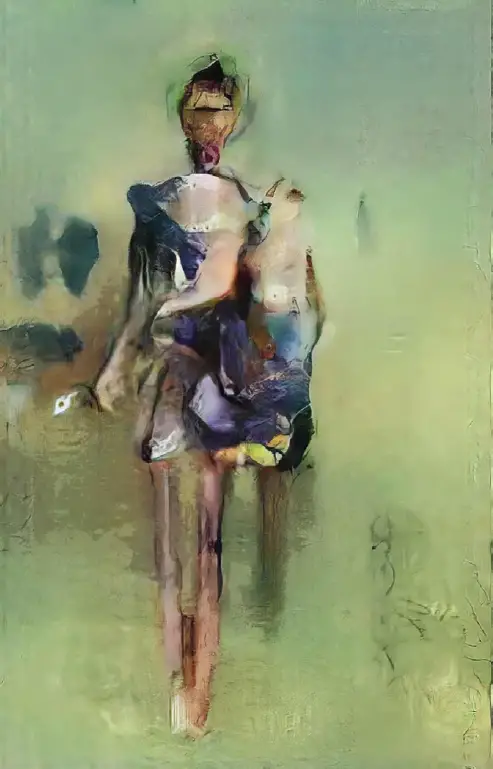
La mayoría de las ideas fundamentales en las redes neuronales convolucionales (rebautizadas en la década de 2010 como aprendizaje profundo), tienen en realidad varias décadas de antigüedad. Sólo tomó un tiempo para que el hardware, los datos y la comunidad de investigación se pusieran al día. Pero si uno se pregunta, ¿cuál es la más importante nuevo idea que ha surgido en la última década, sin duda, es la de las Redes Generativas Adversas (GAN). Como la mayoría de los buenos trabajos, ciertamente tenía algunos precursores, sin embargo, cuando salió en 2014, hubo una sensación palpable de que algo nuevo y emocionante está en marcha. Después de todo, el artículo era fácil de gustar ya que tenía todos los ingredientes correctos: una idea inteligente, buenas matemáticas, una conexión intrigante con la evolución. Y si el trabajo original no deslumbró por la calidad visual de sus resultados, la larga serie de trabajos de seguimiento han demostrado el impresionante poder del método, uno que puede tener un impacto considerable más allá de la informática.
La mayoría de los éxitos recientes en el aprendizaje de la máquina ha venido de la llamada modelos discriminatorios…estos modelos tratan de buscar los bits y piezas de información relevantes para decidir de qué se trata. Por ejemplo, la presencia de rayas podría sugerir que una imagen contiene una cebra. Una alternativa son modelos generativosque tienen como objetivo aproximarse al proceso que genera los datos. Mientras que un modelo discriminatorio sólo te diría que algo es una cebra, un modelo generativo podría en realidad pintarte una.
Sin embargo, los modelos generativos no han tenido mucho éxito para las imágenes del mundo real, en gran parte porque es difícil evaluar automáticamente el generador. Si tuviéramos una forma de medir cuán buena es la salida de un modelo, conocida como una función objetiva o una «función de pérdida», podríamos optimizar nuestro modelo generativo de acuerdo con esta métrica. ¿Pero cómo se cuantifica si un modelo hace un buen trabajo en la generación de nuevas imágenes realistas que nadie ha visto antes? La idea clave del siguiente artículo de GAN es aprender la función de pérdida al mismo tiempo que se aprende el modelo generativo. Esta idea de aprender simultáneamente un generador y un discriminador de una manera adversaria ha resultado ser extremadamente poderosa. El modelo conduce a vívidas analogías antropomórficas: algunos investigadores explican las GAN como una competencia entre dos actores, como un artista y un crítico, un estudiante y un profesor, o un falsificador y un detective.
Figura. Mario Klingemann, No matar al mensajero (2017); https://bit.ly/3iYhvxU
Tras su publicación inicial, este trabajo condujo a avances vertiginosamente rápidos en la calidad y generalidad de los modelos de GAN; en pocos años, los investigadores demostraron la capacidad de generar conjuntos aparentemente infinitos de nuevas imágenes que eran virtualmente indistinguibles de las reales. Además, las pérdidas adversas aprendidas resultaron muy útiles en muchos otros contextos, por ejemplo, proporcionando «ruedas de entrenamiento» para la edición de imágenes que mantienen las imágenes realistas durante el proceso de edición.
Los modelos basados en la GAN podrían tener pronto un considerable impacto cultural y político en la sociedad, tanto positivo como negativo. Muchos artistas notables, entre ellos Sofía Crespo, Scott Eaton, Mario Klingemann, Trevor Paglen, Jason Salavon y Helena Sarin, han utilizado las GAN, y el arte de las GAN ha aparecido en varias galerías, festivales y casas de subastas importantes.1,2 De hecho, parte del poder de las GAN como herramientas artísticas se puede experimentar usando la página web Artbreeder.com de Joel Simon. Muchos estudios cinematográficos y empresas de nueva creación están explorando actualmente tecnologías que utilizan las pérdidas de las GAN para crear personajes virtuales, avatares y decorados, para proporcionar nuevas herramientas artísticas para la narración de historias y la comunicación. Las GAN podrían ayudarnos a tomar mejores fotografías y a capturar recuerdos del mundo en 3D, y tal vez algún día nuestras videoconferencias mejorarán gracias a las GAN que nos hacen ser tan realistas o como avatares extravagantes en espacios virtuales compartidos. Al mismo tiempo, las técnicas basadas en GAN plantean grandes preocupaciones en torno a la desinformación y varios usos maliciosos de DeepFakes, así como varios sesgos de datos en los algoritmos de síntesis de imágenes y cómo se utilizan. Además de ser una importante contribución fundamental a la informática, las GAN están a la vanguardia de algunas de nuestras esperanzas y temores sobre cómo los algoritmos de imágenes pueden transformar la sociedad.
Volver al principio
Referencias
1. Bailey, J. Las herramientas del arte generativo, desde el Flash hasta las redes neuronales. El arte en América 8 (enero de 2020); https://bit.ly/2EQqna9
2. Hertzmann, A. Indeterminación visual en el arte de la GAN. Leonardo 534 (Agosto 2020), 424-428; https://bit.ly/3lJ2KkA
Volver al principio
Volver al principio
Los derechos de autor pertenecen a los autores/propietarios.
Solicitar permiso para (re)publicar al propietario/autor
La Biblioteca Digital es publicada por la Asociación de Maquinaria de Computación. Derechos de autor © 2020 ACM, Inc.
No se han encontrado entradas