
La implementación del sistema de aprendizaje automático en los dominios académico y comercial ha sido acelerada por modelos básicos en los dominios de procesamiento de lenguaje natural y visión por computadora. Los investigadores han sugerido aumentar el recuento de parámetros en órdenes de magnitud para extraer capacidades adicionales de estos modelos y entrenar en vastos corpus de datos. Sus rasgos principales de autorregulación y adaptabilidad permiten desarrollar una amplia gama de aplicaciones para abordar problemas particulares, incluida la producción de texto, el análisis de sentimientos, la segmentación de imágenes y el reconocimiento de imágenes.
Debido a las limitaciones físicas y de energía, el hardware subyacente utilizado para entrenar modelos tan enormes debe escalarse proporcionalmente a los parámetros del modelo. Se han investigado varias técnicas para superar este desafío computacional, incluida la reestructuración de la red, la poda de la red, la cuantificación de la red, la destilación del conocimiento de descomposición de bajo rango, la dispersión del modelo, etc. Se han propuesto diferentes tipos de enfoques dispersos para reducir la intensidad de la computación e imitar las conexiones. entre las neuronas del cerebro humano. La arquitectura de hardware subyacente presenta nuevas dificultades a medida que avanzan los métodos de dispersión y se utiliza ampliamente en aplicaciones de entrenamiento e inferencia.
Un sistema bien equilibrado debe tolerar las fluctuaciones entre la implementación de un modelo que suele ser muy denso desde el punto de vista computacional y la memoria muy escasa. Debido a que hay tantos patrones potenciales y flujos de entrenamiento, los cálculos dispersos requieren la flexibilidad, la capacidad de programación y la eficiencia del hardware de próxima generación en lugar de solo agregar Tera-FLOP y ancho de banda de memoria para satisfacer las demandas computacionales del aprendizaje automático. Una buena implementación de métodos ligeros en una arquitectura amigable puede ayudar de manera efectiva a superar las barreras actuales, como la enorme potencia, los altos costos de las máquinas y los largos tiempos de capacitación.
🚀 Echa un vistazo a las herramientas de IA de 100 en AI Tools Club
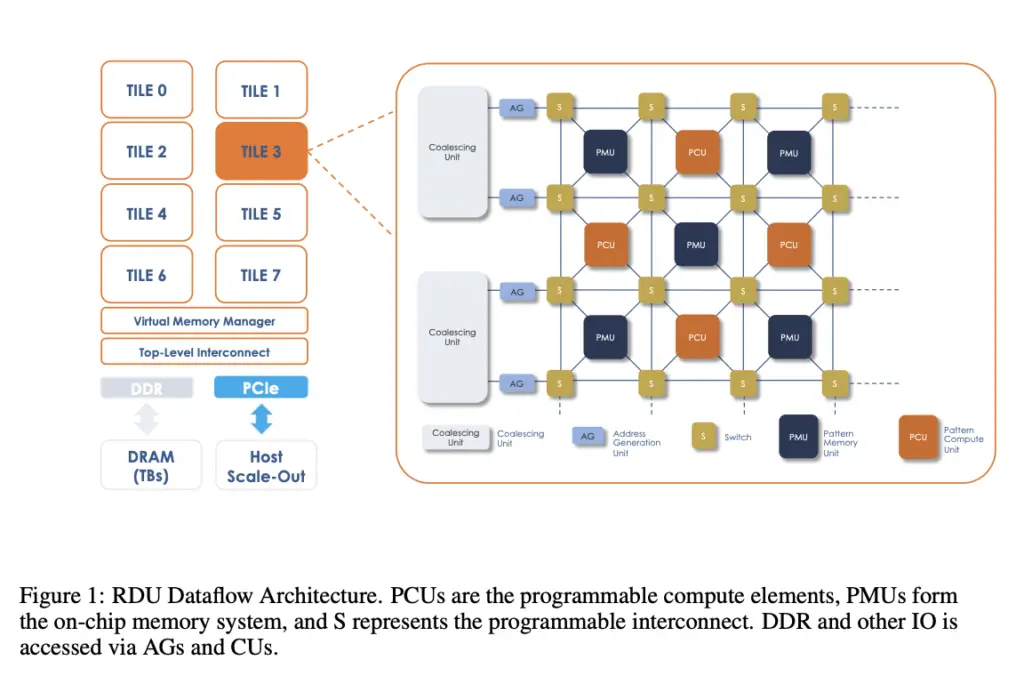
Se han propuesto numerosos marcos computacionales en respuesta al crecimiento del aprendizaje automático y las aplicaciones de inteligencia artificial y sus propiedades inherentes. Además de las arquitecturas convencionales basadas en CPU, algunos ejemplos son Google TPU, NVIDIA A100 Nvidia, Cerebras CS-2, Graphcore IPU y SambaNova RDU. Queda por descubrir toda la extensión de las capacidades de estos sistemas de hardware y software, particularmente en el manejo de un amplio espectro de aplicaciones escasas y densas, a pesar de algunos intentos de evaluar y comparar estos sistemas. Además, muchos de estos marcos siguen siendo de propiedad privada y no son accesibles para la investigación pública en el dominio público. Aunque prometedores, los enfoques escasos tienen dificultades adicionales además de la compatibilidad arquitectónica.
La precisión de un modelo en particular, a diferencia de una línea de base solo densa, depende de una amplia gama de factores, que incluyen la escasez estructurada, semiestructurada y no estructurada, los porcentajes de pesos de escasez/escasez de activación y el programa de entrenamiento. Estos factores de decisión deben determinarse para obtener las métricas más actualizadas en un modelo en particular, lo que requiere tiempo y esfuerzo. Los modelos de lenguaje grande, que pueden adaptarse a una variedad de aplicaciones de lenguaje, son modelos básicos generalizados en el sector de NLP, como el parámetro 13B GPT. Los investigadores de SambaNova Systems en este estudio utilizan este modelo para demostrar cómo la escasez puede incluirse con éxito en un ciclo de entrenamiento de extremo a extremo para lograr métricas de precisión equivalentes.
Contribuyen de las siguientes maneras significativas:
• Un examen completo de cómo interactúan las capacidades de dispersión, fusión y flujo de datos.
• Una demostración de aceleraciones sobre A100 utilizando GPT 13B escaso en SambaNova RDU.
• Análisis de las estadísticas de pérdida, disparo cero y pocos disparos del modelo disperso 13B GPT en comparación con su línea de base densa
El documento en sí tiene más detalles sobre su análisis.
Revisar la Papel. No olvides unirte nuestro SubReddit de 18k+ ML, Canal de discordiay Boletín electrónico, donde compartimos las últimas noticias de investigación de IA, interesantes proyectos de IA y más. Si tiene alguna pregunta sobre el artículo anterior o si nos perdimos algo, no dude en enviarnos un correo electrónico a Asif@marktechpost.com
🚀 Echa un vistazo a las herramientas de IA de 100 en AI Tools Club
Aneesh Tickoo es pasante de consultoría en MarktechPost. Actualmente está cursando su licenciatura en Ciencias de la Información e Inteligencia Artificial en el Instituto Indio de Tecnología (IIT), Bhilai. Pasa la mayor parte de su tiempo trabajando en proyectos destinados a aprovechar el poder del aprendizaje automático. Su interés de investigación es el procesamiento de imágenes y le apasiona crear soluciones a su alrededor. Le encanta conectar con la gente y colaborar en proyectos interesantes.
🚀 ÚNETE a la comunidad subreddit de ML más rápida