

Última actualización el 20 de abril de 2022
Publicación patrocinada
Por Luis Bermúdez
Este blog recorre un proceso para experimentar con hiperparámetros, algoritmos de entrenamiento y otros parámetros de Graph Neural Networks. En esta publicación, compartimos las dos primeras fases de nuestra cadena de experimentos. Los conjuntos de datos gráficos que usamos para hacer inferencias provienen de Open Graph Benchmark (OGB). Si lo encuentra útil, proporcionamos una breve descripción general de GNN y una breve descripción general de OGB.
Objetivos de experimentación y tipos de modelos
Sintonizamos dos variantes populares de GNN para:
- Mejorar rendimiento en las tareas de predicción de la tabla de clasificación de OGB.
- Minimizar costo de entrenamiento (tiempo y número de épocas) para futuras referencias.
- Analizar Comportamiento de entrenamiento de minilotes frente a gráficos completos en iteraciones de HPO.
- Demostrar un proceso genérico para la experimentación iterativa sobre hiperparámetros.
Hicimos nuestras propias implementaciones de las entradas de la tabla de clasificación OGB para dos marcos GNN populares: GraphSAGE y una red convolucional de gráficos relacionales (RGCN). Luego, diseñamos y ejecutamos un enfoque de experimentación iterativo para el ajuste de hiperparámetros en el que buscamos un modelo de calidad que tome un tiempo mínimo para entrenar. Definimos la calidad mediante la ejecución de un bucle de ajuste de rendimiento sin restricciones y usamos los resultados para establecer umbrales en un bucle de ajuste restringido que optimiza la eficiencia del entrenamiento.
Para GraphSAGE y RGCN, implementamos un enfoque de mini lotes y un gráfico completo. El muestreo es un aspecto importante del entrenamiento de GNN, y el proceso de mini lotes es diferente al entrenamiento de otros tipos de redes neuronales. En particular, los gráficos de mini lotes pueden conducir a un crecimiento exponencial en la cantidad de datos que la red necesita procesar por lote; esto se denomina «explosión de vecindario». A continuación, en la sección de diseño de experimentos, describimos nuestro enfoque de ajuste teniendo en cuenta este aspecto de mini lotes en gráficos.
Para obtener más información sobre la importancia de las estrategias de muestreo para GNN, consulte algunos de estos recursos:
Ahora buscamos encontrar las mejores versiones de nuestros modelos de acuerdo con los objetivos de experimentación descritos anteriormente.
Nuestro proceso de experimentación HPO (optimización de hiperparámetros) tiene tres fases para cada tipo de modelo, tanto para el muestreo de mini lotes como para el gráfico completo. Las tres fases incluyen:
- Actuación: ¿Cuál es el mejor rendimiento?
- Eficiencia: ¿Qué tan rápido podemos encontrar un modelo de calidad?
- Confianza: ¿Cómo seleccionamos los modelos de mayor calidad?
Él primera fase aprovecha un único experimento SigOpt de métrica que optimiza la pérdida de validación para implementaciones de mini lotes y gráficos completos. Esta fase encuentra el mejor rendimiento ajustando GraphSAGE y RCGN.
Él segunda fase define dos métricas para medir la rapidez con la que completamos el entrenamiento del modelo: (a) tiempo de reloj de pared para el entrenamiento de GNN y (b) épocas totales para el entrenamiento de GNN. También utilizamos nuestro conocimiento de la primera fase para informar el diseño de un experimento de optimización con restricciones. Minimizamos las métricas sujetas a que la pérdida de validación sea mayor que un objetivo de calidad.
