

Las incrustaciones de texto son representaciones vectoriales de baja dimensión de textos de longitud arbitraria que desempeñan un papel crucial en las tareas de procesamiento del lenguaje natural, como la recuperación a gran escala. Si bien los enfoques de aprendizaje contrastivos pueden mejorar la calidad de las incrustaciones de texto al mejorar sus representaciones de nivel de secuencia a partir de pares de textos, las incrustaciones resultantes aún luchan por igualar el rendimiento de la popular función de clasificación de referencia BM25 sin más ajustes.
en el nuevo papel Incrustaciones de texto por entrenamiento previo contrastivo débilmente supervisadoun equipo de investigación de Microsoft presenta Embeddings from Bidireccional Encoder Representations (E5), un modelo de incrustación de texto de propósito general para tareas que requieren una representación de texto de un solo vector y el primer modelo que supera la línea de base BM25 en el punto de referencia de recuperación BEIR bajo un cero- ajuste de tiro.
En su primer paso, los investigadores extraen Internet para compilar CCPairs (Colossal Clean Text Pairs), un conjunto de datos de pares de texto enorme, diverso y de alta calidad para entrenar incrustaciones de texto de uso general. Emplean una nueva técnica de filtrado basada en la consistencia para mejorar aún más la calidad de los datos y terminan con ~270 millones de pares de texto para el entrenamiento previo contrastivo.
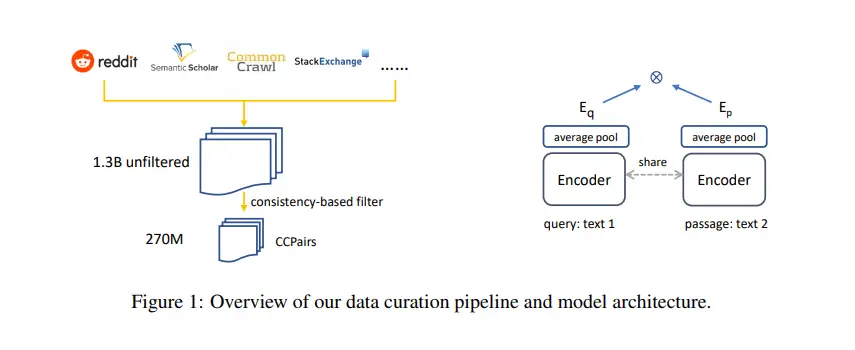
Después de aplicar un entrenamiento previo contrastivo a los CCPairs, el equipo refina aún más las incrustaciones de salida e inyecta conocimiento humano entrenando su modelo en un pequeño conjunto de datos etiquetados de alta calidad compilado a partir de la inferencia de lenguaje natural NLI 6, la clasificación de pasajes MS-MARCO y las preguntas naturales. conjuntos de datos
Las incrustaciones de texto de alta calidad resultantes demuestran una gran capacidad de transferencia en una amplia gama de tareas sin ningún ajuste fino de los parámetros del modelo, lo que valida la idoneidad del enfoque tanto para configuraciones de disparo cero como ajustadas.
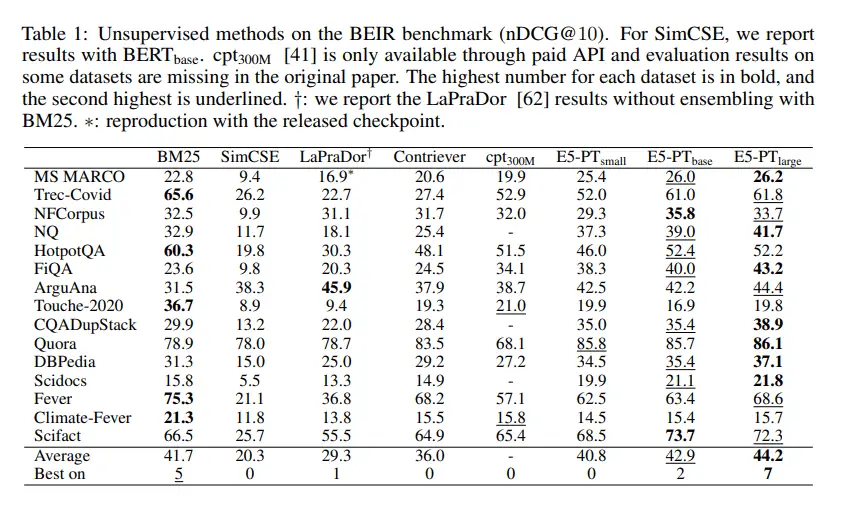

En los experimentos empíricos del equipo, E5 se convirtió en el primer modelo en superar la línea de base fuerte BM25 bajo una configuración de disparo cero en el punto de referencia de recuperación BEIR. En una configuración afinada en el punto de referencia MTEB, E5 superó el modelo de integración de última generación que tiene 40 veces más parámetros.
En general, el estudio muestra que las incrustaciones de texto E5 se pueden entrenar de manera contrastiva solo con pares de texto sin etiquetar, que el enfoque ofrece un rendimiento fuerte y listo para usar en tareas que requieren representaciones de texto de un solo vector, y que produce un rendimiento superior ajustado en tareas aguas abajo.
El código está disponible en el GitHub del proyecto. El papel Incrustaciones de texto por entrenamiento previo contrastivo débilmente supervisado está en arXiv.
Autor: Hécate Él | Editor: Michael Sarazen

Sabemos que no quiere perderse ninguna noticia o avance de investigación. Suscríbete a nuestro popular boletín IA global sincronizada semanalmente para recibir actualizaciones semanales de IA.
Como esto:
Cargando…