Él tercera fase elige modelos de calidad con una distancia razonable entre ellos en el espacio de hiperparámetros. Ejecutamos el mismo entrenamiento con 10 semillas aleatorias diferentes según las pautas de OGB. También usamos GNNExplainer para analizar los patrones en los modelos. (Hablaremos más sobre la tercera fase en una futura publicación de blog)
Cómo ejecutar el código
El código vive en este repositorio. Para ejecutar el código, debe seguir estos pasos:
- Regístrese gratis o inicie sesión para obtener su API Token
- Clonar el repositorio
- Crear entorno virtual y ejecutar
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 dieciséis 17 18 19 20 |
# Coloque el token API como una variable de entorno > exportar SIGOPT_API_TOKEN=&es;> # Instalar las bibliotecas requeridas > pepita Instalar en pc –r requisitos.TXT # Ir a experimentos/ y ejecutar > pitón crear_experimento.py —modelo —conjunto de datos —capacitación–método —mejoramiento–objetivo # Ir a experimentos/ y ejecutar > pitón ejecutar_experimento.py —experimento–identificación —modelo —conjunto de datos —capacitación–método —mejoramiento–objetivo |
Para la primera fase de experimentación, el experimento de ajuste de hiperparámetros se realizó en un clúster Xeon utilizando Jenkins para programar ejecuciones de entrenamiento del modelo en los nodos del clúster. Se utilizaron contenedores Docker para el entorno de ejecución. Hubo cuatro flujos de Experimentos en total, uno para cada fila en la siguiente tabla, todos con el objetivo de minimizar la pérdida de validación.
| Tipo GNN | conjunto de datos | Muestreo | Objetivo de optimización | Mejor pérdida de validación | Mejor precisión de validación |
| GráficoSAGE | productos ogbn | mini lote | Pérdida de validación | 0.269 | 0.929 |
| GráficoSAGE | productos ogbn | gráfico completo | Pérdida de validación | 0.306 | 0,92 |
| RGCN | ogbn-mag | mini lote | Pérdida de validación | 1.781 | 0.506 |
| RGCN | ogbn-mag | gráfico completo | Pérdida de validación | 1.928 | 0.472 |
Tabla 1 – Resultados de la Fase 1 del Experimento
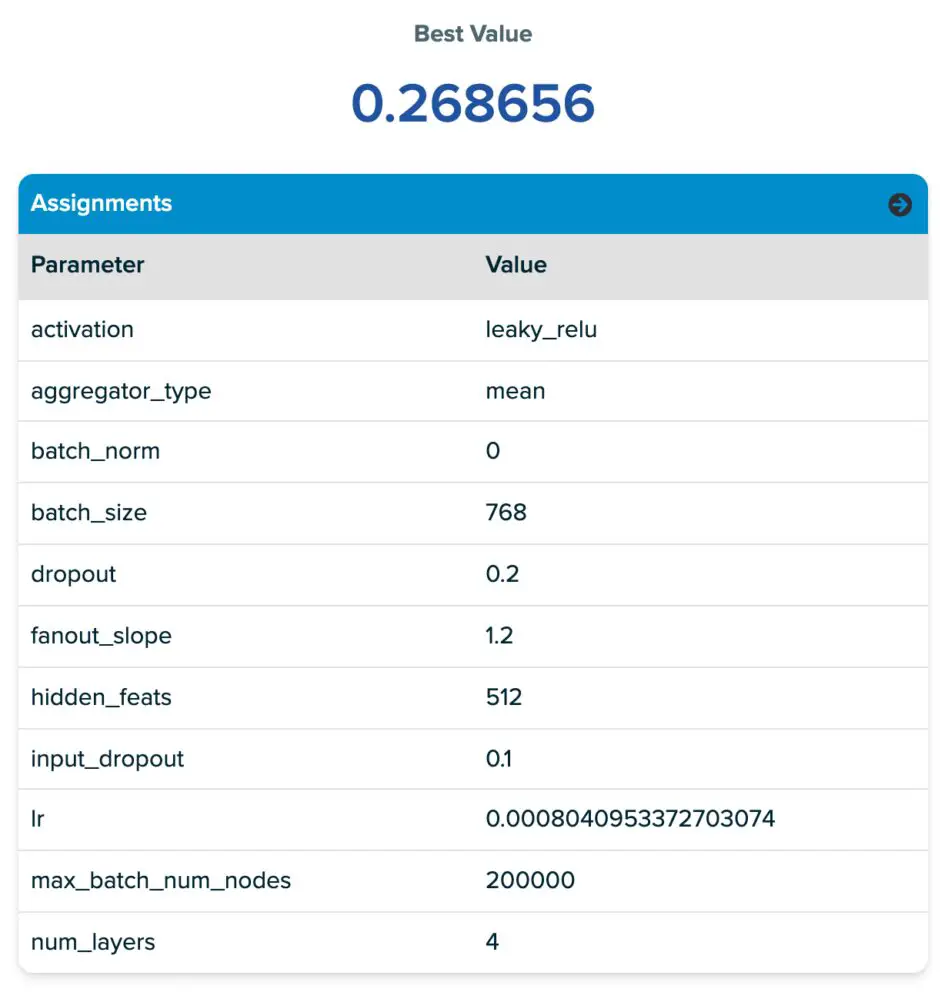
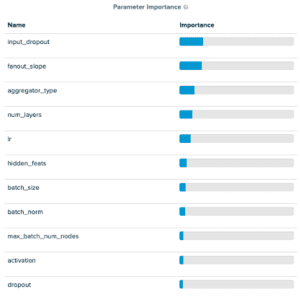
Los valores de los parámetros para la primera fila de la tabla se proporcionan en la captura de pantalla de la plataforma SigOpt (justo debajo de la tabla). En la captura de pantalla de parámetros, notará que nuestro espacio de ajuste contiene muchos hiperparámetros comunes de redes neuronales. También notará algunos nuevos llamados pendiente de abanico y max_batch_num_nodes. Ambos están relacionados con un parámetro de Deep Graph Library MultiLayerNeighborSampler llamado fanouts que determina cuántos nodos vecinos se consideran durante el paso de mensajes. Introducimos estos nuevos parámetros en el espacio de diseño para animar a SigOpt a elegir fanouts «buenos» de un espacio de sintonización razonablemente grande sin ajustar directamente la cantidad de fanouts, lo que descubrimos que a menudo conducía a tiempos de entrenamiento prohibitivamente largos debido a la explosión del vecindario al enviar mensajes. pasando a través de múltiples capas de muestreo. El objetivo de este enfoque es explorar el espacio de muestreo de mini lotes mientras se limita el problema de explosión de vecindad. Los dos parámetros que introducimos son:
- Pendiente de abanico: Controla la tasa de abanico por capa de salto/GNN. Aumentarlo actúa como un multiplicador del fanout, el número de nodos muestreados en cada salto adicional en el gráfico.
- Número máximo de nodos de lote: Establece un umbral para el número máximo de nodos por lote, si el número total de muestras producidas con fanout pendiente.
A continuación, vemos las configuraciones del experimento RGCN para la fase 1. Hay una desviación similar entre las implementaciones de mini lotes y gráficos completos para nuestros experimentos GraphSAGE.
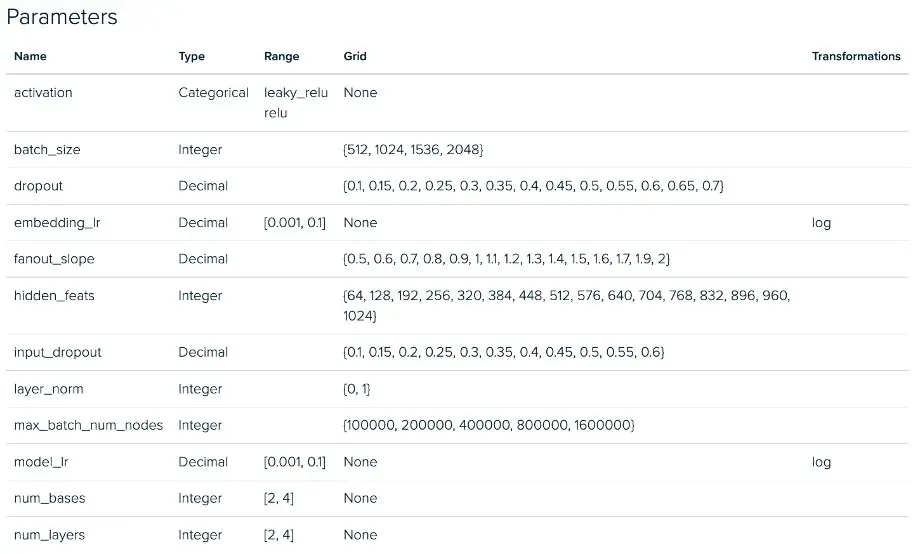
Experimento de sintonización de mini lotes RGCN: espacio de parámetros
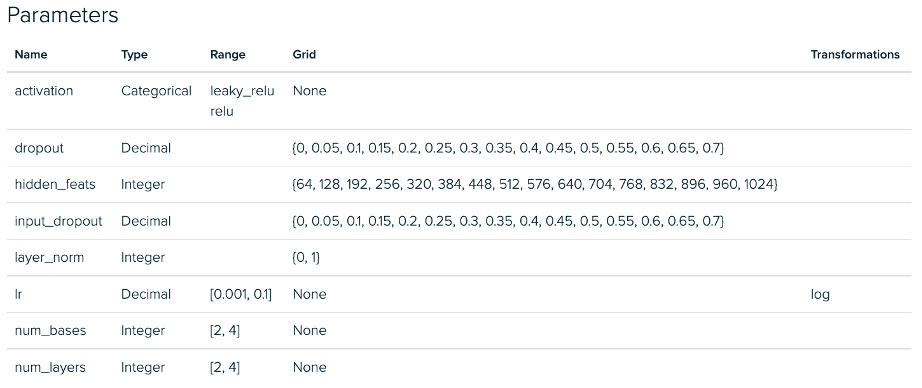
Experimento de ajuste de gráfico completo RGCN: espacio de parámetros
Al ajustar GraphSAGE con un enfoque de mini lotes, descubrimos que, de los parámetros que introdujimos, fanout_slope era importante para predecir las puntuaciones de precisión y max_batch_num_nodes era relativamente poco importante. En particular, encontramos que el max_batch_num_nodes logrado tendía a conducir a puntos que funcionaban mejor cuando era bajo.
Los resultados para el mini lote RGCN mostraron algo similar, aunque los parámetros max_batch_num_nodes fueron un poco más impactantes. Ambos resultados de mini lotes mostraron un mejor rendimiento que sus contrapartes de gráfico completo. Los cuatro flujos de sintonización de hiperparámetros tenían las ejecuciones que contenían: detención temprana cuando el rendimiento no mejoraba después de diez épocas.
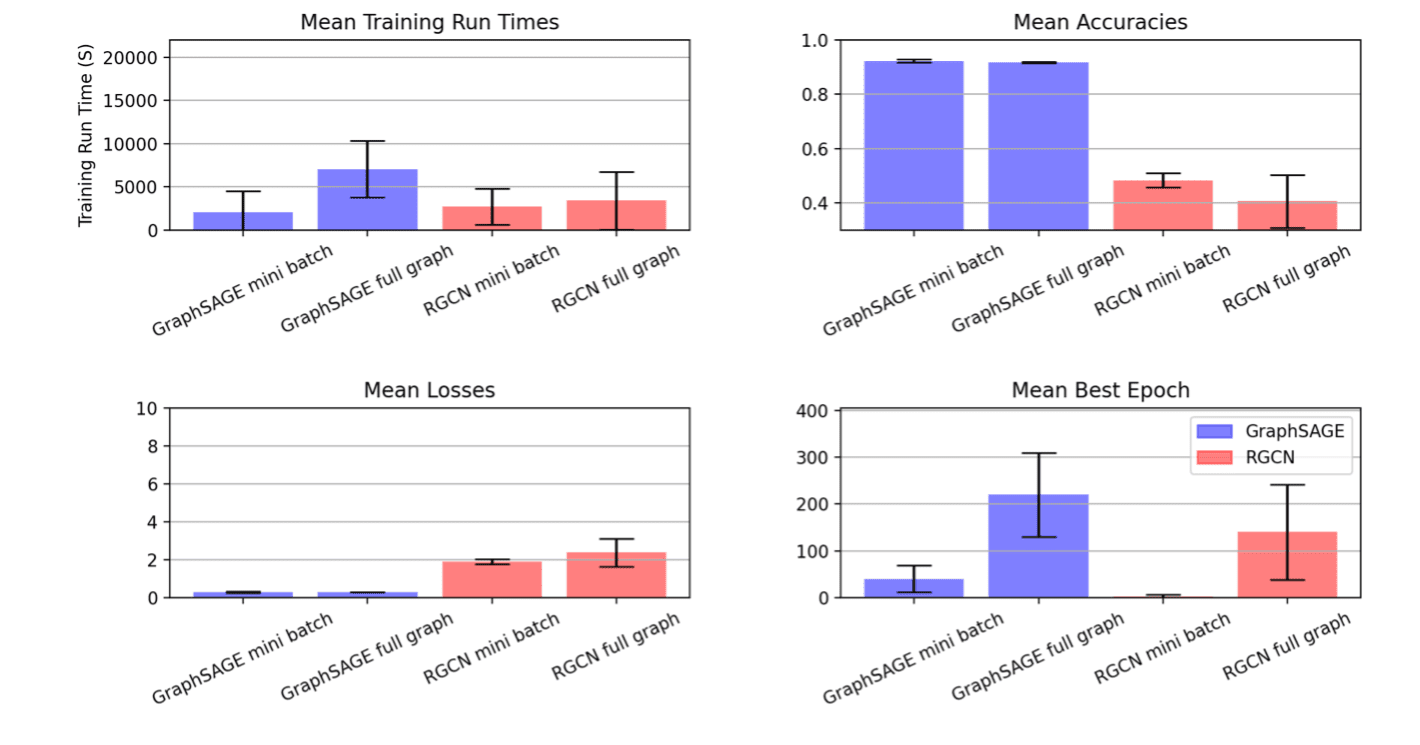
Este procedimiento arrojó las siguientes distribuciones:
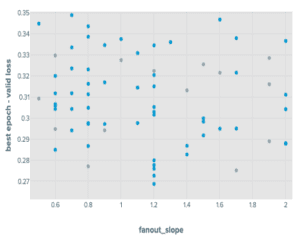
Resultados del experimento de sintonización de GraphSAGE en productos OGBN
Luego, usamos los resultados de estos experimentos para informar el diseño del experimento para una ronda posterior enfocada en alcanzar un objetivo de calidad lo más rápido posible. Para un objetivo de calidad, establecemos una restricción de (1,05 * mejor pérdida de validación) y (0,95 * puntaje de precisión) para la pérdida de validación y la precisión de la validación, respectivamente.
Durante la segunda fase de experimentación, buscamos modelos que cumplan con nuestro objetivo de calidad y que entrenen lo más rápido posible. Entrenamos estos modelos en procesadores Xeon en instancias AWS m6.8xlarge. Nuestra tarea de optimización es:
- Minimizar el tiempo total de ejecución
- Sujeto a pérdida de validación menor o igual a 1,05 veces el valor mejor visto
- Sujeto a una precisión de validación mayor o igual a 0,95 veces el valor mejor visto
Enmarcar nuestros objetivos de optimización de esta manera produjo estos resultados métricos
| tipo GNN | conjunto de datos | Muestreo | Mejoramiento Objetivo |
Mejor época | Precisión válida |
| GráficoSAGE | productos ogbn | mini lote | Tiempo de entrenamiento, épocas | 933.529 | 0.929 |
| GráficoSAGE | productos ogbn | gráfico completo | Tiempo de entrenamiento, épocas | 3791.15 | 0.923 |
| RGCN | ogbn-mag | mini lote | Tiempo de entrenamiento, épocas | 155.321 | 0.515 |
| RGCN | ogbn-mag | gráfico completo | Tiempo de entrenamiento, épocas | 534.192 | 0.472 |
Tenga en cuenta que este proyecto tenía como objetivo mostrar el proceso de experimentación iterativa. El objetivo no era mantener todo constante además del espacio métrico entre la fase uno y la fase dos, así que hicimos ajustes al espacio de sintonización para esta segunda ronda de experimentos. En el gráfico anterior, el resultado de esto es visible en las ejecuciones de mini lotes de RGCN, donde vemos una gran reducción en la varianza entre las ejecuciones después de que redujimos significativamente el dominio de hiperparámetros de búsqueda en función del análisis de la primera fase de los experimentos.
En los resultados, está claro que el optimizador SigOpt está encontrando muchas ejecuciones candidatas que cumplen con nuestros umbrales de rendimiento al tiempo que reduce significativamente la cantidad de tiempo de entrenamiento. Esto no solo es útil para este ciclo de experimentación, sino que es probable que los conocimientos derivados de este trabajo adicional se puedan reutilizar en instancias futuras de flujos de trabajo que involucren trabajos de ajuste similares en GraphSAGE y RGCN que se aplican a productos OGBN y OGBN-mag, respectivamente. En una publicación de seguimiento, veremos la fase tres de este proceso. Seleccionaremos algunas configuraciones de modelos de alta calidad y bajo tiempo de ejecución y veremos cómo el uso de herramientas de interpretabilidad de última generación como GNNExplainer puede facilitar una mayor comprensión de cómo seleccionar los modelos correctos.
Para ver si SigOpt puede generar resultados similares para usted y su equipo, regístrese para usarlo de forma gratuita.
Esta publicación de blog se publicó originalmente en sigopt.com.